
When it comes to server and professional workstation graphics, NVIDIA makes some monster GPUs. As one might expect, strange things can happen when you start using these larger memory footprint GPUs such as the NVIDIA GRID K1, K2, M4, M6, M60 and Tesla K10, K20, K20x, K4, K80, Tesla M40 and etc. We had to make some significant BIOS changes to be able to use these cards with Ubuntu 14.04 LTS. Here is how we managed to fit 8 GPUs per blade server which would allow up to 80 GPUs in a 7U rack (10x 8GPU systems.)
The Symptom
We recently added a dozen NVIDIA GRID M40 cards each with 4x GM107L GPUs and 4GB of GDDR5 each for a total of 16GB of onboard memory. We wanted to have the ability to test machine learning algorithms on multi-GPU setups while still using very little power. These are special cards that we obtained but assume they are similar to the NVIDIA GRID K1 however with Maxwell instead of Kepler architecture, lower power, and less GRID driver support for Citrix, VMware and Microsoft VDI applications. You likely will need to be a special NVIDIA customer to be able to get these GPUs as there is very little information online about them.

The Supermicro SuperBlade GPU blades allowed us to add two cards for 8x GPUs in each blade. The GPU SuperBlade chassis supports 10 blades so one can fit a total of 20 GPUs and 20 CPUs across 10 systems. With support for the newest Broadwell-EP processors, each chassis can handle 20 GPU and 440 cores/ 880 threads (using 2x Broadwell-EP Xeon E5-2699 V4 processors.)

With NVIDIA’s quad GPU cards like we are using (and the K1), one can actually test algorithms with 8 GPUs per system in a very low power envelope (e.g. our blades are running at under 500W even with dual E5-2698 V4 chips and the 8x GPUs running at 98% utilization.)

If you install a card into a system running an out of the box Ubuntu 14.04 LTS installation (or other distributions even 16.04 LTS from what we have seen with dailies), you will likely install the card and then try running nvidia-smi, a tool for monitoring the cards. Upon running nvidia-smi you are likely to get a hang in the terminal window you are using:
Another symptom we saw was a PCI Resource Error in the BIOS. Luckily, the PCI Resource Error and nvidia-smi issue we were able to fix with a few BIOS tweaks.
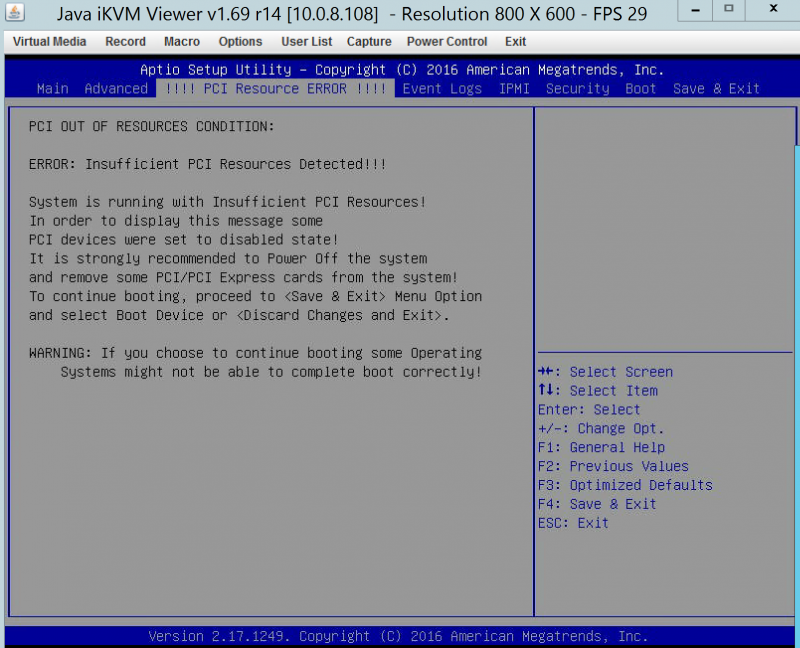
Also, applications like CUDA and NVIDIA cuDNN will not work which can be frustrating if you are using Tensorflow, Theano, Caffee or another machine learning setup. We have a guide on how to fix this.
Supermicro BIOS Changes for GRID/ Tesla
Since we were using various Supermicro GPU SuperBlade server nodes for our testing, we are showing BIOS changes for this. From what we understand, some server vendors have similar options that are less obvious. For example, HPE servers may have a hidden menu that you can hit Ctrl-a into to get to the relevant menu to change 64-bit PCI support. The Supermicro GPU SuperBlades we are using have these menu options easily visible, but you do need to know how to set them.
