
At AMD Financial Analyst Day 2022, the company gave an update on its Xilinx business. We already covered the Zen roadmap in AMD Technology Roadmap from AMD Financial Analyst Day 2022, the EPYC Genoa, Genoa-X, Bergamo, Siena update, and the new MI300 and Pensando update.
This is being done very fast live, so please excuse typos.
AMD-Xilinx Update at AMD Financial Analyst Day 2022
AMD gave an update on the business that previously was Xilinx. Something that Xilinx brings to AMD is a set of customers in the embedded space. Selling a FPGA is a lot different of a sales motion to customers than server or desktop CPUs. Likewise,

On the 7nm Embedded EPYC CPUs, if anyone has these, let us know. We did not hear of AMD launching an update to the EPYC 3000 series. It sounds like AMD will be moving to 5nm next. Xilinx is moving to 3nm after 7nm so that is going to be a few years until we see the next gen after Versal.
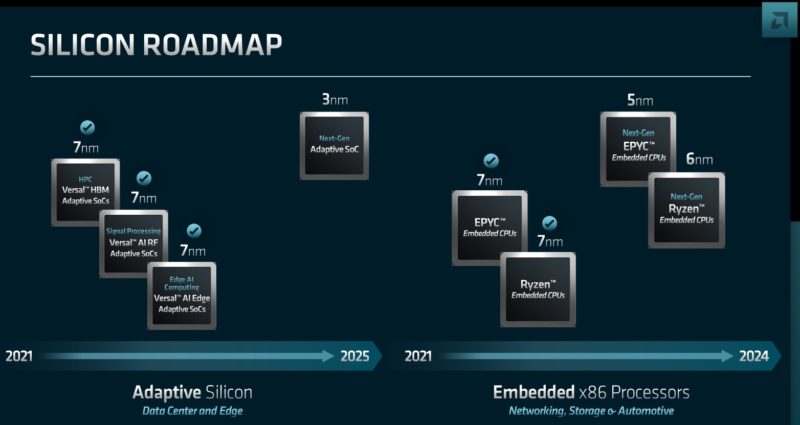
Our best guess, based on the embedded part of the next slide for the EPYC embedded is that this is Rome/ Milan at 7nm based on the package being shown with SP3 keying.

