
This is one of those announcements that feels a bit strange. Indeed, this is an announcement that we almost did not cover at STH just because it feels premature. The Xilinx Versal AI Edge is being announced well before it is ever fabbed. Indeed, Xilinx may be part of AMD before this chip gets built. Still, we are going to go over Xilinx’s AI Edge solution, but we are going to do so in a different order than a standard story.
Xilinx Versal AI Edge Availability
Let us start with availability because that is perhaps the key to this discussion. This is a product where if it was a human child could be conceived and brought to term, and possibly start sleeping through the night between now and when the evaluation kit is released. Pre-announcing a product is one thing. Pre-announcing a product that is more than a year away is less exciting.

The reason this is important is that Xilinx is using a product that will start to see an evaluation kit in the second half of 2022 and is positioning it against the 1H 2020 NVIDIA Jetson Xavier NX and the 2018 NVIDIA Jetson Xavier. The Jetson Xavier we now have full textile inspection demos being set up in the STH lab as one can see in our Advantech MIC-730AI Review NVIDIA Jetson Xavier AI Edge Appliance.

This is important as well because, in terms of comparisons, Xilinx is making this comparison:

Technically, this is incorrect, because the top line of products does not exist yet. Xilinx is saying that it may (these are forward-looking product projections) have a product line that will cover all of these markets. At the same time, this is also saying that NVIDIA already has several generation-old AI products that have been in the market for years and will likely be replaced before the Versal AI Edge portfolio is available.
Let us be clear that Xilinx is using extremely competitive framing, but if you want to buy and use something today, you should go with NIVIDIA because Xilinx does not have its product available, and it will not be ready any time soon. This struck me because it is a strange marketing message. My only guess is that the reason Xilinx would launch before even tooling is ready is that it does not think it will be competitive with NVIDIA’s next-generation parts so it is trying to paper launch so far in advance.
With that, let us get to the substance of what Xilinx is announcing.
Xilinx Versal AI Edge
This is the summary slide, but one can see that two of the four major points on the slide are addressed in the section above.

Part of Xilinx’s ACAP push is that it has an AI Engines array. Xilinx is recognizing that AI inference is going to be everywhere.
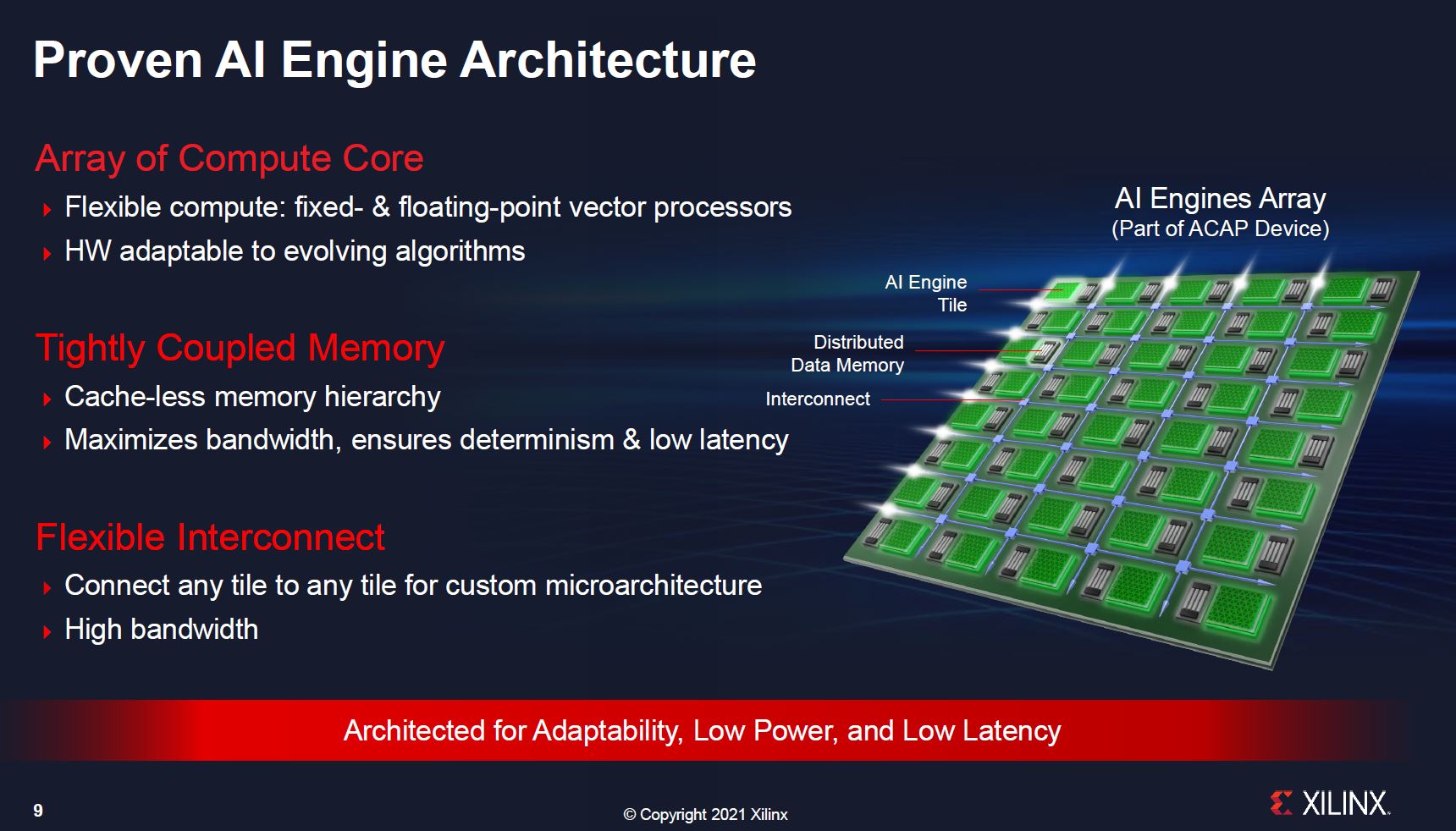
Part of the Versal AI Edge differentiation is that it has more data memory and new memory tiles in the array. Effectively not only does Xilinx have its standard AI accelerator design that looks more like a dedicated accelerator IP, but it also has a higher memory footprint that allows for up to 38MB across the AI Engine array for more weights to be stored locally.