The first screen we want to access is: Advanced->PCIe/PCI/PnP configuration
There are three key settings you want to set:
- Above 4G Decoding = Enabled (should be default)
- MMIOH Base = 256G
- MMIO High Size = 128G
Here is what the screen should look like when you are done if you have a single 4 GPU card:
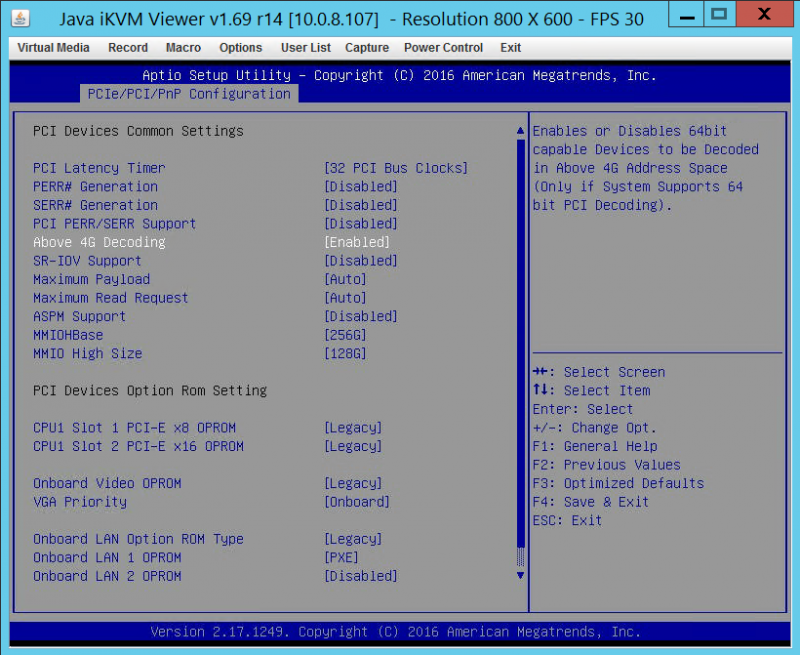
These setting are important to get the setup working.
Moving to two cards and a toal of 8 GPUs here are the settings we used:
- Above 4G Decoding = Enabled (should be default)
- MMIOH Base = 512G
- MMIO High Size = 256G
Here is what these settings looked like with two 4 GPU cards for a total of 8 GPUs in each Supermicro GPU SuperBlade:
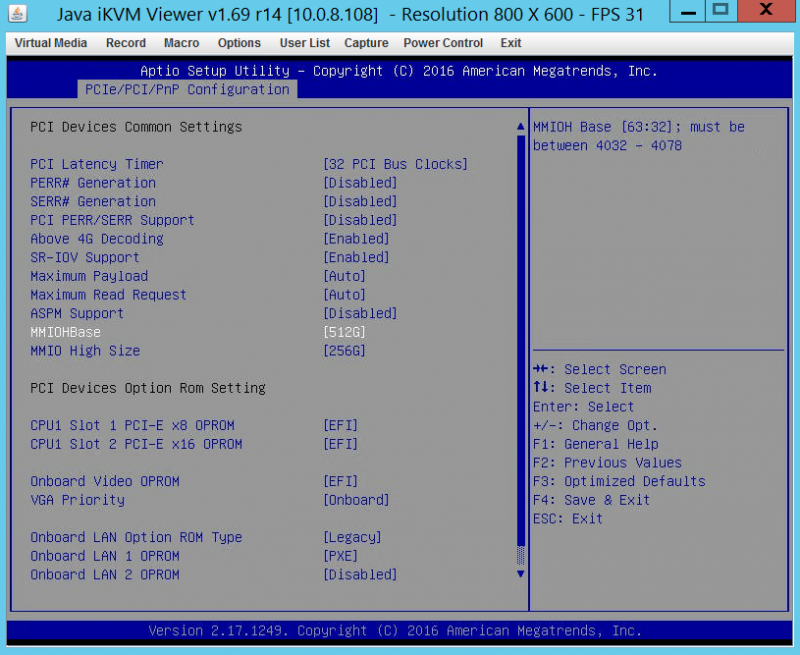
The big change here was the MMIOHBase and MMIO High Size changes to 512G and 256G respectively from 256GB and 128GB. Once we had those updated, the other step was fully diving into UEFI. Everything we tried with Legacy boot mode on Supermicro and a few other servers just refused to accept this many GPUs.
