
Today we have the NVIDIA GTC 2022 Fall keynote. This is one that we have been anticipating for some time. We had a preview of some of the news over the past few days, but we are going to be covering the announcements live. We will also break out a few key announcements in separate pieces over the next few days.
Note: This is being done live. So please excuse typos.
NVIDIA GTC 2022 Fall Keynote Coverage
In this edition, we expect new GPUs and new applications in RTX, AI, and Omniverse. We should have new chips and new cloud services.
NVIDIA RTX 4000 Ada Lovelace
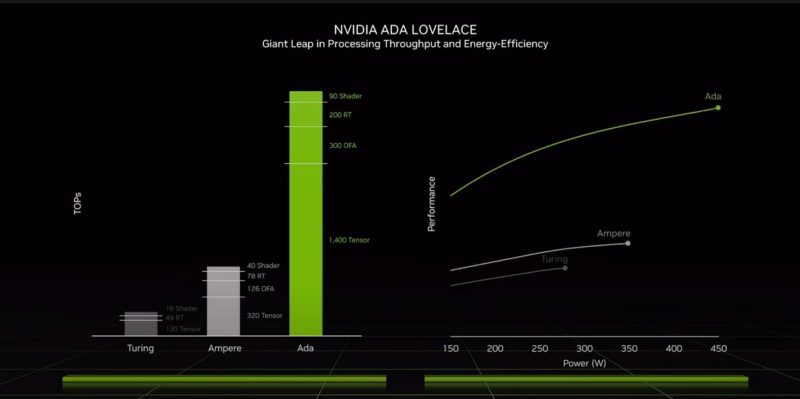
NVIDIA Ada Lovelace is the 3rd generation RTX platform. The new GPU is built on TSMC 4N 76B and 18000 CUDA cores 70% more than the RTX 3000 generation.

The new shaders are capable of up to 90 TFLOPS. A new streaming processor has shader execution reordering (SER) that NVIDIA likens to out-of-order execution for CPUs.
The new 3rd generation RT cores are faster with 200 RT TFLOPS. There is also the 4th generation tensor cores with up to 1400 Tensor TFLOPS and the optical flow accelerator to help smooth framerates.
NVIDIA also has a number of inventions to help make ray tracing more mainstream.
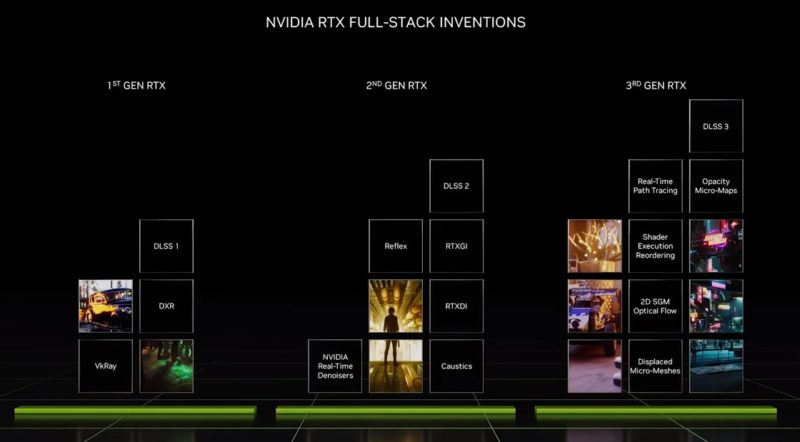
With DLSS 3, more can be done without using the main GPU rendering or even CPU pipelines.
Something that NVIDIA is pushing these days is Omniverse. It has found a clever way to onboard folks to the platform. It has RTX Remix that allows you to load a game, capture the game in USD, then in Omniverse, the RTX Remix toolset can upres textures and help modders create materials through AI.

One can then export the mod and play it. This is really smart since it is a gateway to get developers and artists on Omniverse.
Here is the performance areas that NVIDIA expects gains and power consumption.
Now it is time for the GPUs.

