AMD EPYC 7F52 Overview
The AMD EPYC 7F52 is AMD’s entrant into the frequency-optimized 16-core CPU market. A great example of software with 16-core license packs is Microsoft Windows Server 2019 Data Center. Here the price of licenses from going to more cores can easily outweigh the delta moving to the higher-frequency parts.

This is a great example of the types of software that drive high-frequency parts and why chip manufacturers can charge more for high-frequency parts. Transitioning from a lower frequency 24-core CPU to a higher-frequency 16-core CPU like the EPYC 7F52 can save $6155 (list price) on licensing costs just at the OS level, and even more for applications. Against this backdrop, the AMD EPYC 7F52 is designed to be optimized for per-core licensing savings.
Key stats for the AMD EPYC 7F52: 16 cores / 32 threads with a 3.5GHz base clock and 3.9GHz turbo boost. There is 256MB of onboard L3 cache. The CPU features a 240W TDP. These are $3100 list price parts.
Here is what the lscpu output looks like for an AMD EPYC 7F52:
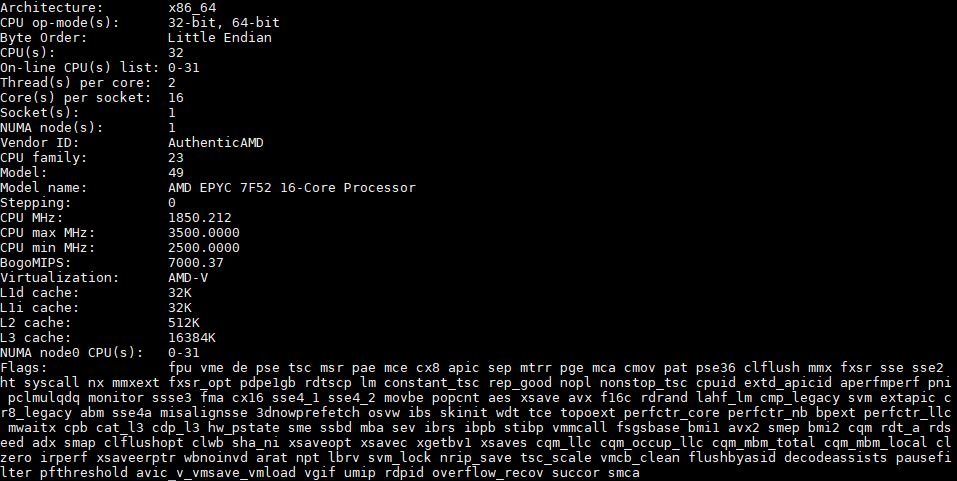
At 3.5-3.9GHz, AMD is effectively holding very high clock speeds by pumping TDP limits to 240W. That is a full 85W or around 55% TDP bump over the AMD EPYC 7302P/ 7302 16-core CPUs.
Here is the topology output:

From a topology perspective, we have a full 8x Zen2 CCD solution with 2 cores active per CCD. That gives us 256MB L3 cache. Here is what the die layout looks like from a conceptual model perspective:

You can learn more about our conceptual model as we first used it to explain AMD EPYC 7002 Rome CPUs optimized for 4-channel memory. AMD now has a low-power/ cost 4-channel optimized EPYC 7282 16-core SKU, a mainstream 8-channel optimized 16-core EPYC 7302 SKU, and the new frequency optimized EPYC 7F52 part.
Overall, this topology gives the chip 16MB of L3 cache per core or 8MB per thread. For some context, the Intel Xeon Gold 6246R is a similarly priced processor with similar clock speeds along with Intel’s top-end 205W TDP. That chip has 35.75MB of L3 cache for only 2.1875MB L3 cache per core. Intel has 1MB of non-inclusive L2 cache per core but that still raises Intel’s total to 3.1875MB L2+L3 cache/ core.
If we take a quick look at a full 28-core die for the 1st and 2nd gen Intel Xeon Scalable chips, this is the diagram Intel provided and we discussed in our Intel Xeon Scalable Processor Family Microarchitecture Overview.