You will also note in the pictures above we changed the onboard Video OPROM to EFI. We did this so we could turn off CSM mode.
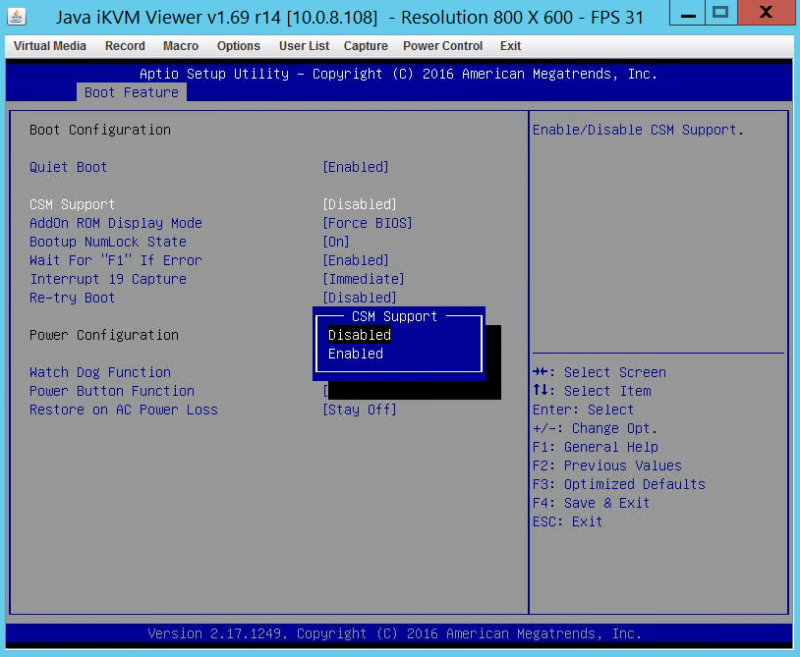
We also had to change from dual (Legacy and UEFI) mode to pure UEFI. Our advice here is to transition to UEFI across the board.
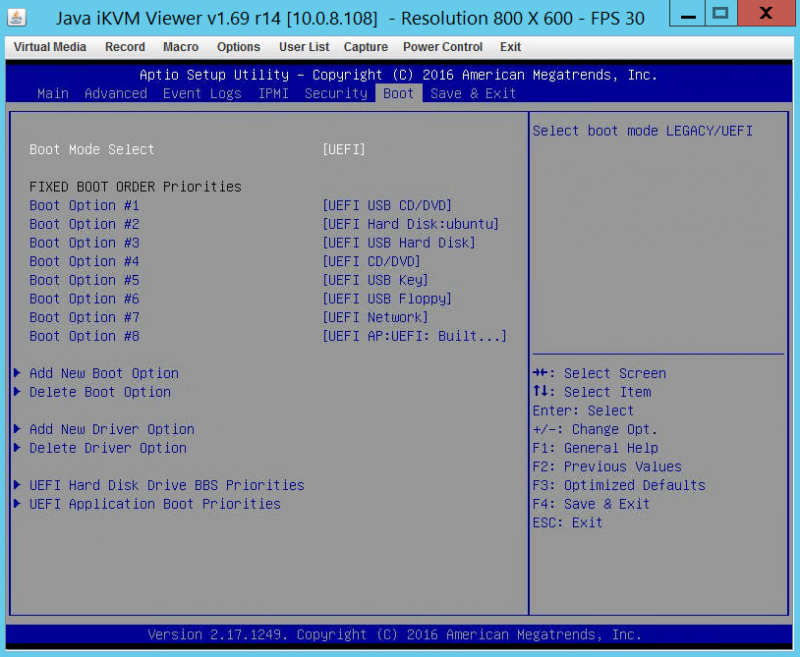
We have seen some vendors struggle supporting 8x GPUs in a single system but the above settings will even get the dense blades to operate with this high number of GPUs. Installation of two GPUs in the Supermicro SuperBlade GPU nodes requires removing about 12 screws. After we did the first blade, our subsequent GPU blade updates took in the 5-7 minute range using a manual screwdriver. We were able to change BIOS settings before or after installation which is nice since one 8x PCIe x16 slot system we tested from another vendor would not POST and get into BIOS with the cards installed (requiring a return trip to the data center.) We would suggest ensuring you can boot before leaving the data center but with the SuperBlade GPU nodes this was not an issue.