Here is the GeForce RTX 4090:

It looks like we do not get more memory in this generation.
Here is the GeForce RTX 4080:

Since NVIDIA is starting the refresh with the higher-end, here is the new GeForce RTX stack:

After this announcement, NVIDIA showed more Omniverse. That is a big theme for the company moving forward.
NVIDIA Omniverse
NVIDIA Omniverse is the company’s platform for digital worlds that it hopes will span everything from digital twins, to gaming, to simulations, and more.
During the keynote, it announced new features for the platform, including support for Ada Lovelace GPUs.

Eventually, Omniverse needs a cloud component for collaboration.

There we go.

This is the first of many cloud announcements that NVIDIA will be making today and in the future.
NVIDIA Drive Update with Thor
Previously, NVIDIA had Atlan scheduled for 2024.
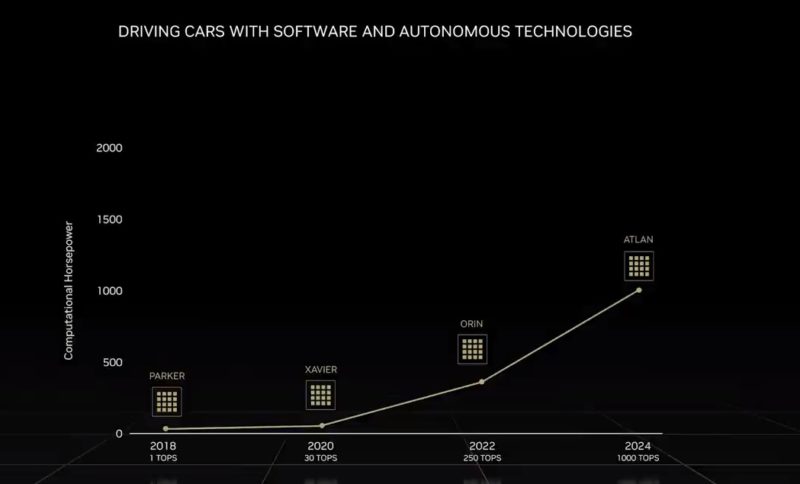
Now it has Thor, at twice the performance of Atlan for the same time frame.
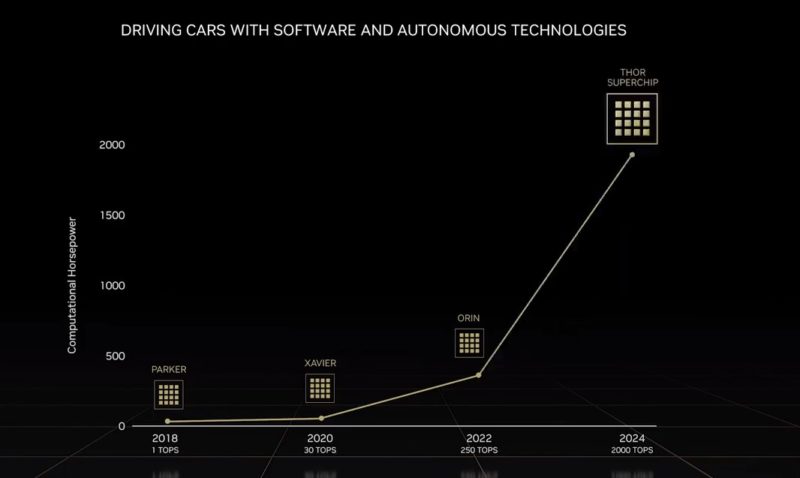
This will bring next-generation GPU, plus the new Grace Neoverse V2-powered cores, onto the next-generation robotics platform, past Orin, which is today’s platform.

Part of the idea here is that the new platform can be used to power infotainment as well as driving assist features. It also has multi-domain computing so it can run Linux, QNX, and Android, as examples, at the same time.
Today, there are many different computers in cars.