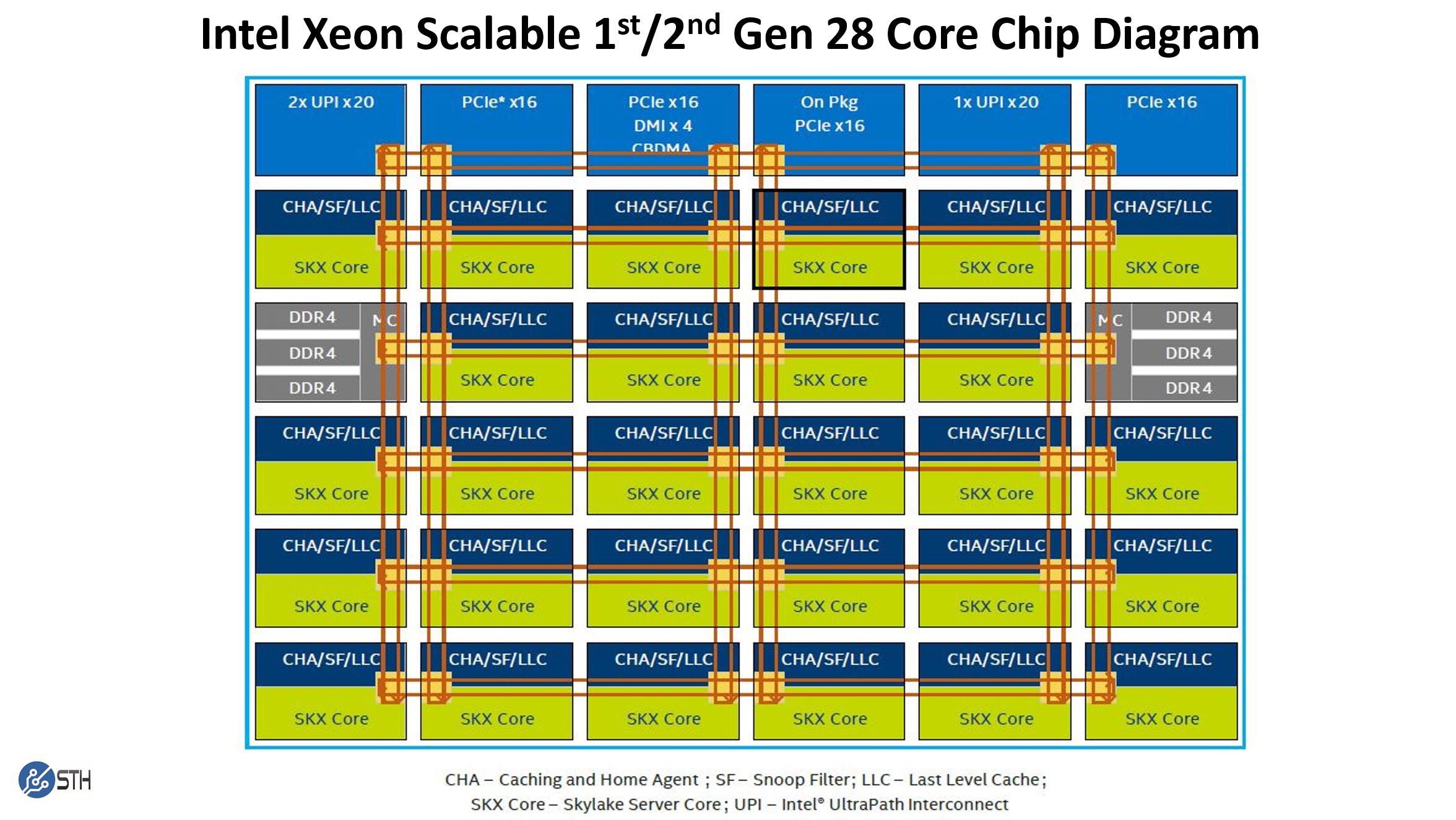
Note these say SKX core. The 2nd gen Intel Xeon Scalable parts would be CLX cores, but we only had the original diagram to work with. If we use a pre-refresh 16-core high-frequency 16 core Xeon Scalable chip such as the Xeon Gold 6242 with 22MB of L3 cache, we get 16 cores x 1.375MB L3 cache segments