
CES 2026 is here!
Kicking things off for the major chipmakers today is NVIDIA, who is at the show to talk about all things AI – a hot topic across the entire industry at the moment.
NVIDIA CES 2026 Keynote Live Coverage Preview
As with most of NVIDIA’s major presentations, company CEO (and leather jacket enthusiast) Jensen Huang will be headlining NVIDIA’s CES keynote. Also as is usually the case, NVIDIA is being fairly mum about what they will be talking about ahead of the presentation, beyond the fact that it’s all going to be AI-related. And despite being a consumer show, it sounds like the keynote may be limited more towards Enterprise offerings, as NVIDIA’s GeForce group has a separate presentation scheduled for 9pm Pacific this evening. A presentation in which the GeForce group is already setting expectations by stating that there will be no new GPUs announced.
Unlike 2025, where NVIDIA helmed CES’s prime keynote spot, in 2026 they are a bit of an outlier. Officially, the event is not even a keynote open to all attendees, but rather a press conference limited to the media. And it’s not taking place in the Mandalay Bay or Venetian hotels – where most official CES events happen – but rather out at the Fontainebleau hotel. So NVIDIA is a bit off the beaten path this year, running their own press conference at their own hotel. Even the scheduling of the event was relatively late, with NVIDIA not publicly announcing the event until December.

As for what NVIDIA may have up their sleeve this year, NVIDIA’s enterprise hardware schedule calls for 2026 to be the year of Vera Rubin, with that hardware shipping at some point during the year. As well, NVIDIA always has new software to talk about since development of that is largely decoupled from their hardware. But how much they’ll have to say at a more generic venue like CES remains to be seen.
NVIDIA’s keynote kicks off at 1:00pm PST / 4:00pm EST / 21:00 UTC, and according to NVIDIA’s calendar hold, this should be a pretty meaty keynote that runs for about 90 minutes. So please join us in a bit for our live blog coverage of NVIDIA’s CES 2026 keynote.
(And, as always, please excuse any typos stemming from our live coverage)
NVIDIA CES 2026 Keynote Coverage Live
At this point it’s 6 minutes after the hour, and we’re still waiting on NVIDIA to get started. One thing that is in NVIDIA’s favor this year is that since this is not an official CES keynote, they should be able to get right to their presentation without the wrap-around CES/CTA introductions.
Another 6 minutes in and we’re still waiting. For better or worse, we’re not actually in Vegas to cover these keynotes. But it also means I can’t check in with the sportsbook to see what the odds are on NVIDIA starting with another “I am AI” video.
And with that said, here we go!

It looks like we are starting with a montage of GPU rendering and simulation technologies instead. RTX graphics, NVIDIA’s various robotics and physics simulation frameworks, etc.

And here’s Jensen.

3000 people in the auditorium, and another 3000 people in overflow rooms. Not to mention everyone watching the stream.
“Every 15 years the industry resets”
New platforms arise, and new applications get written for those platforms.

This time there are two platform shifts going on. Not just the shift to GPUs, but how applications are even developed. They’re not programmed, they’re trained.
“Computing has been fundamentally reshaped as a result of accelerated computing, as a result of artificial intelligence.”
The modernization of AI is attracting enormous amounts of investment into NVIDIA’s industry.

Jensen is recapping a busy 2025 for NVIDIA – and a larger recap of NVIDIA’s history with AI. As well as the phases of AI models and the rise of reasoning models.
2025 was the year of proliferation for “agentic” models that can do higher level reasoning. NVIDIA is betting big on agentic systems becoming important tools in processing data and providing services.
Finally, 2025 was the year of the proliferation of open models. Which makes AI technology more accessible to everyone.

“This entire industry is going to be reshaped because of that.”
NVIDIA has been making their own investments into open models. Which, in turn, has been what they’ve been using their array of company-owned DGX SuperPOD to train and develop.

