
Many of STH’s readers, like myself, manage environments for others. A common case I see is where a small business needs a local server deployment to run applications and manage backups. Perhaps this is because that office has limited Internet bandwidth and therefore must have an excellent, but low-cost on-site solution for VMs and basic virtual desktops.
For these businesses, I have a template to set up a relatively inexpensive yet resilient local stack often with SSD primary storage and HDDs for secondary storage. In this article, the goal is to simply and inexpensively achieve as much internal redundancy and backups as possible, allowing for fast recovery from a variety of disaster scenarios.
Hardware Required
Since many small businesses are looking for the lowest costs and to minimize IT footprint, we often get asked to make a solution out of a single, low-power box. The concept for this solution is a single server that contains more than one separate data array.
The most basic form of this would be a system with 4 disks in it, split into two RAID 1 arrays. The primary array would ideally comprise of SSDs, and the secondary array would likely be mechanical disks that are significantly larger (3X+) than the size of the primary array disks. For my example system, this will mean 2x 2TB SSDs for the primary array, and 2x 6TB mechanical HDDs for the secondary array.
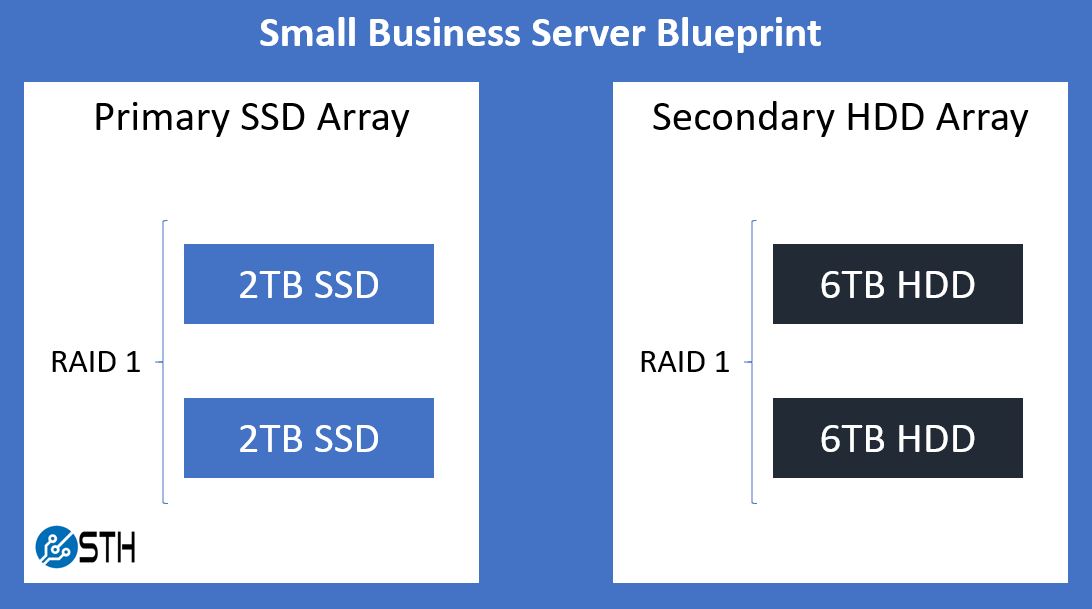
If you need more space, you could expand beyond 4 drives and simple RAID 1 arrays, but your secondary array should be maintained at ~3 times the size of the primary array. Since this solution is built upon VMware’s vSphere Essentials product, you want to make sure your hardware (especially the RAID controller) is on VMware’s hardware compatibility list. Additionally, the hypervisor – VMware ESXi in this case – will boot off its own disk separate from either array; a small thumb drive will easily suffice for this role.
On page 2 of this article, we are going to go into more detail on what hardware we use for small businesses, and why we selected each part. We just wanted to cover the basics here.