In the future, NVIDIA thinks that Thor can replace many if not all of them. That means lower power consumption and also lower weight/ packaging requirements for the computers as well as wiring.

NVIDIA says that the NVLink C2C was to help have multiple Thor chips connected for applications where more processing power is required.
NVIDIA said its current generation NVIDIA Drive Orin has over 40 design wins at this point.

Orin is in the Metropolis Edge AI Orin Server.

It is also at the heart of the NVIDIA IGX Orin. This is a mATX platform that combines two ConnectX-7 ports (400Gbps) and will be used in a number of new applications, including healthcare.

This IGX Orin is perhaps the most exciting platform at GTC 2022 aside from the RTX 4000 series.
NVIDIA Isaac simulation for robotics is available as a cloud service as well.
NVIDIA Accelerated Computing Across the Datacenter Stack
This is the set up slide for the next section.
NVIDIA RAPIDS can be used on Windows WSL. It also supports Arm servers. The company says RAPIDS is also coming to Apache Spark.
The NVIDIA Triton inference server is expanding with 50 new features. That includes large language model inference.
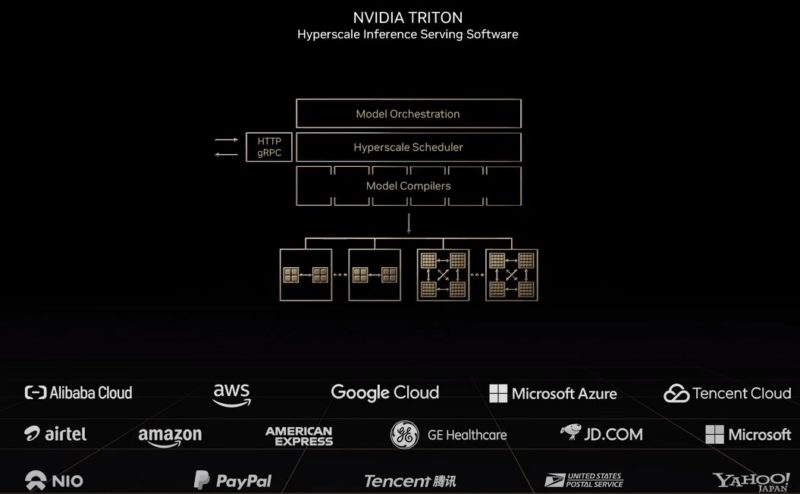
NVIDIA is going through software, and companies using NVIDIA’s software. We are going to skip these segments.
One of the bigger announcements is tied to large language models as they grow in complexity and scale.

