NVIDIA DGX Spark Topology
In terms of topology, here is what you might see with one of these:
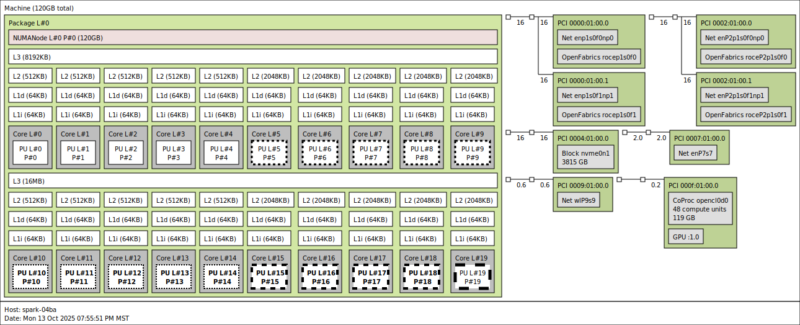
Here we can see the 20x Arm Cortex cores. There are ten Arm Cortex-X925 cores as the performance cores and 10 smaller Arm Cortex-A725 cores as the efficient cores. That might be the least exciting part, however. One huge feature is the 120GB total on top. This is because unlike an AMD Strix Halo system, we have a unified memory system here so we do not have to do a 32GB CPU, 96GB GPU split. Instead, we have a big 128GB pool.
Also notable is that we have the Realtek 10GbE NIC, the NVIDIA ConnectX-7 200GbE NIC, the 4TB NVMe SSD, and the 48 compute unit Blackwell GPU all in the topology map.
NVIDIA DGX Spark Software Overview
On the software side, this system uses the NVIDIA DGX OS, which is based on Ubuntu but with NVIDIA’s drivers and tools built-in. That also means we get the NVIDIA DGX Dashboard. We showed a bit of the setup in the video, but due to a display challenge it was harder to capture for this review. There is both a sit at the system and configure it local mode of setup as well as a network mode where the devices WiFi 7 NIC goes into AP mode and you connect wirelessly to the Spark.
With the system, NVIDIA also has the NVIDIA Sync program. This seemed silly at first, and then we used it and that first impression was dead wrong. What the NVIDIA Sync lets you do is to setup software so you can use the system remotely. It handles all of the SSH tunnels and so forth to make web interfaces work as an example. This was explained to us as you can unpack the system and have it on your desk running headless. Taking it a step further, I am roughly 1000km away from home writing this connected to the DGX Spark because we installed a Tailscale VPN on it. Tailscale plus NVIDIA Sync was an absolute winner of a combination.
Just to give you some sense, this combination allows you to quickly setup a Cursor environment accelerated by the DGX Spark.
There was also an option out-of-the-box for the NVIDIA AI workbench and VS Code integrations.
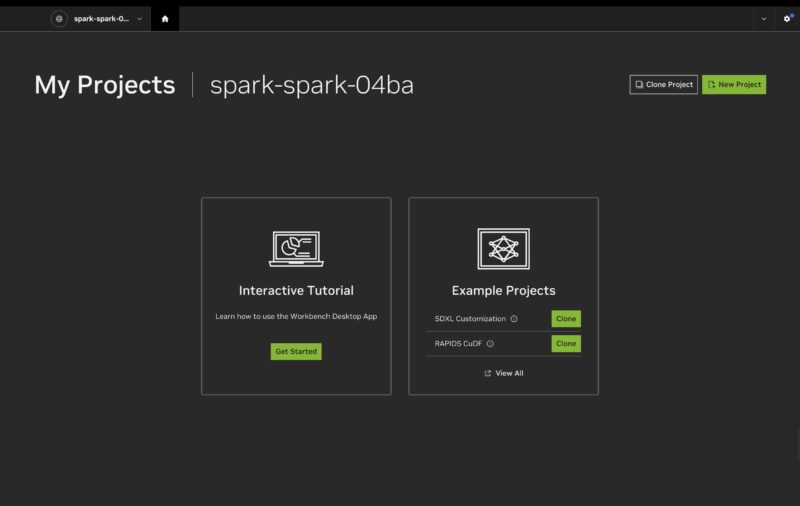
Here is Open WebUI running Ollama models. Notice that the host says “localhost” with port 12000. That is the NVIDIA Sync magic since this is actually sitting in the studio and I am accessing it remotely here. It may say localhost, but I am not even in the same state as the DGX Spark.
