ZOTAC GeForce RTX 2080 Ti Twin Fan Deep Learning Benchmarks
As we continue to innovate on our review format, we are now adding deep learning benchmarks. In future reviews, we will add more results to this data set.
ResNet-50 Inferencing Using Tensor Cores
ImageNet is an image classification database launched in 2007 designed for use in visual object recognition research. Organized by the WordNet hierarchy, hundreds of image examples represent each node (or category of specific nouns).
In our benchmarks for Inferencing, a ResNet50 Model trained in Caffe will be run using the command line as follows.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -v ~/Downloads/models/:/models -w /opt/tensorrt/bin nvcr.io/nvidia/tensorrt:18.11-py3 giexec --deploy=/models/ResNet-50-deploy.prototxt --model=/models/ResNet-50-model.caffemodel --output=prob --batch=16 --iterations=500 --fp16
Options are:
–deploy: Path to the Caffe deploy (.prototxt) file used for training the model
–model: Path to the model (.caffemodel)
–output: Output blob name
–batch: Batch size to use for inferencing
–iterations: The number of iterations to run
–int8: Use INT8 precision
–fp16: Use FP16 precision (for Volta or Turing GPUs), no specification will equal FP32
We can change the batch size to 16, 32, 64, 128 and precision to INT8, FP16, and FP32.
The results are in inference latency (in seconds.) If we take the batch size / Latency, that will equal the Throughput (images/sec) which we plot on our charts.
We also found that this benchmark does not use two GPU’s; it only runs on a single GPU. You can, however, run different instances on each GPU using commands like.
```NV_GPUS=0 nvidia-docker run ... &
NV_GPUS=1 nvidia-docker run ... &```
With these commands, a user can scale workloads across many GPU’s. Our graphs show combined totals.
We start with Turing’s new INT8 mode which is one of the benefits of using the NVIDIA RTX cards.
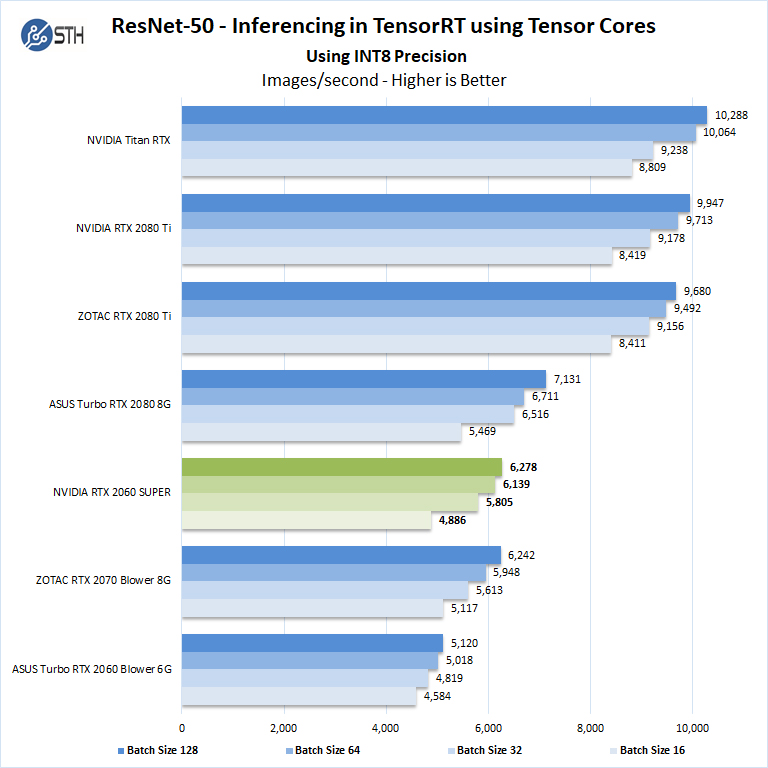
Using precision of INT8 is by far the fastest inferencing method if at all possible converting code to INT8 will yield faster runs.
We see the NVIDIA GeForce RTX 2060 Super runs relatively close to the ZOTAC RTX 2070 Blower 8G.
Let us next look at FP16 and FP32 results.