Software Required
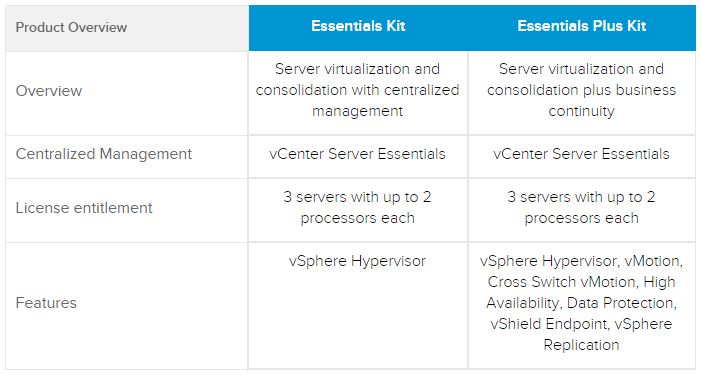
You will need a paid edition of VMware’s vSphere / ESXi product. We know there are open-source alternatives, however, we are sharing a recipe we have used for those that prefer VMware management tools. Assuming you are working with a small deployment, the least expensive option here is the vSphere Essentials bundle at around $580 for 1-year and under $700 for 3-years. This license bundle is a very basic edition of ESXi for up to three hosts.
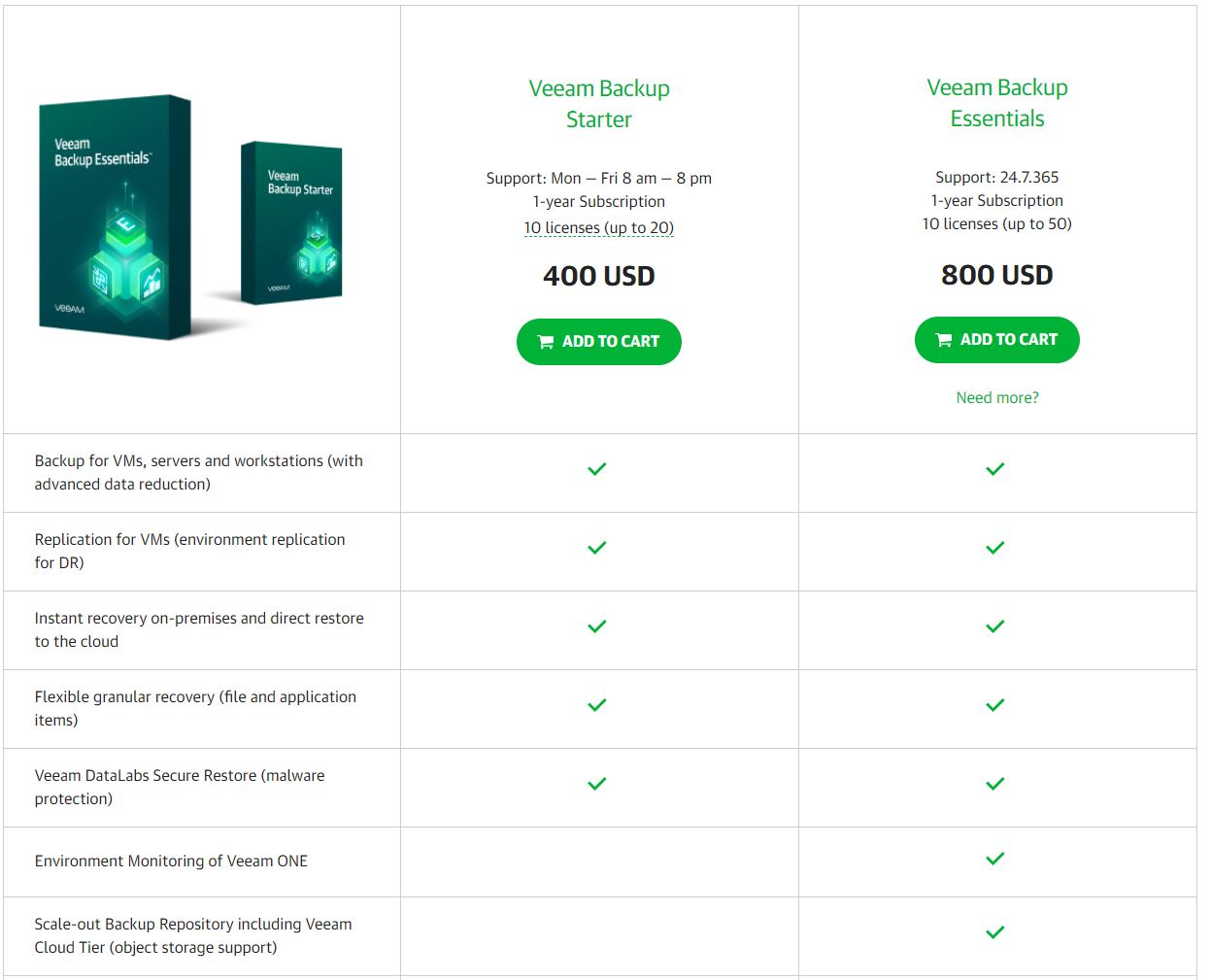
Additionally, the backup product being used here is Veeam. Assuming your environment is small enough (under 10 VMs), the free Veeam Community Edition product will likely cover your needs. If you require paid technical support, then the smallest Veeam bundle is around $400.