From here you can boot into Ubuntu 14.04 LTS as normal. If you are using NVIDIA GPUs with Tensorflow, as an example, you can download the NVIDIA CUDA 7.0. deb and run:
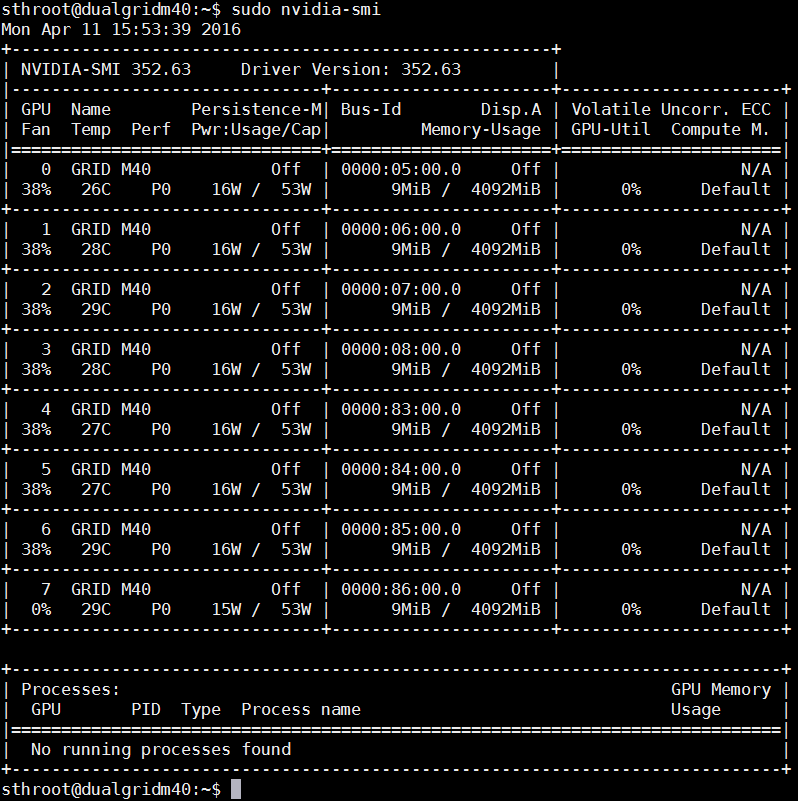
sudo nvidia-smi
As a hint here, in most settings we have found sudo to be important. Here is the nvidia-smi output with our 8x NVIDIA GPUs in the Supermicro SuperBlade GPU node:
If you are still having issues, we have had a few machines where we needed to make a file called /etc/udev/rules.d/90-modprobe.rules (use sudo nano to make it) and add:
/etc/udev/rules.d/90-modprobe.rules
We could then run:
sudo update-initramfs -u
And everything worked for us after we made that update.
Final thoughts
When it comes to building machine learning systems, most of the big GPU compute shops we have seen are using 8x big GPU nodes. These machines can take upwards of 2.6kW each and cost a ton to setup. The two cards with 4 GPUs each solution was excellent as it allows us to simulate an algorithm on eight GPUs in a single system before scaling it up. Likewise, in the blade chassis we can have a single 7U box with networking built-in, that can simulate a small scale 80 GPU cluster (or 20/40 GPUs in officially supported configurations.) While scaling up to larger GPUs would certainly be (much) better we have seen this architecture work at clients that are looking for lower cost alternatives to buying large new machine. Setting this all up was far from easy, but luckily with multiple blades at our disposal our rate of trial and error was awesome. You should, of course, consult your system manufacturer, however this will hopefully help folks on their path of troubleshooting nvidia-smi issues.
More information and where to get cards we used
You can find more information about these cards on STH in a number of places:
- Our NVIDIA GRID M40 introductory piece (coming soon)
- Our official NVIDIA GRID M40 Forum Thread
These are very hard cards to get. The easiest place right now is on ebay. Here is a GRID M40 ebay search.



{kind=link}
I’m trying to figure out he settings for 3x 1080s. For a supermicro X10dac mother board. Think you guys can help me? I’m having issues installing 3
Perhaps post on our forums https://forums.servethehome.com/
We have a lot of folks running multiple GPUs there.
What to do if there is no MMIOHBase and MMIO High Size setting in the BIOS.
If I install Above 4G Decoding = Enabled, I get an error in esxi 6.0 u3: “ALERT: NVIDIA: module load failed during VIB install / upgrade.”
And if I put Above 4G Decoding = Disable, then in esxi 6.0, the nvidia-smi command shows only one core of four.
Supermicro X9DRi-LN4F + motherboard and nvidia tesla m10 card
Comments are closed.