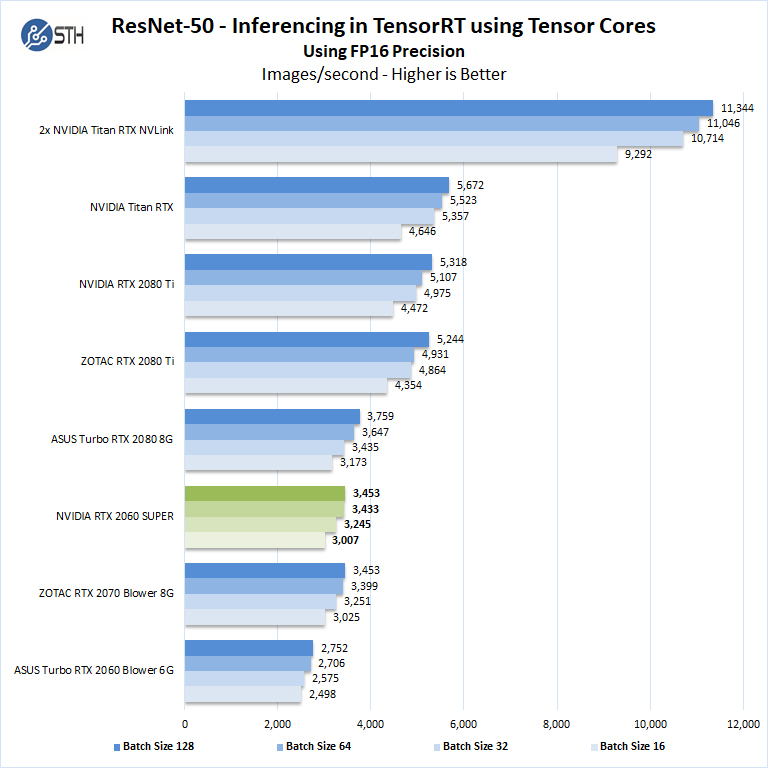
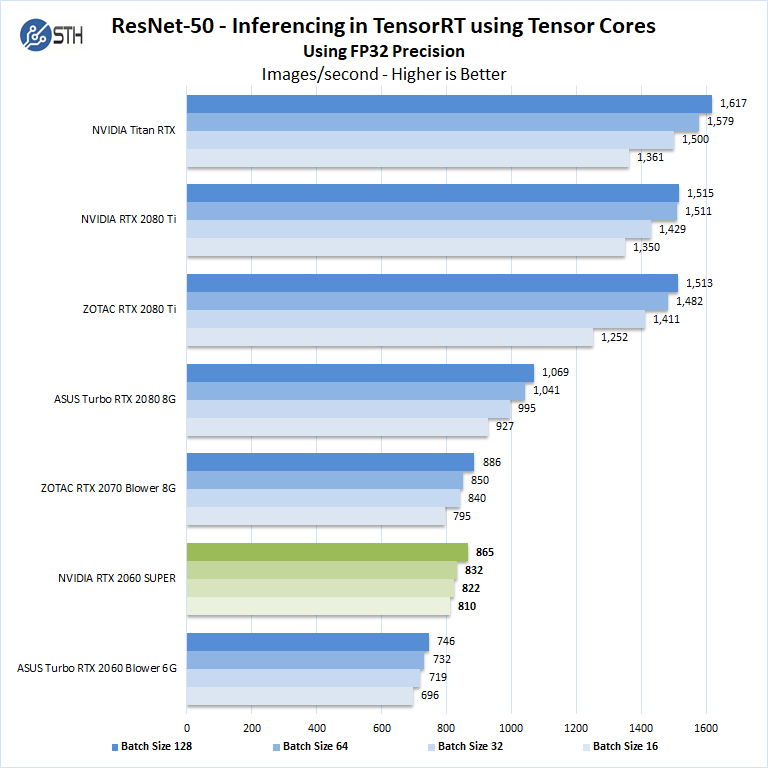
Here we see that the newer cards with more compute power perform well. For $50 we think if you need AI inferencing performance, the new Super model is a worthwhile upgrade over the GeForce RTX 2060 6G.
ResNet-50 Training using Tensor Cores and Tesnorflow
We also wanted to train the venerable ResNet-50 using Tensorflow. During training the neural network is learning features of images, (e.g. objects, animals, etc.) and determining what features are important. Periodically (every 1000 iterations), the neural network will test itself against the test set to determine training loss, which affects the accuracy of training the network. Accuracy can be increased through repetition (or running a higher number of epochs.)
The command line we will use is:
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/imagenet12tf:/imagenet --rm -w /workspace/nvidia-examples/cnn/ nvcr.io/nvidia/tensorflow:18.11-py3 python resnet.py --data_dir=/imagenet --layers=50 --batch_size=128 --iter_unit=batch --num_iter=500 --display_every=20 --precision=fp16
Parameters for resnet.py:
–layers: The number of neural network layers to use, i.e. 50.
–batch_size or -b: The number of ImageNet sample images to use for training the network per iteration. Increasing the batch size will typically increase training performance.
–iter_unit or -u: Specify whether to run batches or epochs.
–num_iter or -i: The number of batches or iterations to run, i.e. 500.
–display_every: How frequently training performance will be displayed, i.e. every 20 batches.