Lastly, the Veeam Backup & Replication console requires a Windows OS to run. The console can be installed on both desktop and server editions of Windows. A note here, it is very important that Veeam is installed on its own dedicated system; having Veeam be isolated to its own system is part of the security design of the solution.
One side note, this is not a sponsored article. VMware and Veeam have worked well for me in the past, but they are not the only way to set something like this up.
Small Business Server Solution with Backup DR Capabilities
The first step is to configure the separate arrays. On my example system, I created my two RAID 1 arrays: 2x 2TB SSDs for the primary array, and 2x 6TB mechanical HDDs for the secondary array (diagram above.)
Step two is installing VMware ESXi onto its disk; in my example, that disk is a thumb drive. Keeping ESXi on its own disk will ensure that even if one of the two datastore RAID arrays above fails the system will still boot and the other array will remain visible. Once ESXi is installed, you will want to install your license for it as well.
Once the arrays are built, you need to create and clearly label the VMware datastores on each RAID 1 array. In my case, I chose to simply name one array ssd and the other hdd.
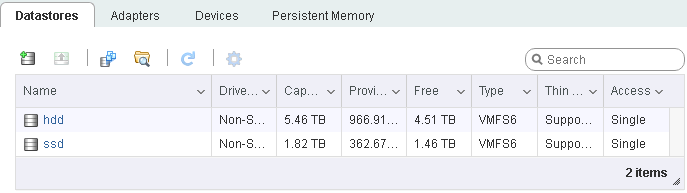
Next, you install your primary VMs. This would be the virtual servers that actually perform the role this physical machine exists to perform. In my environment, this was five VMs – one server and four virtual workstations. I got them all configured and performing their jobs.
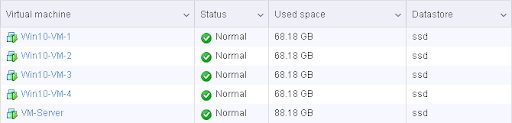
Finally, you need to install the VM where the Veeam console will be located. Critically, you want to install this VM onto the secondary datastore/array. Mine is simply named VEEAM and as you can see, it lives on the hdd datastore.

Once your VM for Veeam is set up and the Veeam Backup & Replication console is installed onto it, it is time to configure the software to perform two tasks: backup & replication.
Backup jobs take all the data on a given VM, bundle it up into a compressed file, and store it somewhere. In my example, this data will be stored directly on the VEEAM system. I have created a backup job for each of the primary VMs and stored the data on the VEEAM system directly. I split up the jobs because I wanted different retention periods for my backups, depending on the VM.
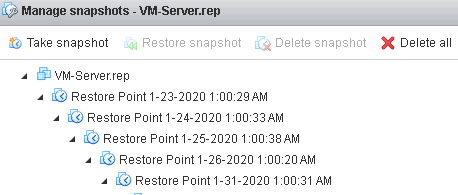
By default, the retention period for these backups is 14 restore points, so if you schedule these backup jobs to run daily then you should be able to go back in time up to 14 days to restore files. Of course, you can adjust this number to your needs when creating the jobs, or perform backups more often than just daily. These backups live as files on the Veeam system’s disk once they are established:
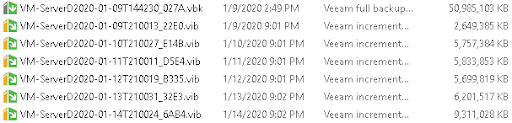
In addition to backups, you also want a Replication job for the primary VMs on the system. In my case, I created a single replication job and selected all five VMs, but individual jobs could also be created. By default, replication jobs keep 7 restore points; these are point-in-time VMware snapshots you can use to boot up the replicated VM as it existed up to 7 days in the past assuming your jobs happen nightly. The destination for each of these replica VMs will be the secondary array/datastore. Once all these replication jobs have run, your ESXi console will contain these:

Some Basic Security Precautions
There are a number of steps you can take to help secure this environment against things like cryptovirus and ransomware attacks. Your primary defense against this is the isolation of the Veeam environment from the rest of the network.
