
Right now, AMD EPYC has the potential to use more PCIe lanes for GPU connectivity than Intel platforms. Ever since the AMD EPYC launched in mid-2017 one of the biggest questions has been around using the platform’s PCIe lanes for GPUs. We recently had the opportunity to take an NVIDIA GPU and set it up for one of our DemoEval customers. In the process, we learned a few tips that we wanted to share.
Test Configuration
Here is what we are using for the server:
- System: Supermicro 2U Ultra EPYC Server (AS-2023US)
- CPUs: 2x AMD EPYC 7601 32-core/ 64-thread CPUs
- RAM: 256GB (16x16GB DDR4-2666)
- OS SSD: Intel DC S3710 400GB
- NIC: Mellanox ConnectX-3 Pro 40GbE
- GPU: NVIDIA GeForce GTX 1070 Ti 8GB
A few quick notes. Using an NVIDIA GeForce GTX series GPU in a server presents a small challenge. NVIDIA changed the GPU power connectors in recent Tesla and GRID GPU generations to minimize cabling. Server vendors usually have appropriate power cabling to make this work. We had to ask Supermciro to help us find the correct cable.

Many 2U servers from major manufacturers since the Intel Xeon E5 V3/ V4 generation had GPU power headers available on their PCBs. After we had the right power cable, we could install our test NVIDIA GeForce GTX GPU into one of the risers.

The riser fits neatly into the system although you can tell the top power connector of GTX series GPUs can be a tight fit.
One can see the GPU installed in our AMD EPYC test system just above the PSUs (we are using one here for slightly better power efficiency.)

Overall, the process of installing the GPU was easy after we had the right power cable.
The second note is that we had issues downloading and installing the latest NVIDIA drivers using our standard scripts on AMD EPYC. The driver run file we downloaded did not work with either this server or another AMD EPYC server.

An easy fix was using the graphics ppa and installing from there. If you get stuck, that is a quick way to make this setup work.
Testing Tensorflow and Cryptomining with AMD EPYC and NVIDIA
For those wondering why we are using the NVIDIA GTX 1070 Ti, it was a GPU we were requested to configure for one of our DemoEval customers, and we had it on hand. We used our standard Tensorflow GAN training image on the AMD EPYC system along with Zcash mining.
On the Tensorflow side, we were noticing performance slightly lower than we had expected at first. Our Tensorflow image was set up to use on single-root PCIe systems and with an Intel Xeon CPU. As a result, it automatically configures itself to pin to the first NUMA node.
In our Supermicro test system, the PCIe 3.0 x16 lanes we were using are attached to a different NUMA node on the AMD EPYC system. This is a normal result of the AMD architecture.