“NVIDIA is a frontier AI model builder.” NVIDIA wants to enable every company to be part of the AI revolution.
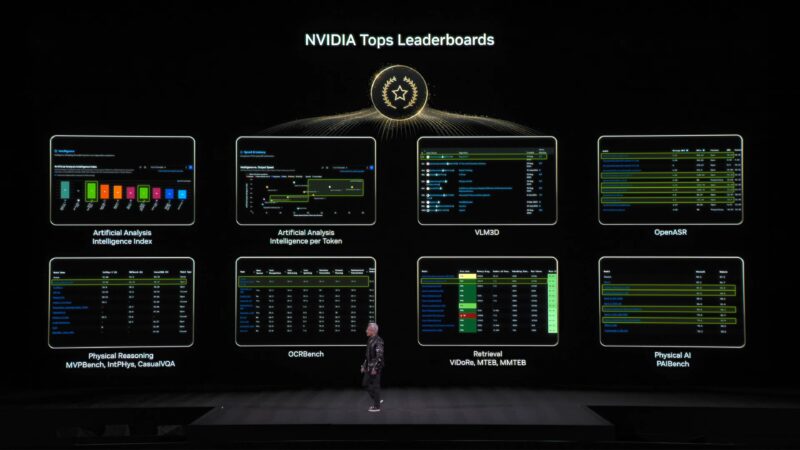
NVIDIA’s models top the leaderboards in terms of performance and other metrics. All in service of helping NVIDIA’s customers develop AI agents.
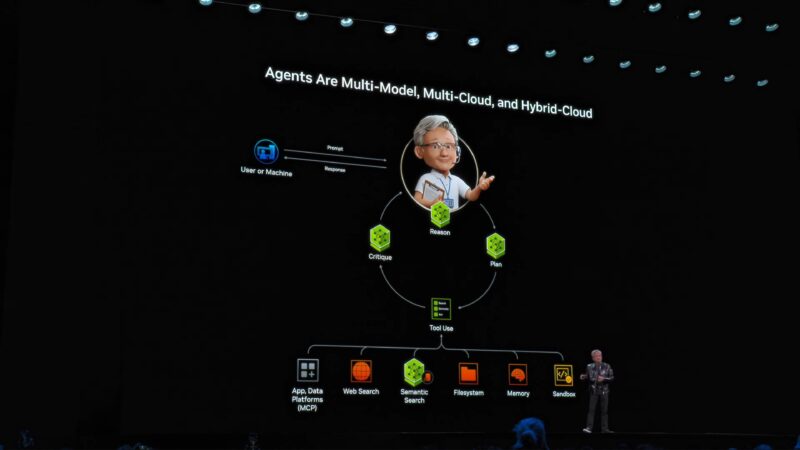
Now on to reasoning, and how it is changing the face of AI models. To be able to reason beyond just what it has been explicitly trained on.
Building on top of that is multi-model and multi-modal agents, which can call each other based on their specialization and training.
Now rolling a video showing a short example of building a personal assistant using NVIDIA’s hardware and frameworks.
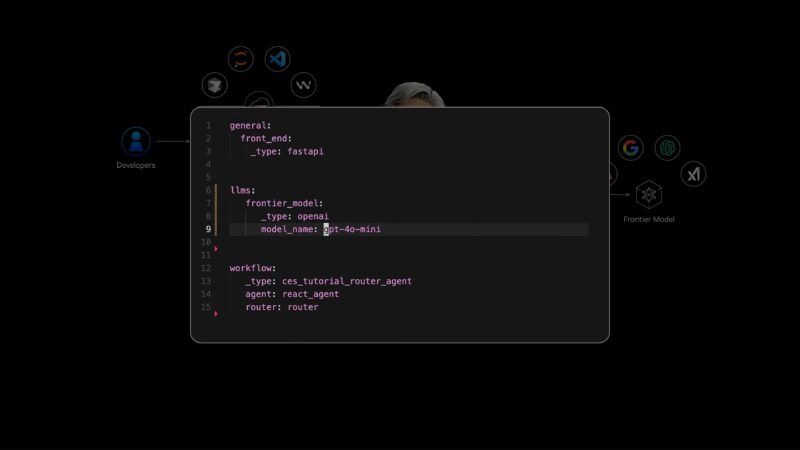
“The amazing thing is that is utterly trivial now.” But it would have been unimaginable a couple of years ago.
(Jensen has not been having much luck with his presentation screen and slide deck today)
Regardless, this is the future Jensen wants to move to. Development is tying together frameworks based on models that have already been trained to handle specific tasks, with further training and reasoning to expand the capabilities of these systems.
“The agentic system is the interface.”
And that is Enterprise AI being revolutionized by agentic systems.
Now on to physical AI.
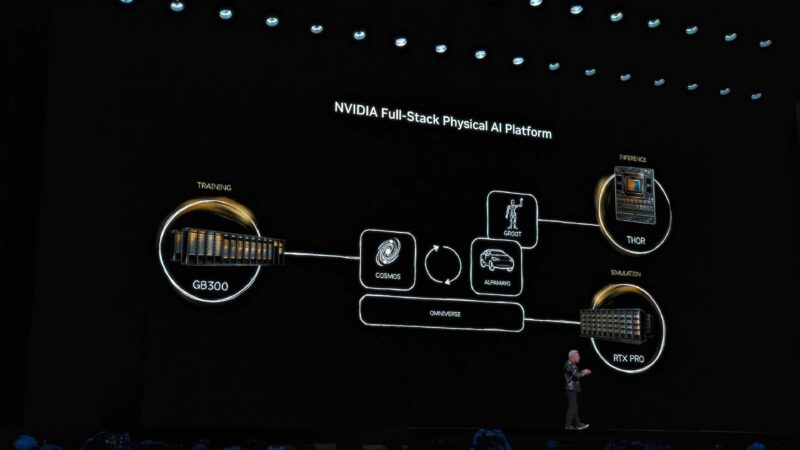
A big challenge for physical AIs: object permanence. It’s not just learning the laws of the physical world, but keeping track of things that may not be their focus.
The hardware to make all of this happen is a trio of computers. Training on NVIDIA’s big iron hardware, inference at the edge with things like Thor, and then physical simulations using RTX Pro servers.
Jensen is also recapping the various models/frameworks NVIDIA offers for the task. Cosmos and Gr00t, which have been around for a couple of years now, and what appears to be a new model: Alpamayo.