for 22MB L3 cache. That looks something like this:
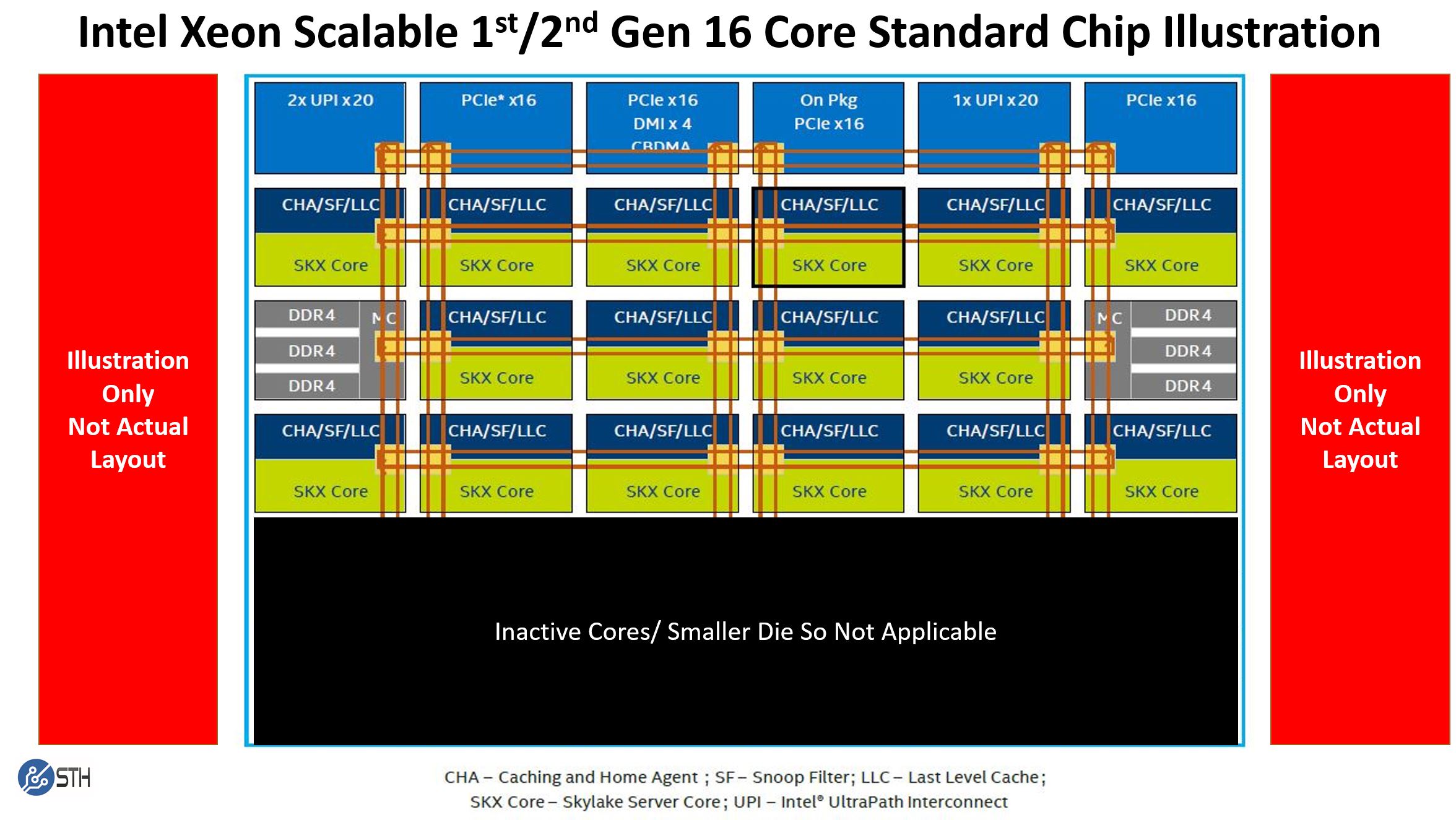
Intel can use a smaller die, or in theory, binned from a larger die because this chip simply requires 16 functioning core/ cache complexes. This is a fairly standard layout that Intel used on many 1st and 2nd generation Intel Xeon Scalable chips.