While Xilinx has a standard AI Engine offering for beamforming and radar, this is more for the traditional inference market that has been NVIDIA’s primary market for some time.

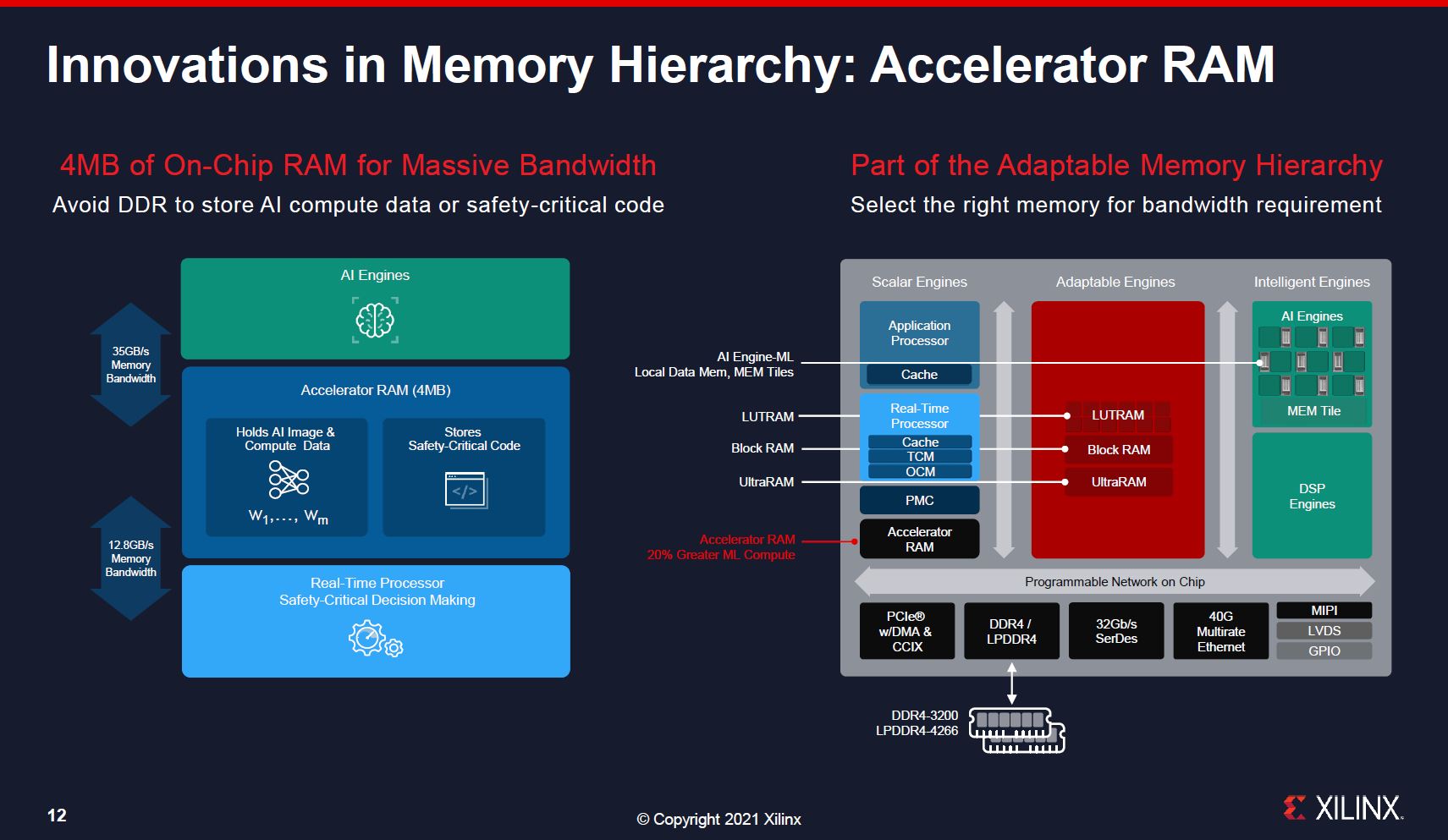
Xilinx also notes that it can have 4MB of on-chip RAM. For some edge AI applications, adding an additional RAM package can be a cost and space adder. Having on-chip memory helps performance while also minimizing packaging constraints. The FPGA has multiple types of memory beyond just the AI engines including in the main FPGA fabric. Xilinx also has a DDR4-3200/ LPDDR4-4266 for external memory.
Xilinx’s 10x compute density claim is centered around how its new single-chip solution can replace three ZYNQ UltraScale+ devices. Note, the ZYNQ UltraScale+ is what we saw in our recent Xilinx Kria KV260 FPGA-based Video AI Development Kit is a Huge Step piece. Xilinx has not announced a SOM based on the Versal AI Edge, but we would expect that in the future if it wants to compete with Jetson.