Now rolling a video about Cosmos, NVIDIA’s physical AI simulation framework and world foundation model.
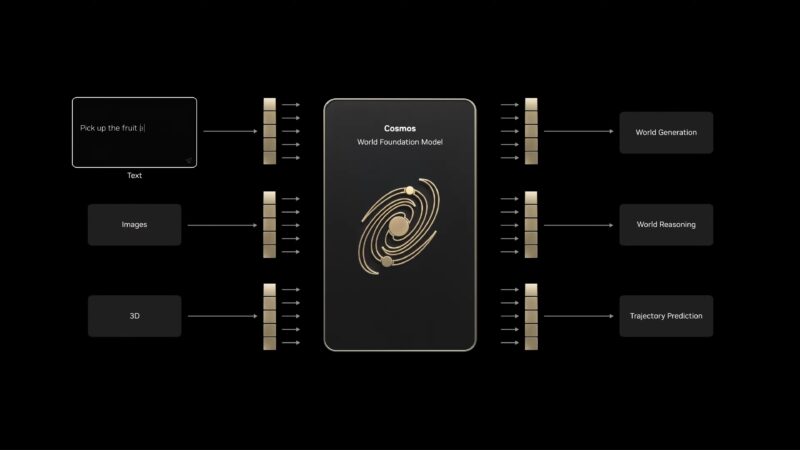
Cosmos can generate realistic video from images, and physically accurate simulations from 3D models. Even scenario prompts are enough to generate a video. “Cosmos turns compute into data.”
Cosmos has already been downloaded millions of times. And NVIDIA uses it internally for their self-driving automotive tech.
Announcing today: Alpamayo. The world’s first thinking and reasoning automotive AI.
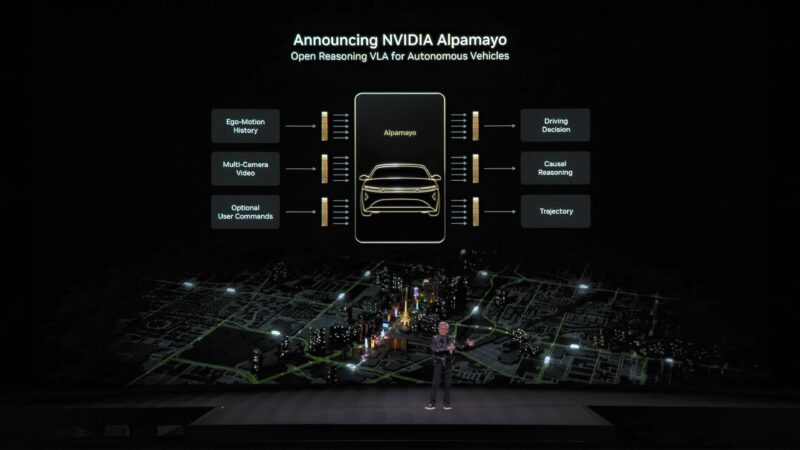
Alpamayo isn’t just an AI for self-driving cars. But it is an AI that can explain why it is doing what it is doing, and its reasoning process that led to that decision.
Now rolling another video, this time of self-driving automotive tech. All hands-free and taken in a single long shot.