For chips like the new Intel Xeon Gold 6246R, Intel effectively has a die with 26 of the 28 1.375MB last level (L3) cache segments enabled along with 16 of the 28 possible cores. Intel can bin chips fairly easily to get this combination. This conceptual layout gives us 16 cores with 16MB L2 cache and 22MB of L3 cache local to those cores with an additional 10x 1.375 (13.75MB) on remote hops.
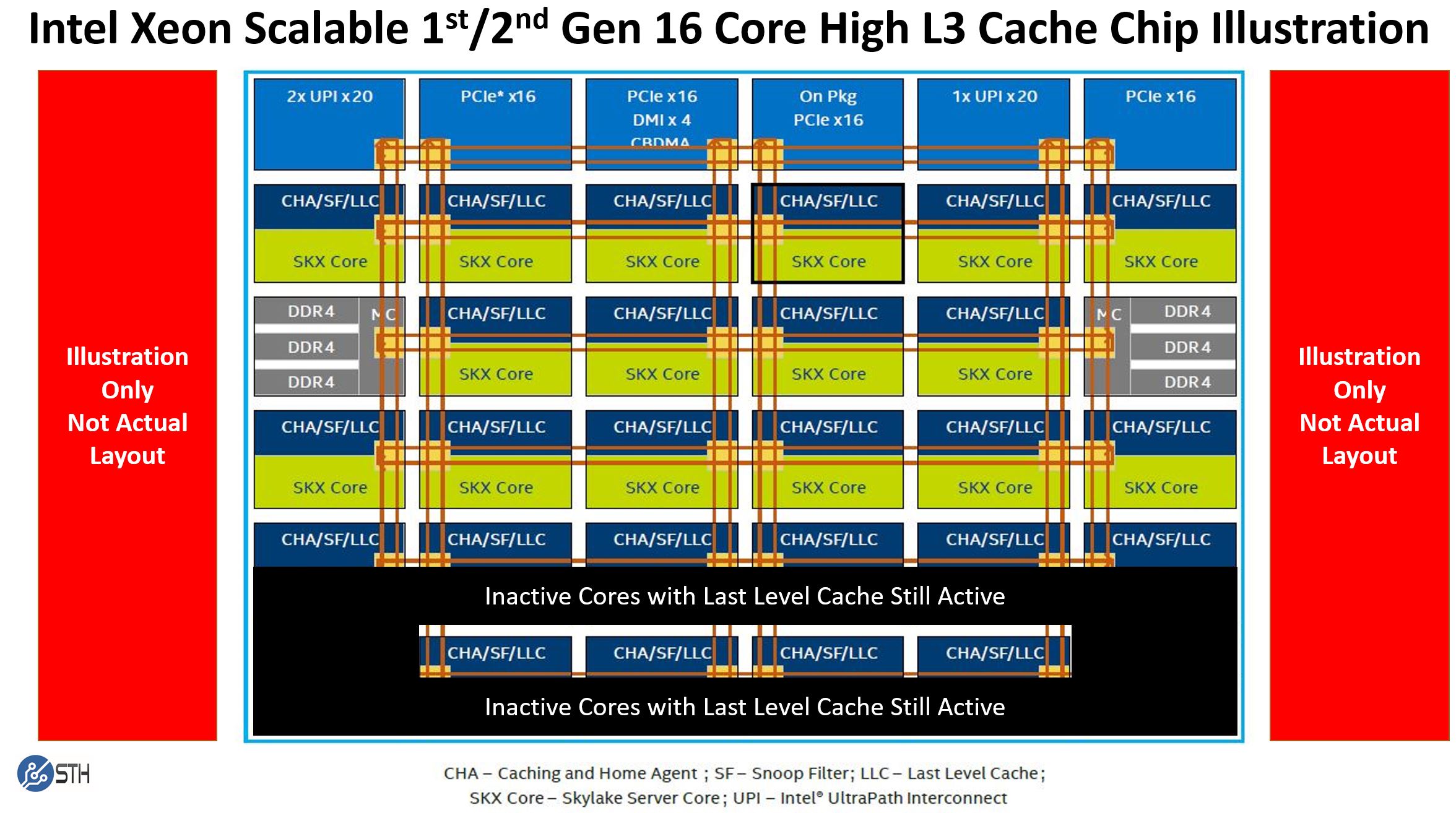
In both the AMD EPYC 7F52 and Intel Xeon Gold 6246R examples, we effectively have L3 cache that would otherwise be used by other cores made available to a fewer number of cores. This allows more data to be cached near the core without having to pull data from off the chip, across the motherboard, and on a DRAM module.