–precision: Specify FP32 or FP16 precision, which also enables TensorCore math for Volta and Turing GPUs.
While this script TensorFlow cannot specify individual GPUs to use, they can be specified by
setting export CUDA_VISIBLE_DEVICES= separated by commas (i.e. 0,1,2,3) within the Docker container workspace.
We will run batch sizes of 16, 32, 64, 128 and change from FP16 to FP32. Our graphs show combined totals.
Some GPU’s like the new Super cards as well as the GeForce RTX 2060, RTX 2070, RTX 2080 and RTX 2080 Ti will not show higher batch size runs because of limited memory.
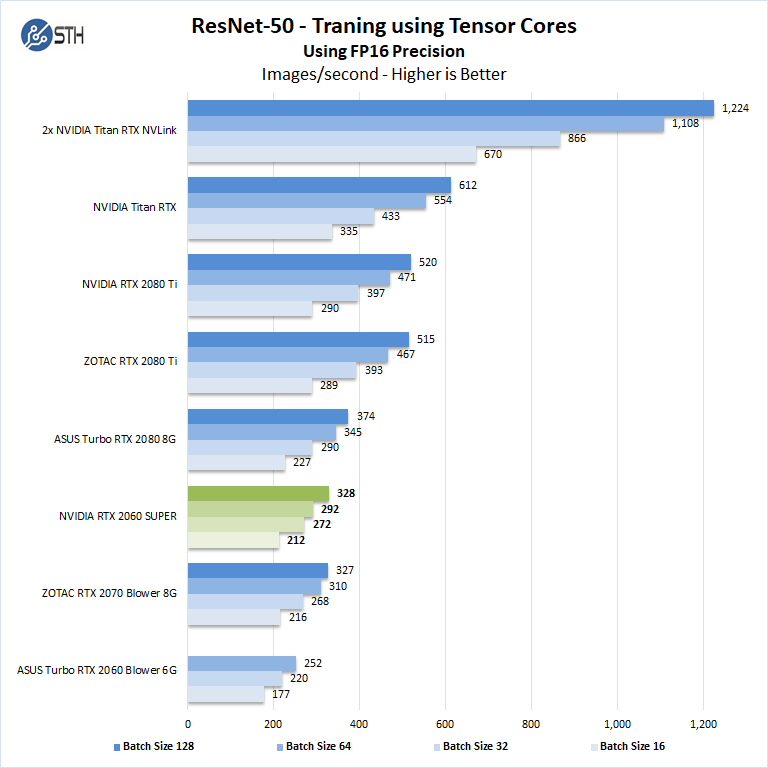
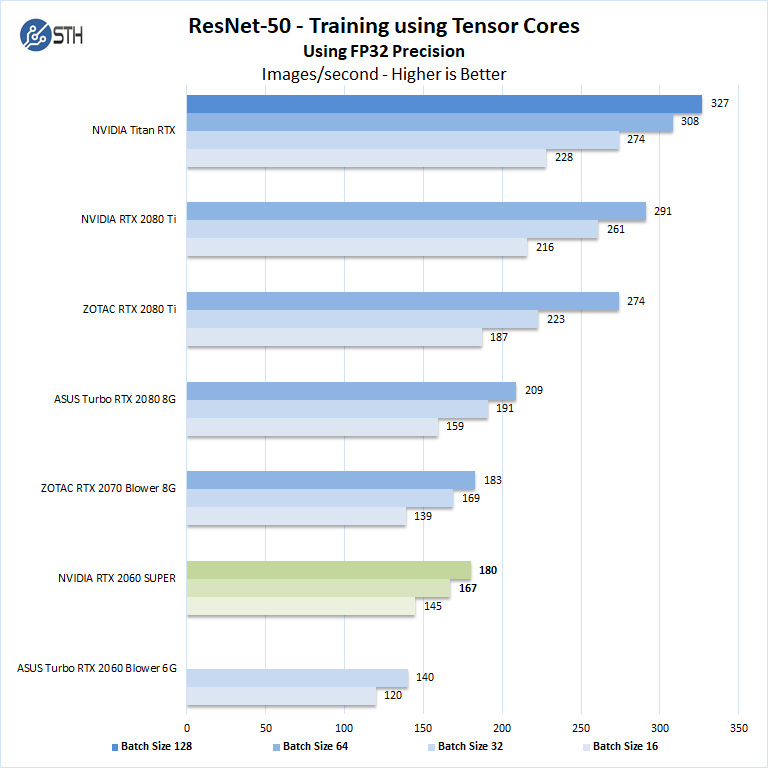
There are two very important items to note in our Tensorflow results here. First, we see results very close to the outgoing NVIDIA GeForce RTX 2070 8GB non-Super. Second, we are able to use a batch size of 64 with FP32 on the NVIDIA GeForce RTX 2060 Super because of the 8GB of memory. In contrast, the NVIDIA GeForce RTX 2060 6GB card could only use batch sizes of 16 and 32. That yields an immediate performance increase compounded by the additional compute power. If you are getting your feet wet in deep learning training, we highly suggest the new NVIDIA GeForce RTX 2060 Super 8GB for $50 more.