One interesting point here is that the single Versal AI Edge is a more powerful chip, but it is using about the same power as the three-chip solution. Xilinx is effectively showing a higher power per chip, but with more performance and smaller packaging.
Xilinx Versal AI Edge SKU Stack
Here is the SKU stack. One will notice, for example, that the 4MB of accelerator RAM is only on the smaller half of the SKU stack where it will be more common that the 4MB will make a major difference.
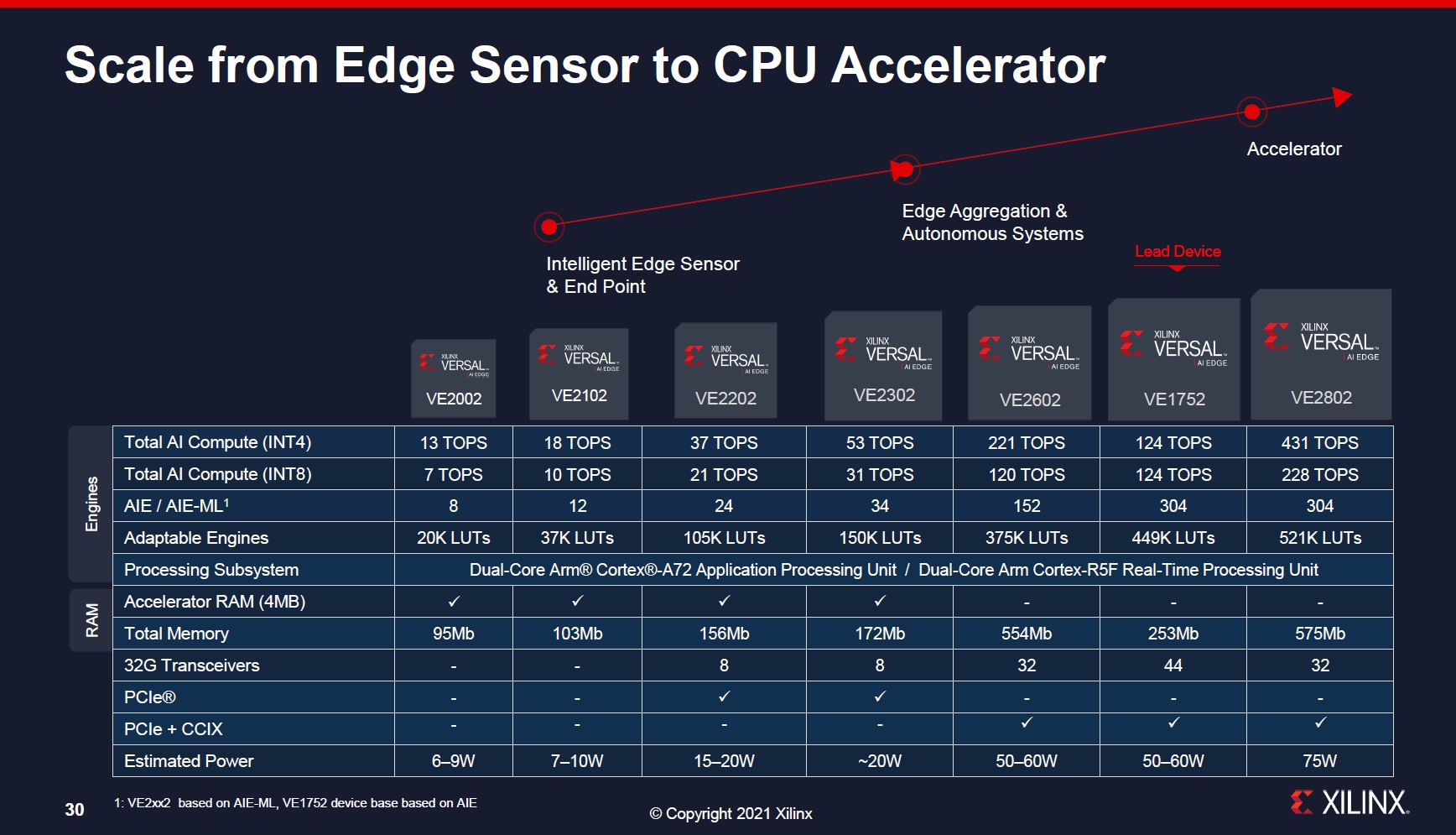
Overall, the key takeaway here is that when these are released, they will range from about 6W to 75W TDP and scale capabilities with the larger chips.
Final Words
We started this piece by highlighting how there was an enormous gap, perhaps half a generation, between announcement and availability. Xilinx says that you can purchase its $11,995 development board now and start prototyping using the Versal AI Core then migrate to its AI Edge product next year. In comparison, the NVIDIA AGX Xavier developer kit is $700 (Amazon Affiliate Link) and there is a history of being able to develop on CUDA and upgrade to new hardware.