Firstly and most importantly, there should be no shared credentials between any of the primary VMs and the Veeam environment. In my example above, the VEEAM server is not a member of the domain with the other five primary VMs and instead exists separately with its own unique usernames and passwords.
Next, a firewall can be put in place between the two sets of systems, because there is no need for anything in the primary environment to ever directly talk to the Veeam system. This can be a local firewall directly running on the Veeam system – the Windows firewall for example – or you can go as far as completely separating the networks and putting a physical firewall between them. The ESXi management interface can likewise be tucked away on a network isolated from the primary VMs.
Although this is a single physical server due to space, power, and cost constraints, it still is important to segment different portions of the solution as if you had a more robust physical infrastructure.
Reacting to Disaster
Armed with both backups and VM replicas, you should have all the tools necessary to respond to a variety of disaster events.
In the cases where you have lost individual files or folders but the VM systems themselves remain fundamentally intact, you want to utilize your backups. You can log into the Veeam console, mount a point-in-time backup, and restore files from it.
In the cases where entire VMs are corrupted, or perhaps you somehow lost your primary RAID array, the Veeam system should still be available booted up from the secondary array. You can turn on your replica VMs in place, allowing a speedy recovery to operation. You can utilize the revert-to-snapshot function within ESXi if you need to boot up an older iteration of the replica VM.
Restoring to and booting up from one of these replica VMs will operate slower than when things were running on the primary array, but in a disaster scenario walking instead of running is a lot better than being dead in the water.
If you somehow lose the secondary array, that is sad but your production environment is still up and running. You can replace the disks or do whatever you need to do to recover in the background while the primary array is still alive and kicking. This is not a perfect solution, but in a single machine, we have to make some trade-offs.
Uncovered Bases
Depending on your server, you also still have other single points of failure. Generally, though, those points of failure involve downtime without much risk of data loss. As an example, my server has a single power supply and if it fails the environment will go down. Alternatively, the RAID card itself is a single point of failure on the system. However, either of those components can be replaced without the data contained on the server being lost, and so I consider those acceptable risks.
The biggest data backup hole left with a solution like this is that all your data is still centrally located. In the case of a physical disaster like electrical, water, or fire damage, it is still possible both your primary and secondary arrays could be wiped out simultaneously. Your best bet here is to synchronize your backup files offsite or to externally attached storage that you can remove from the building where your server is located. Configuring offsite backups is beyond the scope of this short guide, but it definitely should be considered if the data on your system is critical. In the case of a full network compromise, an offsite or offline backup is often your last remaining line of defense against being forced into a ransom situation.
As a service provider to small businesses, this can be a part of your offering as well.
Final Words
Is this the right solution for you or your clients? Like most technology decisions, that will depend on a number of factors and no guide or article can answer that question on its own. This solution is pretty small-scale and would fit nicely for some small businesses, or perhaps branch offices of slightly larger organizations.
Alternatively, scaling this solution by adding a dedicated backup server into the mix rather than just a secondary data array would solve a number of the single points of failure, at the cost of doubling your physical server hardware purchase. Adding more physical footprint and cost is something we are constantly asked to avoid servicing the SMB sector and edge locations. We look at this more as a bare-minimum to deliver a reasonably safe solution to small businesses that justifies the cost of adding a dedicated server.
On the next page, for those who are interested in a hardware recipe, we are going to share an example server that one can utilize to deliver this solution. Since the hardware landscape changes, we are also going to discuss why many of these components are being used.



{kind=link}
Does it really have to run on windows? Their website suggests that it’s capable of running on Linux under system requirements.
Veeam itself can happily back up Linux or any other OS that can be virtualized under a supported hypervisor, but the Backup & Replication Console itself requires 64-bit Windows. You can find the list of supported OS environments here: https://helpcenter.veeam.com/docs/backup/vsphere/system_requirements.html?ver=100#console
Surprised you didn’t offer the low cost ha of VMware vsan in this build?
Joe, I’m not sure exactly which product you’re referring to. Please feel free to shoot me a link over on the STH forums and I’ll try and evaluate it.
Hello will, not all remote offices have reliable air conditioning, so I would like to know if this setup is OK for occasional peak afternoon ambient temperature of 45 degree Celsius? PS: New Delhi Summer peak. Motherboard spec seems to support Environmental Specifications
Operating Temperature:
0°C to 60°C (32°F to 140°F).