The big difference is in how much cache is local. With the Intel Xeon Gold 6246R, a core has all of this 35.75MB L3 cache plus the 1MB non-inclusive L2 cache available without having to go to memory and all on the same physical piece of silicon. AMD has 32MB available to two cores on the same piece of silicon (plus 512KB of L2 cache per core.) The next step is that there is another 224MB of L3 cache available through on-package I/O die then other CCD hops. Finally, there is another mode which is the I/O Die hop then out to memory. That I/O Die hop and out to memory is a more expensive operation than Intel’s but also benefits from higher clock speeds and more DDR4 channels.

While both chips rely on local caching, AMD sees a larger penalty for a cache miss due to the extra I/O Die hop, but has significantly more cache available per core. That is why in marketing materials you will see Intel typically focus on workloads that do not make the best use of on-chip caches. Previously, Intel could also focus on workloads that were almost solely limited by clock speed, but with the new EPYC 7F52, AMD has effectively closed that gap. Just to put this into a table, here is the most relevant comparison:
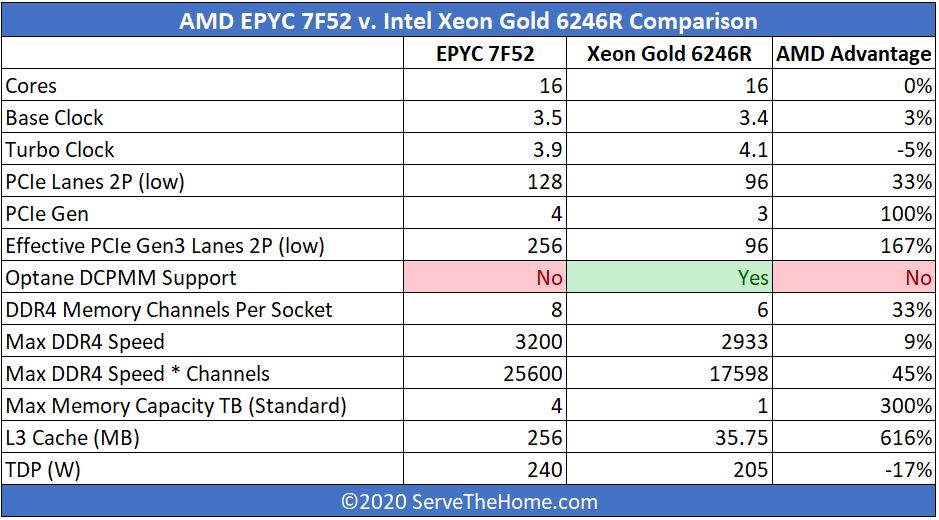
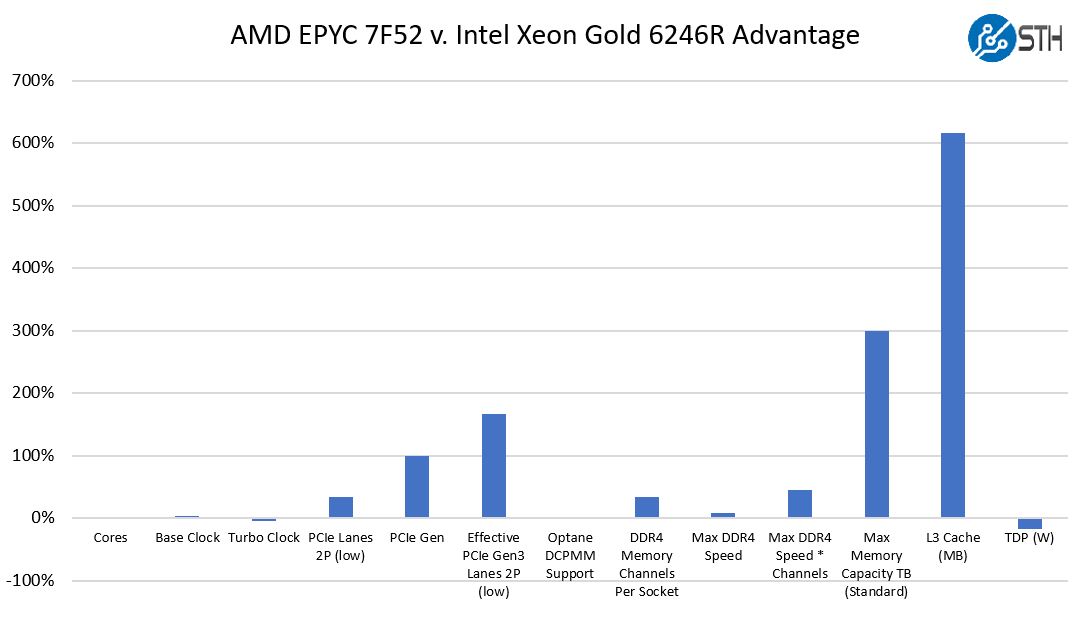
Effectively what AMD is doing with the EPYC 7F52 is stating that it has the platform benefits of more memory (4TB maximum v. 1TB for the Xeon 6246R), PCIe Gen4, and cache even with similar clock speeds and core counts.