For Edge AI, we can see how Xilinx’s solution can be a good one. Xilinx has the ability to build and update custom pipelines for different functions and has hardware AI inference arrays plus on-chip memory close to compute. There are a lot of reasons this can be a good solution, we just wish Xilinx aligned its marketing efforts to the rest of the industry because the current situation is strange.



{kind=link}
What?? Did you just forget your coverage of NVIDIA Bluefield or ARM V1 just a while ago???
I think they called out the V1 and N2 being early. They’ve also clearly got BlueField. If you haven’t seen the STH Instagram posted yesterday it looks like they’ve got a lot https://www.instagram.com/p/CP4nAR_gPkb/
I can’t help but think that in 2035 people will discover more efficient representations for inference such as spiking networks or spare binary representation.
Today people are stuck with models based on integer or floating point vectors because they know how to train that kind of model.
I can see the old school FPGA winning if we get away from numbers.
I am not sure where the hardware bottlenecks really are in the new-school FPGA(s) that pack in lots of ALU.
I know that NVIDIA has done a lot to eliminate the wetware bottlenecks to use their hardware for deep learning. NVIDIA’s developer ergonomics are on a whole other level from AMD, Intel and other vendors that sell very similar hardware that ought to be capable of GPGPU.
Developer ergonomics are notoriously bad for FPGA dev tools and it’s hard to see progress here unless they dump the chessboard over and publish enough info about their hardware that competitive 3rd party dev stacks proliferate.
OK, STH should really learn more about FPGAs/configurable silicon before commenting:
1. ALL major FPGA releases get pre-announced way before they are available. Example: Agilex was announced April 2nd 2019.
2. The reason for these pre-announcements is in the bottom part of the Xilinx press release:
“Versal AI Edge series design documentation and support is available to early access customers”.
(important) Customers can already develop, test and simulate design for these devices with absolute precision even if they are not physically available yet. The only thing missing is the speed grade but they can already simulate for different speed grades.
That’s the beauty of the exact precison of FPGA development. All importent parts like LUTs, multiplicators(DSPs), embedded mems a.s.o. are well defined in their behavior.
Comments are closed.