NVIDIA is also releasing a bunch of tutorials on how to get started with the DGX Spark along with the system. It has LLMs, image generation, fine-tuning, RAG, and other demos as well. This is something that AMD and perhaps Intel needs to copy.
Next, let us get to performance.
NVIDIA DGX Spark Performance
Taking a quick step back, the GPU has roughly the same spart FP4 math capability (~1PFLOP) as an NVIDIA GeForce RTX 5070. This is not a GeForce RTX 5090 class device because of how small it is. It also does not have the same memory bandwidth. What it has instead is a 128GB unified memroy structure. That means, we can have multiple models loaded at the same time and use larger modules.
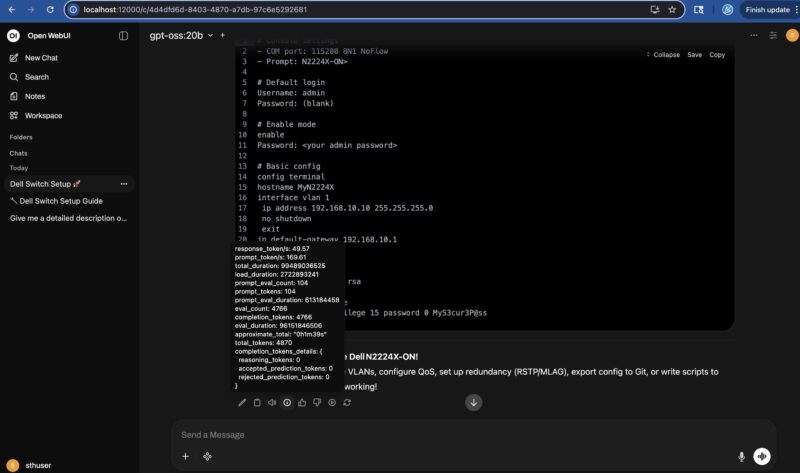
Just using the untuned out-of-the-box Ollama here, with OpenAI gpt-oss 20B we were often over 49 tokens/ second.
One does not have to stop there. With this system we can run big models like the gpt-oss 120B model and here we got 14.48 tokens per second.
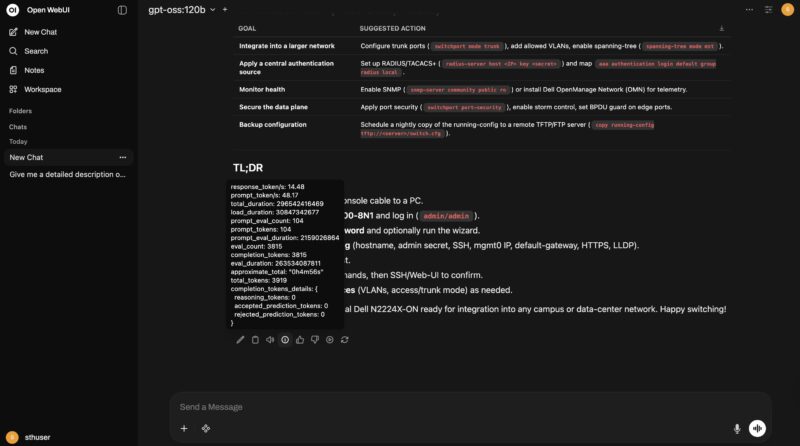
Qwen3 32b is a decent model and runs at 9-10 tokens per second out-of-the-box.
We are going to add a lot more here, but we are also trying to hit a quick turnaround. Stay tuned for more.
