AIC HA401-TU Block Diagram
The block diagram is important to understanding the server and what is going on. Here we can see how each CPU is wired to the rest of the system and what the layers of stacked PCBs do in the front of each node.
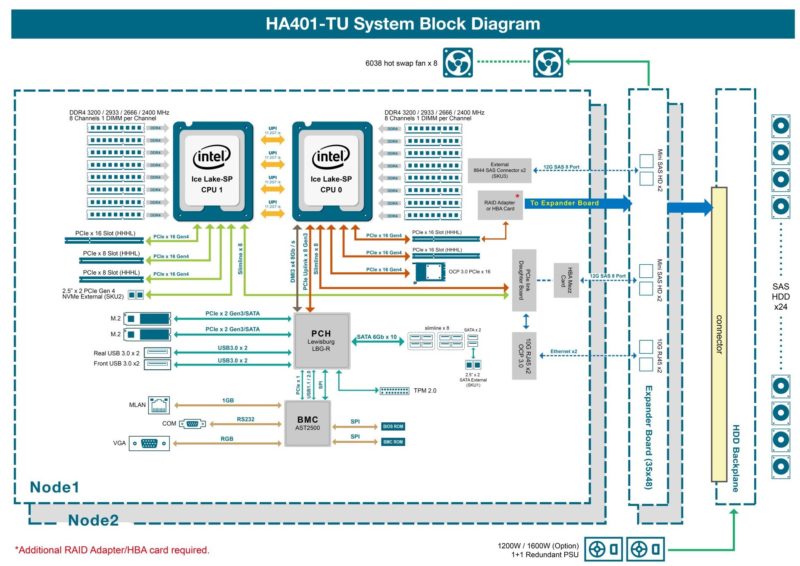
One of the more unique features is that both CPUs feed into the PCIe daughterboard that connects the 10GbE internal NICs and then goes to the expander board.
The diagram also shows a number of options for different SKUs like the NVMe or SATA rear external 2.5″ drive options.
There is a ton here, so if you are interested in this system, it is worth taking a closer look at.
AIC HA401-TU Performance
In terms of performance, we were a bit limited on CPUs. We only had a handful of Intel Xeon Platinum 6330 CPUs on hand. We were slightly concerned they would run too hot in this system, but it seems as though they worked well.
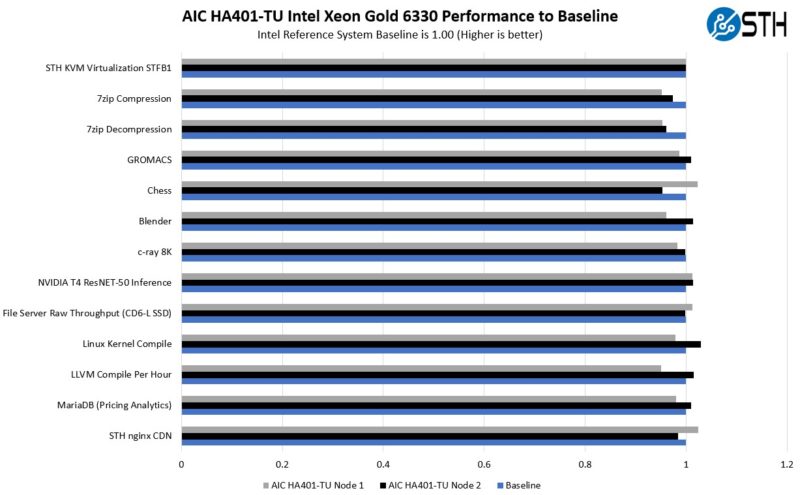
Overall, these are higher-TDP 205W CPUs and we were worried we would get terrible performance, but we did not. Instead, we got fairly close to a standard 2U server like the AIC SB201-TU 2U 24-bay NVMe storage server. Going up to 270W TDP CPUs would probably have been possible, but we did not have a matching set of four available.
Still, for a high-availability storage server, we would generally advise using lower-power processors that better fit this use case.
A Note on High-Availability
Something that we noticed when we were doing this is that we should probably have a high-availability guide for something like ZFS. While there are several commercial storage options out there, it is possible to use components like corosync, pacemaker, pcsd, and multipathd to set up a solution. We actually set this up using a downstream distribution of RHEL, but then while we were working on this review RHEL changed its source distribution policy, so instead, we are going to put it on the list of Debian tutorials we are planning.
We will note here that once we had the ZFS setup up and running, we did try pulling a node and re-inserting it a few mintues later to ensure that the high-availability hot plug functionality worked.
One important note is that this type of hardware is one, or several steps better suited for redundant storage nodes than something like the QNAP GM-1002 3U Dual ZFS NAS we reviewed. That QNAP is two nodes in one chassis each with half of the storage. This is two hot-swap nodes that can both access the SAS drives up front while using standard Broadcom SAS3 controllers and expanders along with having much more expandability. The point of this is really that there are storage vendors producing two-node systems that may look like high-availability systems, but there is actually a lot of work that goes into making them high-availability.
Next, let us get to the power consumption.



{kind=link}
Where do the 2x10GbE ports go? Are those inter-node communication links through the backplane?
Being somewhat naive about high availability servers, I somehow imagine they are designed to continue running in the event of certain hardware faults. Is there anyway to test failover modes in a review like this?
Somehow the “awesome board stack on the front of the node” makes me wonder whether the additional complexity improves or hinders availability.
Are there unexpected single points of failure? How well does the vendor support the software needed for high availability?
Nice to see a new take on a Storage Bridge Bay (SSB). The industri has moved towards software defined storage on isolated serveres. Here the choice is either to have huge failure domains or more servers. Good for sales, bad for costumers.
What we really need is similar NVMe solutions. Especially now, where NVMe is caching up on spinning rust for capacity. CXL might take os there.
Page 2:
In that slow, we have a dual port 10Gbase-T controller.
“slow” should be “slot”.
This reminds me of the Dell VRTX in a good way- those worked great as edge / SMB VMware hosts providing many of the redundancies of a true HA cluster but at a much lower overall platform cost, due to avoiding the cost of iSCSI or FC switching and even more significantly- the SAN vendor premiums for SSD storage.
“What we really need is similar NVMe solutions. Especially now, where NVMe is caching up on spinning rust for capacity. CXL might take os there.”
Totally agree- honestly at this point it seems that a single host with NVMe is sufficient for many organizations needs for remote office / SMB workloads. The biggest pain is OS updates and other planned downtime events. Dual compute modules with access to shared NVMe storage would be a dream solution.
Comments are closed.