Also any rough what average Total Initial capital cost we are looming at?
Ram, I would guess this particular setup wouldn’t be happy with the 45C ambient, but that’s just a guess as I’ve never attempted to test it. The 8C+ version of the board would likely be more appropriate with its active cooler, but 45C is a really hot ambient environment so not sure how the setup would hold up in general.
At the time of purchase, the server I built here was approximately $2800 USD all-in.
That’s a helpful article WILL/STH. Joe shaw I mean just the license to do that is over 2x what this entire setup costs, it adds more system and switch port needs and the system cost is higher. I don’t really understand why you’re talking vSAN and HA. That’s a completely different price class.
Jed, that’s definitely why I asked for clarification. I am unaware of an ‘affordable’ HA or vSAN bundle; vSphere Essentials Plus – which gets you HA – is $5600 by itself. In addition, last time I used it vSAN was super strict about all your hardware being explicitly on the HCL, and meeting those requirements would definitely increase costs versus the equipment chosen here.
Will/STH, excellent article. I’ve been in your shoes before and have built very similar solutions. In the early days, I used FreeNAS on a VM for the storage with the replication function to sync across to a separate location. Cheap and very reliable, you could technically script some of the automation but overall not the most user friendly solution. Now I’m also using Veeam, both on the same host and also on a separate PC in a different floor/department to have some sort of “off-site” mirror as well.
Nice one, thanks! We do similar setup for our clients, but we are using Windows Hyper-V Server (free) as hypervisor which offers replica as well, or Proxmox which is also loved by STH team, as I can see :)
I have a Micron In-Warranty failure that I have been dealing with for over 2 months now. Micron keeps saying it is the VARs problem to RMA it, even though the drive was purchased 6 months ago, and the VAR says why should it be an RMA since it is more than 30 days since purchase. I personally agree with the VAR that it shouldn’t be an RMA at this point, but Micron is trying to throw this in a circle.
In my case, Samsung issued a RMA and I sent in the drive – a 1.92TB PM863 unit. After weeks of no contact, I called and was told that they couldn’t replace the drive because they had no stock on 1.92TB PM863 drives, and so I would be referred to their refunds department, who would be contacting me. The refunds department has no inbound phone number or email address and has failed to reach out to me for ~3 weeks now.
Great advice, for a small company looking to implement a solution 5 yrs ago!
Marc: If your so gung how to smash up a open, honest and clean review from a trusted resource, then you please feel free to produce a 2020, whatever you consider to be up to date suggestion and review; and like myself, you will have a multitude of users give unsolicited, unwarranted and uninformed comments about the fact buying brand new technology to fit a need is unsustainable from a costing pov; and they are a generation or version back to get started. I appreciate very much the thought and independence and through review STS consistently produces FOR FREE, and multiple ways informs their base these are from their perspective and review purposes only… Your mileage may vary.. but its a guide as to what works for the dialogue…
Will, how much the hardware BOM for the system costed you? Do you have a bill of material and component-wise price break up? It would be great if you can email me the same. Dell has something like PowerEdge T40 (https://www.dell.com/en-in/work/shop/povw/poweredge-t40) and seems like they are much lower in cost.
Hi, you can see page 2 for the BOM. Also, STH will have its T40 review in the next few weeks.
Will,
The cheapest “fault tolerant cluster” we know to be possible is simply to double your hardware and run a single image across two machines with scalemp! We’ve the luxury of a budget for dedicated Stratix gear (NEC re rand) but the same budget let’s us experiment with the wild side and informally and without any warranty of any kind, and ymmverydefinitrlelyvary and our software is all written to be highly resilient in the first place, but assigning hyperv to processor affinity and pulling the cord on one of the two born has been found to lose us no data. But we’re feeding the databases from CICS with a GPS sybcged high resolution time source – that’s for starters. Fault tolerant systems are a way of life not a technical bandaid.
Will,
Dry heat = static discharge and very high mortality rates for any hardware. It pays to maintain humidity the hotter your machine room gets.
Ram Shsnkar,
I think you are in need of a custom cabinet with a heat exchanger and pump for positive atmosphere inside so pushing condensation the outside. The truck Is a large sealed expansion chamber regulated by valves and the air moved by the largest slowest fans possible, placed at the final exit.
Comments are closed.