Next, we are going to look at the NVIDIA GeForce RTX 2060 Super power and temperature tests and then give our final words.



{kind=link}
Look at that TensorFlow training performance on pg. 5! That’s an insane upgrade over the Rtx 2060 6G. The Titan Rtxs change the chart’s scale but it’s a huge increase at the low end
Are you sure about this “Peak FP32 Compute: 14.2 TFLOPS”?
“A key reason that we started this series was to answer the cooling question.”
If the answer to this is your statement about running equal to other cards, that would not seem to be either a strong endorsement nor conclusive.
Hence I’m curious if it’d be possible to compare the 2060 Super vs. 2070 Blower. From your statement of test setup it appears the chart is single GPU, so perhaps multi-GPU would be closer to real-world. [yeah I know, ‘you guys should go buy 4 of those, a couple of these, some Titans …” etc., and I’ve spent $60k of your money that you don’t have 8]
Remember to use some beefy case fans, or just state what’s being used.
This review was very important to me, ended up demonstrating that the RTX 2060 SUPER is the true entry-level GPU for Machine Learning and Deep Learning. I have the following questions:
Which manufacturer has the best quality plate, greater durability, greater strength to work for long time under full load?
Is it possible to downclock this GPU by reducing its frequency? This is important in ML / DL processing that can last for days under full load, so the GPU does not constantly work overloaded, thereby increasing its lifespan and running the processing with more stability.
Workstation motherboards, in case you have two video cards or an offboard video card and the integrated video processor, such as ASUS Pro WS X570-ACE, ASUS WS C246 PRO, Gigabyte C246-WU4, have in their bios some kind of control in which can I set a card for video driver and another GPU to leave only for ML / DL processing?
Congratulations on the matter. I hope to briefly review the RTX 2070 SUPER.
Why wasnt Vega VII tested in this group?????
@asH
It’s only tested in benchmarks where NVidia is faster, just remember how STH earns their money.
I would love to know how we earn money @Misha? Sure is not from the STH publishing side for the last 10 years. Enlighten me. Seems like you know better than I do given the tone of that comment.
@asH very simple reason. We do not have one to test. If we did, it would be in there.
” ..very simple reason. We do not have one to test. If we did, it would be in there.”
-Then why wasnt that said that in the article?
Wait! Are you then saying you ONLY test cards given to you by manufacturers??
“On the AMD side, the new Navi based parts are unable to complete even half of our test suite due to the compute stack. ”
…Then this statement is a half truth because on the AMD side their compute card, Vega VII (based in MI50/60), the 7nm(25%) big brother to Frontier wasnt tested because you didnt have one. ..Quite an impressive array of cards you did have. Just sayin’
asH asH we tend to present the relevant data we have. For example, when we review a Xeon-based server we usually test with multiple SKUs. We do not test with all 50+ SKUs because it would take too long and we do not have every Xeon SKU.
We buy cards to test from time-to-time. On the other hand, we knew the Radeon VII would have a *very* short lifespan in the market. Given the price tag, our budgets, and expected traffic from a Radeon VII review, we could not buy one. Radeon VII was a very short-lived product.
On the Navi statement, that was based on AMD’s acknowledgment as well that their compute drivers for those cards were not ready yet. No half-truth there.
If you would like to provide a Radeon VII, we are happy to test it just to add to the database. My sense is that you just want to see the now discountinued Radeon VII in these charts.
I am surprised by the low DP FLOPS (FP64) performance for all of these. I know old GPUs had no or hardly any FP64 (like 1:24) but I thought newer cards had ratios like 1:3, or configurable allocations between FP32 and FP64, allowing up to 1:3 ratios. Is there some background to the testing that would clarify this, or are the advertised improvements in FP64 performance just hype?
Dear all,
I am really impressed with the benchmarks and your proffesionalism.
Please do share how to achieve such a high result (6990) in superposition, would really like to know that, or at least to come somewhat close to that (currently breached the 6000 limit).
Thank you in advance.
how could you reach 6990 points in superposition with the rtx 2060 super?
somebody…!
Jason – William just adds what he gets from the output using the test configuration he has. If you have a different configuration, you will likely get something different. We do not have the resources to troubleshoot everyone’s specific configuration.
that is not a 2060 super you are testing. look at your gpu z. the actual gpu and the texture fill rate is off.
and your TMUs
Comments are closed.