NVIDIA GB10 Geekbench CPU Performance
As a quick one, the 20-core CPU is probably going to be one that many overlook. It is actually quite quick. Here is an example of the Geekbench 5 CPU versus the AMD Strix Halo part. Note, the GB10 currently only supports Linux, but this is just a data point for folks:
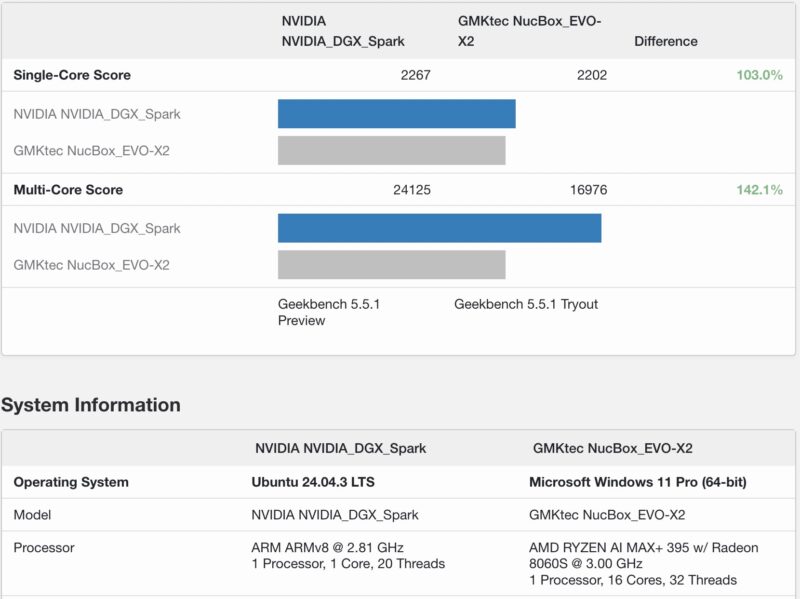
Here is a Geekbench 5 comparison versus the Minisforum S1-Max with the AMD Strix Halo running at a higher power level than in the GMKTec box.
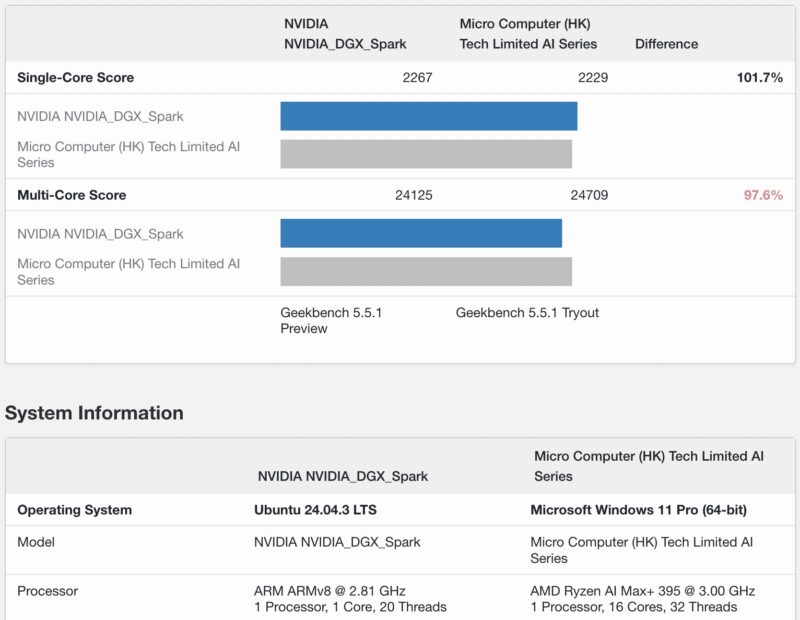
The CPU in these is probably the best Arm-Ubuntu mini PC right now especially with the connectivity.
Next, let us get to the teething challenges.
NVIDIA GB10 Teething Challenges
There are a few clear challenges working with the GB10. Somewhat surprisingly, video output is one of those areas that you think any NVIDIA product would nail. The Spark has been challenging to say the least. The LG OLEDs we have that are 1440p, display a garbled mess out of the HDMI port if set to 1440p output in the OS. Likewise, ultra widescreen monitors were a no-go.

We ended up using an old 4K 3840×2160 display, set it to 60Hz and everything worked. This is ugly, but, again, it worked.
