
This week for SC22, we have a fun treat. We jumpped on a NVIDIA H100 80GB PCIe GPU. This was still in an Ice Lake Intel Xeon server, but we had a few minutes, and just wanted to poke around. While this was happening, Moritz Lehmann who has an OpenCL CFD application expressed interest, and we ran his CFD codes to see how they compared to the previous version.
NVIDIA H100 80GB PCIe Hands on CFD Simulation
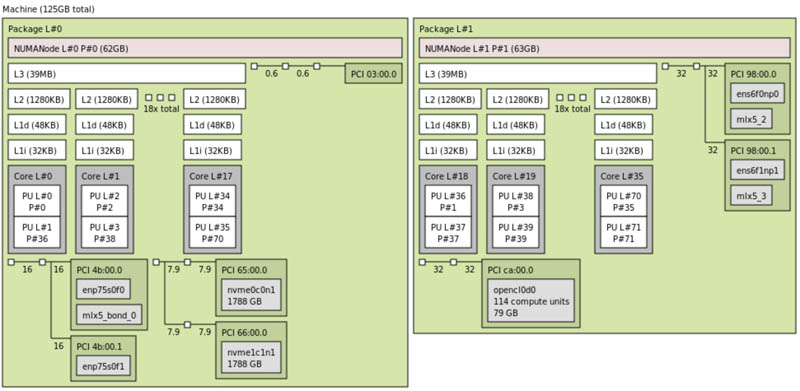
First off, we have the test system. Here is the system with the OpenCL devices with 114 compute units and 80GB of memory on NUMA Node L1:
Here is the nvidia-smi output of the card:
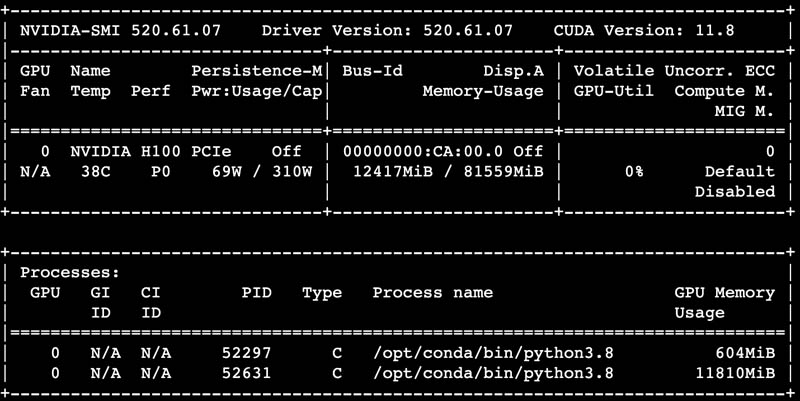
As for power consumption, we saw 68-70W as fairly normal. The 310W maximum power consumption seemed a bit high, but we did manage to hit that figure on some AI workloads.
Still, we wanted to highlight Moritz’s work. Here are the NVIDIA H100 80GB results among his other benchmark results:
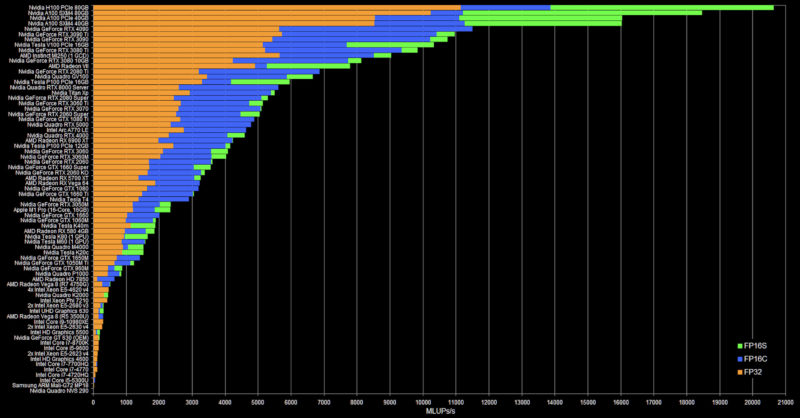
You may need to get to a larger version of the chart above, but the H100 80GB PCIe is now top on this chart. It is followed by the A100 SXM 80GB, then the PCIe A100, then the 40GB SXM A100. In any case, this is a significant improvement.
Here is the description of what you are seeing above from Mortiz:
The 3 numbers all are Mega Lattice UPdates per second, or how many million grid points are computed per second. FluidX3D is a lattice Boltzmann method (LBM) fluid solver that computes density and velocity for all points on a cubic grid in every time step. LBM works by copying density distribution functions (DDFs, these are just floating-point numbers) around in memory, and is entirely bandwidth-bound. FluidX3D does all arithmetic in FP32, but has 3 levels of precision for this memory access:
- FP32: Standard FP32
- FP16S: IEEE-754 FP16 with a scaling factor before/after conversion; the conversion is supported in hardware
- FP16C: a custom 16-bit floating-point format with only 4-bit exponent and more accurate 11-bit mantissa. This is a bit more accurate than FP16S in some cases. The conversion is done manually with heavy integer arithmetic and takes ~51 instructions. Since LBM is bandwidth-bound, compressing the DDFs from FP32 to either FP16 format doubles performance. FP16C is heavy on int arithmetic and thus usually not as fast. In most cases, the compression does not affect accuracy at all.
If you want to see the types of simulations this OpenCL lattice Boltzmann CFD software does, you can see an example here with the Space Shuttle simulation:
For some data points, the power consumption for the above:
- FP32: 217W
- FP16S: 257W
- FP16C: 277W
With that, the efficiency was:
- FP32: 51.3MLUP/W
- FP16S: 74.5MLUP/W
- FP16C: 53.9MLUP/W
If you want to learn more about FluidX3D, Github is a great place to start.
Final Words
We are in an extremely busy period with SC22, the recent Genoa launch, aiming to show new DPUs and CXL in December, the US holiday season, and the upcoming Sapphire Rapids Xeon launch. Still, we wanted to highlight a cool project and get them some data on a new card while also showing our readers the jump from A100 to H100 performance. Also, interesting on this is that the H100 is roughly double the performance of Moritz’s single GCD MI250 runs.


{kind=link}
The H100 PCIe uses only HBM2e and has only 2TB/s of memory bandwidth. The SXM4 version uses HBM3 and offers 3.5TB/s of memory bandwith. So in this particular bandwidth-bound benchmark, we are not seeing much of an improvement over the A100 since the A100 already offers 1.5TB/s of memory bandwith. Testing the H100 SXM4 in this particular bandwidth-bound scenario would probably be showing a much more significant improvement over the A100.
I think this should be added to the article.
Best regards
@Francois Cattelain
While you are correct in your comment, there are some mistakes here and there. First off, H100 comes in the new SXM5 format, not SXM4. Second, it is indeed a big difference in memory type used in the PCIe version of the H100 and the SXM5 version, but the actual figure is lower than 3.5TB/s for the SXM5 HBM3 H100…it’s actually 3.35TB/s.
@Andrei
Thanks for the corrections! You are right of course.
I guess two people are always more knowledgeable than one.
Are you @andreif7?
If so, that’s an honor, cf the 2 years old piece on STH about an Arm opportunity with CSP.
Twitter DM a possibility to continue this conversation if need arises.
Thanks again, I appreciate it.
Am I the only one who is disturbed by testing a brand new card with a model of the space shuttle which stopped flying in 2011? (1) Must be my age remembering the first HP inkjet printers with publicity featuring printouts of a space shuttle model…
(1) https://en.wikipedia.org/wiki/Space_Shuttle
Comments are closed.