NVIDIA is going to offer a service where it can take large language models and customize them given as few as 500 input pairs.
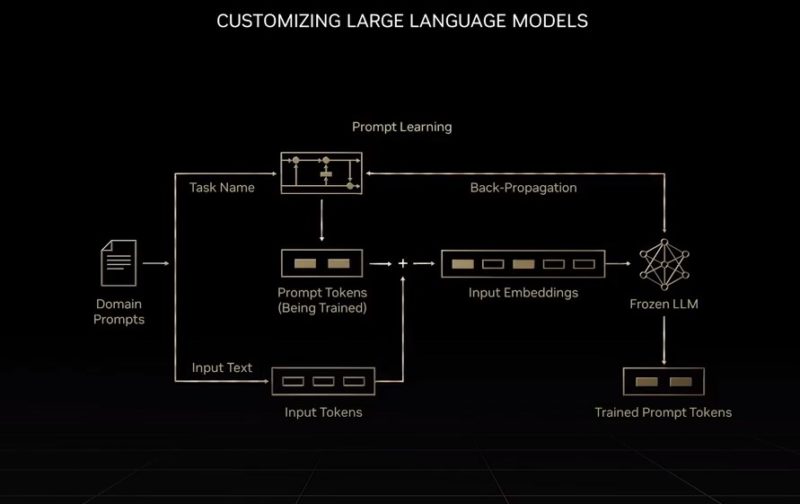
It will then offer the output as an API service. The advantage for a company is that they can train models without having big GPU clusters. For NVIDIA, this can be an extremely high-margin business as customers rely on it to host AI models at the heart of business functions.
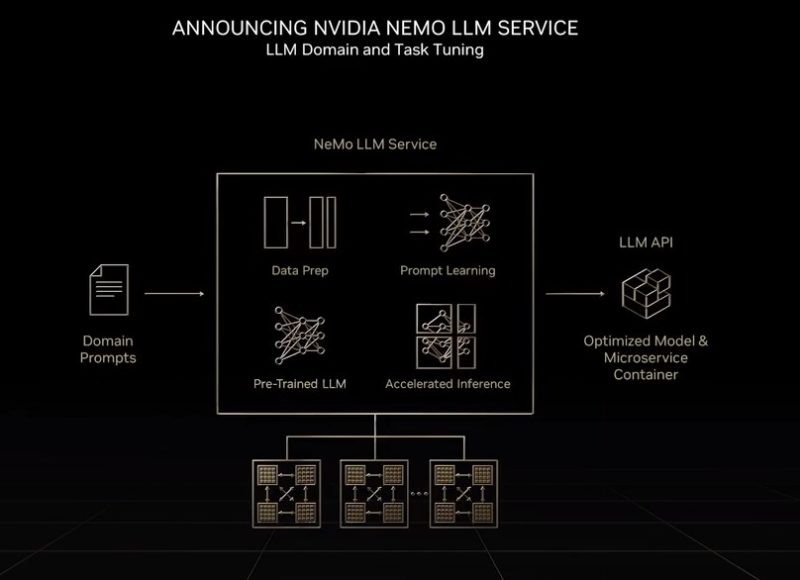
NVIDIA will have another version of this for healthcare and things like drug discovery. That will be BioNeMo. Both NeMo services are going to be in preview running on a NVIDIA SuperPod in October 2022. NVIDIA says the H100 is ~5x faster than the A100 for large language models due to the transformer engine.
NVIDIA H100 in Production Update
On the NVIDIA H100 side, it is in production now. It will be shipping in October via the PCIe versions.

The HGX-based platforms with SXM modules will be in Q1 so that will include machines like the DGX H100.

Next NVIDIA Grace.
NVIDIA Grace Details
NVIDIA said that its upcoming Grace Hopper will be ideal for recommender systems where there is a greater need for fast memory than just memory capacity.

Here is the new Grace Hopper chip with the Arm Neoverse V2 cores:
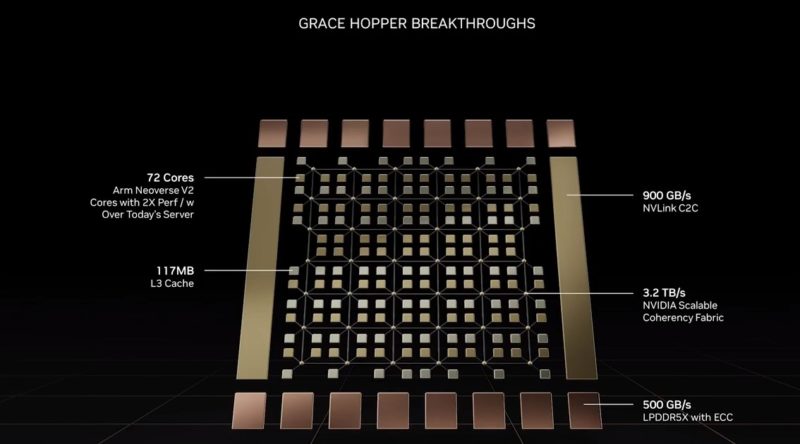
Many of these specs we already had. NVIDIA is saying that systems with Grace Hopper will be available in 1H 2023. We take that to mean in Q2 2023.