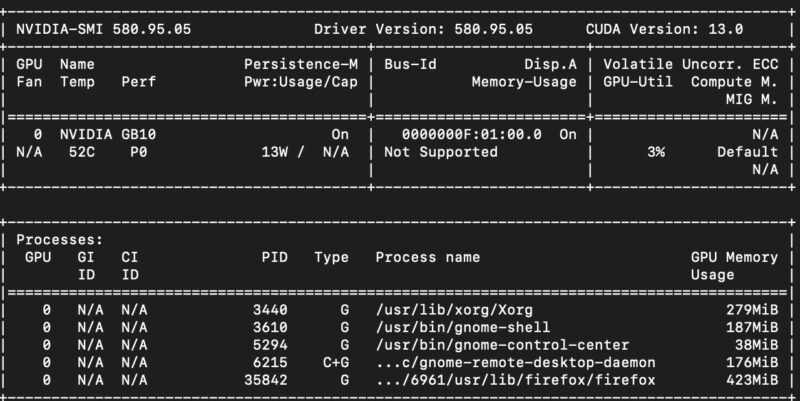
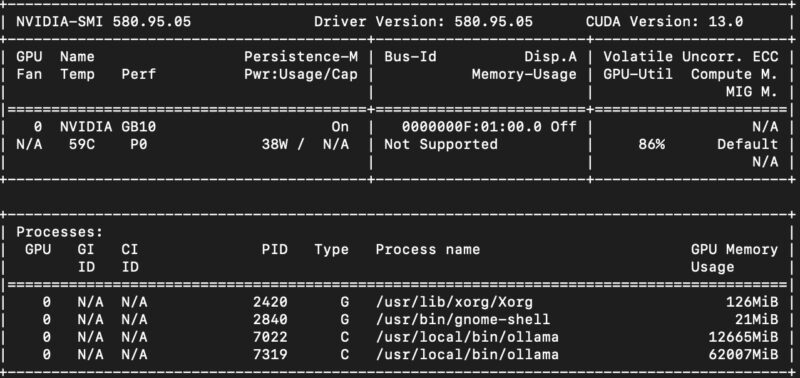
Perhaps the big one here though, is that we had this sample early in the process. It was not uncommon to see, after an update, the GPU drop from 13W at idle to 4W in nvidia-smi as an example.
My general sense, however, is that this is one of those systems where we are getting it early, and it probably gets better over time, but there is a bit of faith that goes into that statement.
Next, let us get to the power consumption.



{kind=link}
It’s a flimsy mini-pc with a somewhat decent gpu, a lot of vram and 200GB networking which when you want local ai for development is pretty good. It’s a lot cheaper than buying an AI server
My old 2023 M2 Max runs gpt-oss-120b. You quote 14.5 toks/s. Not a serious benchmark, but I typed what LM studio thought was 104 tokens (told me 170 after) and I got 53.5 tok/sec back. Hmm … “Here’s a nickel kid, go and buy yourself a real computer!” I do appreciate your review though. Keep up the good work!
It is a nice system. Do you have any comparison against Strix Point Halo and other systems? Of course some systems are a little bit apples to oranges, but such data is helpful.
I get ~43 tokens/sec (293 prompt tok/s) with a fresh prompt on my Strix Halo computer with GPT-OSS-120B (MXFP4). Is that Spark running a different quantization or is there something else causing the bad performance (CUDA dropping features because it’s too recent, etc.)? On paper the Spark should have an edge because of the higher memory bandwidth.
@Jack, how are you able to run 120B on Strix halo. I thought Strix only had 32G memory.
@Paddy, how are you able to run 120b on M2 ? I dont think the RAM on M2 can hold that big model.
@Adam strix halo with the 128 GB shared memory, like the Framework Desktop and others. I believe they come in 32/64/128 GB RAM variants. There are different types, but I think the AMD AI Max+ 395 or whatever it’s called is the only interesting one.
I believe many of them have articles about them on this site.
The Strix Halo 128gb boxes are half the price. I understand Patrick’s enthusiasm about 200GbE networking but the “throw it in a suitcase for a demo” use case doesn’t make use of it. For clustering I would think you need network storage that can keep up, and I’m sure someone will do it and make a YT video of it for the novelty but I’m not sure the niche here over bigger server hardware is that wide.
So a lot of this value proposition seems to come down to if you really want CUDA or not, which admittedly already commands a considerable premium.
@Oarman:
“The Strix Halo 128gb boxes are half the price.” And a GMKTec NucBox can go for as little as $125. So what? This device beats Strix Halo by 3% in single core performance, 40% in multicore performance and – if the author’s NVIDIA GeForce RTX 5070 comparison is correct – at least 25% in graphics performance as the AMD Radeon 8060S in Strix Halo can’t even keep up with the GeForce RTX 4070 in most tasks. And of course, the networking performance is better.
Now it is up to you to decide whether substantially better CPU, graphics and networking performance is worth $2000. But it is more than just CUDA here. It isn’t as if you can buy 2 Corsair AI Workstation 300 boxes and hook them up to each other to get 100% – or even 25% – more performance.