We decided to test what would happen to performance when we attached the NVIDIA GeForce GTX 1070 Ti GPU to the same NUMA node and to a different NUMA node.
We changed the docker container to run on the NUMA node that the GPU is attached to (same NUMA) and we got a solid ~6.5% speedup in Tensorflow training.
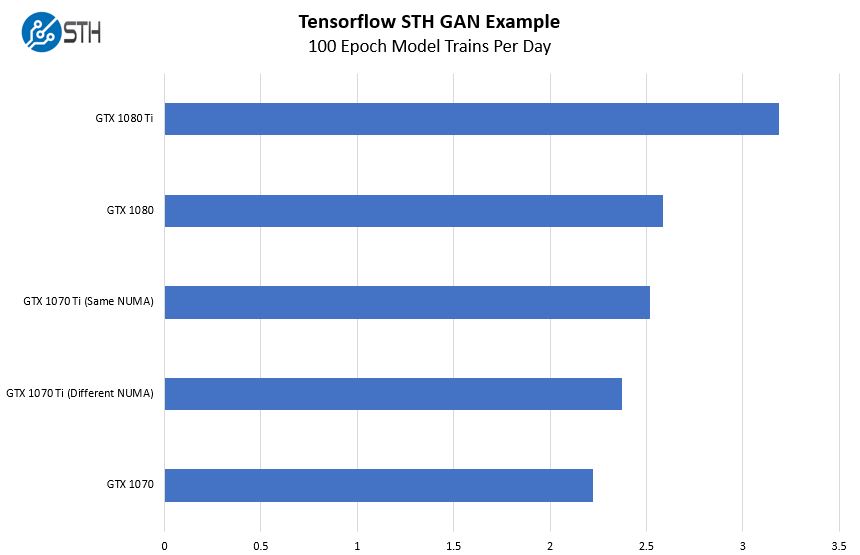
That is a big deal in terms of performance and also why we see deep learning / AI data scientists care so much about NUMA nodes.
Since we need to abide by the new NVIDIA EULA for CUDA 9, we then “moved the server to the data center”, where we are OK running CUDA for crypto mining in the data center.
We tried a similar experiment using Zcash mining using stock clocks and the EWBF miner.
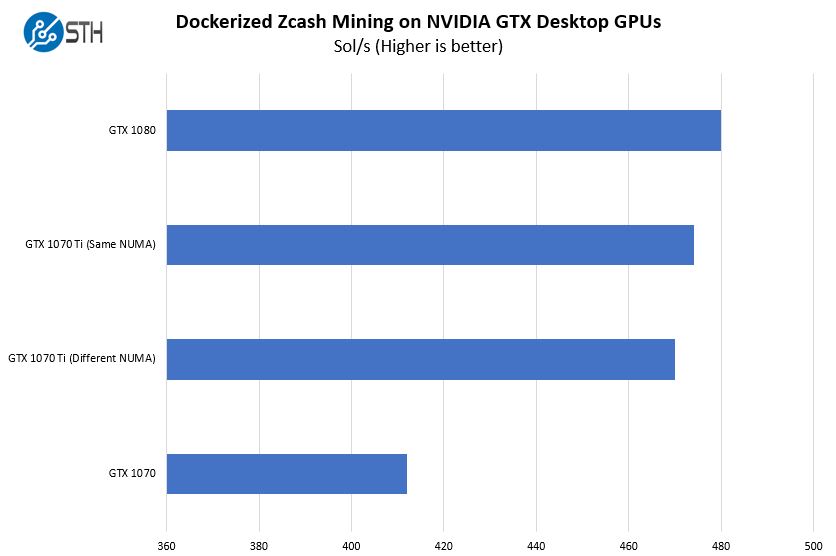
As you can see, we again get a nice 1% speed-up by pinning the docker container to the proper NUMA node. With mining, that is a fairly considerable gain. We validated these results also using Skein based algorithms and saw a speed up by using the correct NUMA node as well.
The other major note here is that we validated these figures with Intel Xeon systems and saw CUDA 9 applications running essentially at the same speed whether they were connected to an Intel Xeon or AMD EPYC CPU. That is a significant validation in itself.
Final Words
For anyone in the deep learning or GPU compute space, these results are not going to be groundbreaking. At the same time, there are a few implications of this experiment.
One option with these applications is to use numactl to pin CUDA applications to the proper AMD EPYC node. Using nvidia-docker(2) one can also constrain applications to specific NUMA node(s). In terms of performance, we highly suggest that if you are using NVIDIA CUDA applications with AMD EPYC, that you focus energy on pinning to the correct NUMA nodes. We found AMD EPYC performs well with CUDA and NVIDIA GPUs once you do this. One of the major advantages that EPYC has is for applications where CPUs are feeding data directly, rather than GPU to GPU communication, the EPYC architecture has more PCIe lanes attached to CPUs.



{kind=link}
Great content. Have you tried AMD GPUs as an ANTI Intel and NVIDIA play? We use NVIDIA for our DL apps but I’d like to hear more about AMD. I know you can’t get their GPUs though.
Patrick, are you getting the full PCIE bandwidth in both directions? On Threadripper machines I have been seeing asymmetric bandwidth, with GPU->CPU being as low as 5-6 GB/s.
Additionally, if you have a heterogeneous application that does use the CPU concurrently with the GPU(s), depending on the locality and cache traffic needs of the CPU code as well as communication needs across PCIE, you might actually see the two influence each other, I think; e.g. there will likely be an impact on CPU code depending on whether you use 2 or 4 GPUs. I have seen hints of this, but have not done thorough analysis yet.
That is one of the key reasons we have been pinning the containers to the same NUMA nodes as the GPUs they are attached to. You are right that as you scale to more GPUs and run models across multiple NUMA nodes, that makes things more complex.
I meant that on the machines I tested, regardless of the placement, I get low GPU->CPU bandwidth in one direction. Likely a firmware issue and may not affect EPYC platforms at all, but I was curious whether you can get the expected peak PCIE 3.0 bandwidth (and latency) with “closest” affinity set on the process. Also, how much is the loss when crossing NUMA domains? (Intel platforms have improved significantly, at least in terms of bandwidth e.g. on Broadwell I see little to no difference between “close” vs “near” GPU transfers.)
Comments are closed.