I am very excited for Grace and Grace Hopper.
NVIDIA L40 GPU for Omniverse
For the Omniverse, there is a new L40 GPU with 48GB of memory.

This is a PCIe card that NVIDIA says is in full production. We asked NVIDIA about this a few weeks ago, and they finally acknowledged that it would be a GPU a few days ago.
Final Words
The NVIDIA RTX 4000 series and L40 based on Ada Lovelace are big improvements over the previous generations. Also, the Orin IGX is super exciting. Perhaps the bigger impact is that NVIDIA is focusing on offering cloud services. Eventually, NVIDIA is going to use cloud services like NeMo and Omniverse to generate huge attach to NVIDIA ecosystems and also higher-margin opportunities. Eventually NVIDIA will look at the huge margins that cloud providers and software providers have and realize they can better monetize many GPU accelerated functions by just hosting those functions itself. That is what we are starting to see today.
I am Presenting a Gigabyte Ampere Altra Max Arm Server with NVIDIA A100 at NVIDIA GTC. You can check that one out, but we will have more Ampere Altra Max with NVIDIA A100 GPUs on the STH main site next week.



{kind=link}
3060(192bit 12GB $329) -> 4080 (192bit 12GB $899 ~273% price for 192bit tier(104 class with 2 32bit channels broken)
3060Ti (256bit $399) -> 4080 (256bit 16GB $1199) ~300% price for 256bit tier full chip
3090 (384bit $1499) -> 4090 (384bit $1599 ) ~7% price increase? WTF?
whoever came up with this pricing structure deserves to be fired immediately. 192bit/256bit users will get ass whooped. And the 4090’s price is so fake, a 50% bigger VRAM bus only gets 33% more price than 3080?
GTC Sept 2022 Keynote with NVIDIA CEO Jensen Huang
https://youtu.be/PWcNlRI00jo?t=301
Obi wan AMD you are our only hope :-)
Why are you comparing the 3060 to the 4080, and treating the width of the memory interface as if it were the deciding factor for making an apple-to-apples comparison, as if it were like weight in combat sports. That’s pure fallacy. I doubt NVIDIA suddenly forgot how to balance their architectures for best efficient use of the resources in the target workloads of the products. There’s certainly no reason to assume they have before there is any chance to independently review the hardware.
@TS: indeed, but whoever came with the pricing will probably be promoted due to a lot of unsold 3xxx cards in NVDLA warehouses. Anyway, 4090 looks like a stellar offer in terms of increased tensor cores number. Now the question is AI benchmarking, let’s see in upcoming weeks.
A main driver of the crippled memory interface widths this generation is significantly enlarged on-chip caches. 4090’s (and even 4080’s) L2 is more than 10X the size of 3090, so that will surely help mitigate the penalty of a narrower bus.
Did they kill NVLink?
Only thing I need to know is whether the 4090s have all the memory chips on the front under the heatsink or will we have another cooling disaster like the 3090s.
Exactly how is another version of pay-out-the-you-know-what-as-you-go *insert something cloudy-AIish here* service, exciting? I mean, don’t get me wrong, I crave infotainment as much as the next…human(?), but, I also like that water stuff. Arizona is all tapped out at this point. California is not much better, so we, with the incoming factories, get the honor. Have ya been out to Lake Travis lately? I’ll guess no from the tan. Sometimes Island is a peninsula. I’ll pause while someone explains how amazing immersion cooling is… As long as you don’t read any of the datasheets for any of the chemicals used…I mean most have Global Warming Potential ratings higher than methane. The others just kill anything in the water that it mixes with. Great stuff. Saves the data centers a buck. But in the end, can thoroughly kicked down the road, thermodynamics is a bitch. Maybe toasters just don’t need to have WiFi to get the data for the AI to sift.
Comments are closed.