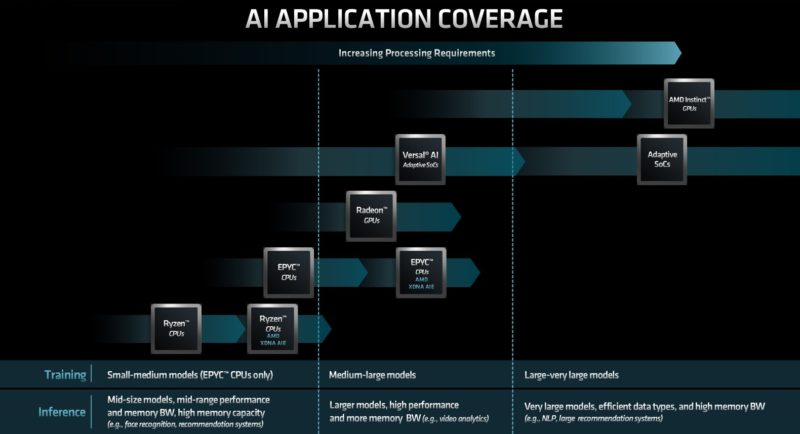
Now the big part, AI. AMD is starting to get serious about AI. We already covered the AMD MI300 APU. AI is going to be a huge edge use case, and that is the market Xilinx was targeting.
Perhaps the biggest announcement today is AMD is making an AI push. First up is the AMD XDNA. Part of this is not just the FPGA, but also the new AI Engine. The AI Engine was part of Versal that are the ACAPs now being rolled out. The AI engines combine local memory with the AI processing engine into tiles that can be scaled.
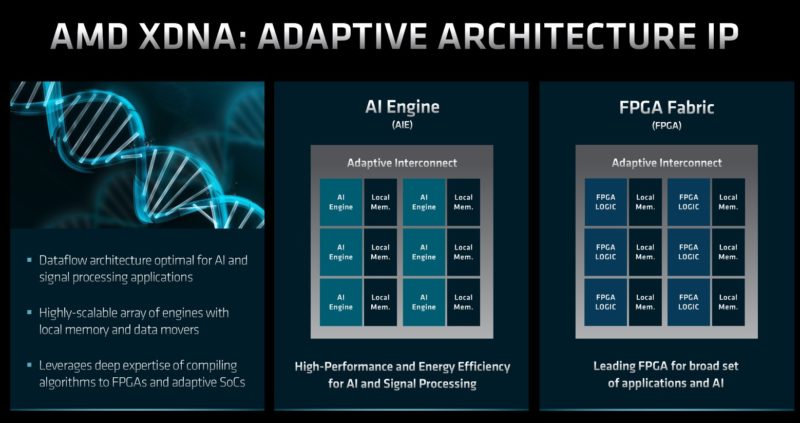
This is AMD’s accelerator block for AI. It also has an adaptable interconnect that can re-configure how the different engines are arranged.
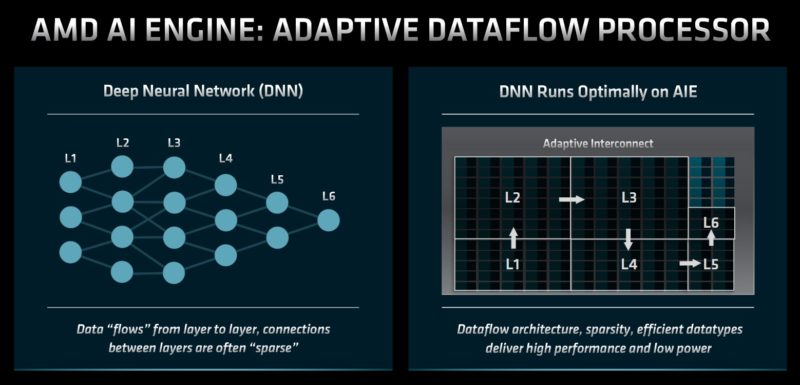
AMD reasons that by adding the AI Engines to CPUs, and with next-generation products, it will have a portfolio from edge AI inference to training.
AMD’s challenge to having a full-stack shown above is that it has silos of software today. NVIDIA’s big win with CUDA is going from small embedded parts like Jetson to the data center GPUs.

AMD is looking to start unifying the AI stack so developers can start to develop once, then work with a number of the company’s products.

That will continue in the future to push further down the stack.

This is in many ways similar to the OneAPI approach where Intel is trying to abstract the hardware from developers so that applications can be written and take advantage of the hardware acceleration across different types of devices. AMD is just starting that journey and that is a good sign.
Final Words
This is a cool strategy, but it also requires that AMD executes well on the software side and folks start to use it. A lot of these markets are Xilinx’s home turf, but in some areas like AI, people think NVIDIA first.
AMD needs an AI story, but its position is that AI is still a newer market so there is still time to catch up here now that it has a broader portfolio.



{kind=link}
Thanks, Patrick. Yes, one stack is key. One stack and the same languages and features on both CDNA and RDNA.
And, not some weasel BS where AMD releases precisely one modest-spec RDNA workstation model that supports HIP, at about 3x the $/FLOP32 of an RX card, and says “SEE!!! YOU CAN TOO DEVELOP ROCm/HIP ON RDNA!!!”
One stack on all RDNA revisions going forward and on CDNA. If AMD does not do this then it may as well take it’s GPUs and go home. You cannot convince mgmt to risk using HIP if the cost of entry is a baseline Mi210 CDNA card with a price tag of thousands of dollars – and the only way to move above above the 210 means going the full OAM Monty. Not when the cost of entry with CUDA is an RTX3050 priced at $300 and it’s PCIe all the way up if you want. It just does not work.
I don’t know about programming FPGAs, but if the same stack can generate binaries that run on them then so much the better.
Well, there’s my rant.
This will probably be more efficient for DSP applications rather than Machine Learning, and it won’t support “Training” as well as it will support “Inference”.
Might as well get a GPU as it will be easier to upgrade, support both training and inference, and have a larger and more efficient software base.
Source: https://www.xilinx.com/products/technology/ai-engine.html
Comments are closed.