@rano
If you look at the above, it only beat the power limited Strix Halo box in the CPU performance, it lost in the multi-core when the strix was provided with full power. In addition, the above says nothing about graphics performance, only noting that the INT4 performance was the equivalent of a 5070. The only notes above graphics was that it was flaky driving a standard HDMI monitor. As it is based on on Blackwell AI chips it may very well have a very nerfed graphics processor (they are, after all, not designed for graphics processing but instead AI testing).
The network is certainly superior and having CUDA is certainly nice but the gpt-oss performance is surprising poor.
@Ehren:
“it only beat the power limited Strix Halo box in the CPU performance”
Because it itself is power-limited. The DGX Spark is smaller than the GMKTeck Evo 2. Yes, there will soon be Strix Halo machines that aren’t limited by the mini-PC form factor but the same will be true for Nvidia GB10 devices down the line.
“the above says nothing about graphics performance, only noting that the INT4 performance was the equivalent of a 5070”
Except that is about graphics performance.
“it was flaky driving a standard HDMI monitor”
Because it is a preproduction pre-release model running Nvidia’s DGX version of Ubuntu.
“As it is based on on Blackwell AI chips it may very well have a very nerfed graphics processor (they are, after all, not designed for graphics processing but instead AI testing).”
There is no such thing as “Blackwell AI chips”. They are just Blackwell chips used for professional applications just like their previous Ada Lovelace and Grace chips. The Blackwell Pro 6000 advertises itself as a workstation or high end desktop GPU, not an “AI chip.” Of course, this is nowhere near as powerful as a Blackwell Pro 6000, but the AMD Radeon 8060S is even further from an AMD Radeon Pro workstation/server GPU. (That being said, AMD’s 2026 integrated GPU is going to be way better, almost certainly good enough to match this one.)
https://www.nvidia.com/en-us/products/workstations/professional-desktop-gpus/rtx-pro-6000/
Both AMD and Apple fans are coming out of the woodwork to try to cut this FIRST GENERATION PRODUCT down a peg when both have been releasing their own productivity small form factor devices for years (except the Mac Mini isn’t that small). Hilarious.
There are definitely not for AI developers as in people working on AI. They seem excellent at being small, easy to setup edge devices running private models in typical edge locations.
I doubt executives will buy these and put them in their C-suites when trying out local models. At half the price of an Blackwell Pro 6000 I also doubt that clustering them outside of said edge locations will be viable. And for the ambitious homelabber clustering won’t play a major role which means back to Strix Halo machines at half the price.
These will be neat to play with once they hit the secondhand market at reasonable prices (I would probably pay up to $500 for one of these). Investors and corps will be left holding the bag after buying into the ‘AI is a magic box that replaces human knowledge workers’ delusion.
The llama.cpp github suggests that the poor performance is due to powersave settings. I’m not sure if there’s a module parameter for that or if it requires code updates, but there seems to be a way to make the performance match the specs at least.
I reserved a Spark Duo early in the Reservation window, and was notified last week that I would soon receive an email letting me know when I could finalise my order; the expectation being that I would receive my product ahead of general release.
15 Oct came (and went) with no notification.
So, I decided to just grab one from MicroCenter (I can always get another down the line). Placed my order before Sunrise, and purchased it later this morning.
It’s still in the box, as I have other priorities to attend-to.
Anyone want a late, early release Reserve for a Duo (if I ever receive it, that is)?
does anyone know why they keep on mentioning only 200Gbps throughput total for what appears to be 2 qsfp112 ports which should be capable of 400Gbps total. One way to check is to look at the Lnksta and see if the pci design is limited to x8. If it shows 32GT/s and x16 for each port, there might be a better chance at doing 400Gbps with both ports connected. The IC itself could still be limiting or maybe just a fw limitation.
the docs state that the spark supports multi-rail for the cx7 nic ports. So you should at least be able to connect both ports in a load balancing cfg.
Nice network testing STH.
So, based on the recent network tests, it can only reach maximum throughput of 100Gbps across both QSFP ports? That is strange since Nvidia is claiming it’s 200GbE NIC.
> This is because unlike an AMD Strix Halo system, we have a unified memory system here so we do not have to do a 32GB CPU, 96GB GPU split. Instead, we have a big 128GB pool.
No! Strix Halo like all AMD APU are unified memory. The 32/96 split is only for windows 3D games. On Linux I have no problem to get >126G of RAM and use all of it on GPU with HIP.