AMD is also counting on its large L3 cache to reduce needs to go out to memory. If you look at modern chip design, this is a very common push. Even looking at state-of-the-art AI chips such as the Cerebras Systems design, there is a major push to cache data close to compute cores to increase performance.
While Intel has features such as Optane DCPMM support, that is muted in the “Refresh” SKUs since memory capacities are limited to 1TB. Still, if one wanted to use DCPMM for persistent storage rather than as memory expansion, that is still a benefit AMD does not have.
Overall, this is a huge move for the industry. AMD is becoming very competitive in a segment that it has not really competed in for years. One can see that clearly in pricing as AMD is aiming for effective parity with Intel instead of a discount as we saw with the previous generation.
Next, we are going to look at AMD’s additional systems context around the launch, our test configurations, and how the CPUs arrived. If you just want numbers, we will have our benchmarks next. After that, we will focus on our market impact.



{kind=link}
These are the SKUs that should be thought of as True Workstation class parts and the higher clocks are welcome there along with the memory capacity and the full ECC memory types support.
So what about asking Dell and HP, and AMD, about any potential for that Graphics Workstation market segment on any 1P variants that may appear. I’m hoping that Techgage can get their hands on any 1P variants, or even 2P variants in a single socket compatible Epyc/SP3 Motherboard(With beefed up VRMs) for Graphics workloads testing.
While in the 7F52 each core gets 16MB of L3 cache, that core has only 2048 4k page TLB entries which only cover 8MB. It would be interesting to see how much switching to huge pages improves performance.
I find the 24 core part VERY interesting, just wish they released P versions of the F parts.
Your 16 core intel model is wrong.
16 cores from a 28 core die could still be set up to have the full 28 cores worth of L3 Cache.
Hi Jorgp2 – this was setup to show a conceptual model of the 16-core Gold 6246R which only has 35.75MB L3 cache, not the full 38.5MB possible with a 28 core die
Hi ActuallyWorkstationGrade, if you are going to convince HPE/Dell about 1CPU workstation then IMHO you will have hard fight as those parts are more or less Xeon W-22xx competitive which means if those makers already do have their W-22xx workstation, then Epyc workstation of the same performance will not bring them anything. Compare benchmark results with Xeon W-2295 review here on servethehome and you can see yourself.
Sometimes I read STH for the what. In this “review” the what was nowhere near as interesting as the “why”. You’ve got a great grasp on market dynamics
whats the sustained all core clock speed
I have said it before and this release only highlights the need for it:
You need to add some “few thread benchmarks” to your benchmark suite !
You are only running benchmarks that scale perfectly and horizontally over all cores. This does not massage the turbo modes of the cores nor highlights the advantages of frequency optimized SKUs.
In the real world, most complex environments are built with applications and integrations that absolutely do not scale well horizontally. They are most often limited by the performance and latency of a lot fewer than all cores. Please add some benchmarks that do not use all cores. You can use exisiting software and just limit the amount of threads. 4 – 8 threads would be perfectly realistic.
As you correctly say, the trend with per core licensing will only make this more relevant over time. Best is to start benching as soon as possible so you can build up some comparison data in your database.
Comments are closed.