(The future of San Francisco is to be a city of robots)
NVIDIA’s video is interspersed with quotes. From what I gather, it sounds like they’ve been driving journalists around in their cars.
“We started working on self-driving cars 8 years ago”
Alpamayo is open source.
(This is the most enthusiastic I’ve seen Jensen about self-driving cars in a few years now)
The combination of NVIDIA hardware, frameworks, and now Alpamayo is the company’s first complete stack for self-driving cars.
Jensen thinks this will be one of the largest robotics industries.

Mercedes Benz CLA just went into production. It has already been rated the “world’s safest car” by one group.
Parallel to Alpamayo is the safety system that validates everything that Alpamayo does. Something that apparently took NVIDIA half a decade to build.
“We’re going to maintain the stack for as long as we shall live”
Note that the emphasis is on L4 vehicles, not L5 fully autonomous vehicles.

Ultimately, most everything here developed for self-driving automotive can also be applied to other forms of robotics.

NVIDIA is once again showing off the proof-of-concept droids they’ve been developing over the past couple of years. As well as how they were trained inside of a physically-accurate simulated environment.
How do you learn to be a robot? You do it all inside of Omniverse.

“We’re going to talk a lot more about robotics in the future”
NVIDIA has said before that they see robotics as the next great market for the company. Hence the heavy investment into robotics.
Jensen is now going on a tangent about chip design – which like everything else is becoming AI accelerated. So even the chips going into Jensen’s robots are going to be created in a simulation.

Now rolling a video about working with Siemens.
And now on to some hardware. Vera Rubin.
But first, a quick recap on the history of Vera Rubin the astronomer, and why NVIDIA named their next platform after her.
Vera Rubin is designed to address the insane demand for AI computing.
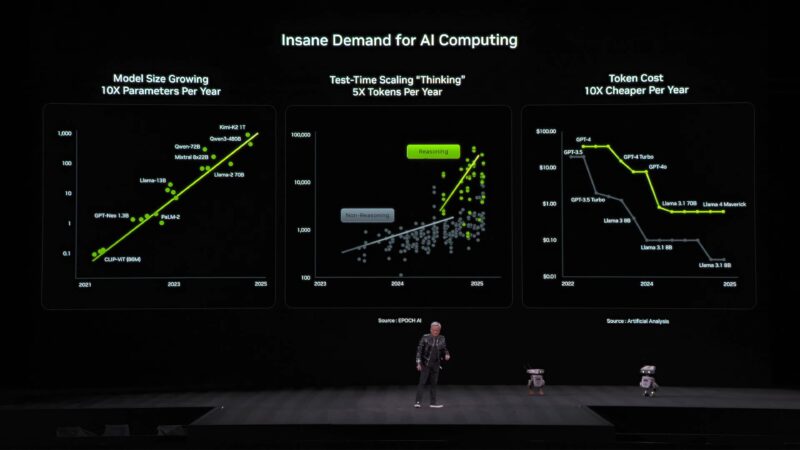
The number of tokens needed for cutting-edge inference has exploded, especially with the rise of thinking/reasoning models. And the race is on for AI to get to the next frontier.
All the while the cost per token continues to drop, making the higher number of tokens required economically viable.
NVIDIA is in full scale manufacturing of GB300 right now. And Vera Rubin will ship this year. Vera Rubin is in full production.
Now rolling a video about Vera Rubin.

1 Vera CPU + 2 Rubin GPUs.





The first Vera Rubin NVL72 rack is online.


“Moore’s Law has largely slowed”. So NVIDIA cannot keep up by just throwing more transistors at hardware. At least if they want to keep up their current pace.

So NVIDIA had to redesign all of their core chips in a single generation in order to improve performance and add functionality to keep up with client needs.

Despite only having 88 CPU cores, each one of the 176 threads on Vera can get its full performance. It is effectively a 176 core CPU.
NVIDIA has to employ extreme co-design across all of its chips in order to hit its performance goals.
Now talking about FP4 capabilities, and specifically NVIDIA’s NVFP4 format. Achieving higher throughput when the lower precision is acceptable, and using higher precision when required. All of which is handled adaptively.
And all of this is delivered with just 1.6x as many transistors for Vera Rubin versus Grace Blackwell.


The Vera Rubin compute tray is cable-free. The assembly time is down from 2 hours to 6 minutes. It is also 100% liquid cooled, versus just 80% for the Grace Blackwell compute tray.
Tying all of this together is NVIDIA’s family of networking hardware. ConnectX-9 NICs, BlueField 4 DPUs, and Spectrum-X networking platform. Networking performance has been critical in enabling scale-out scaling of NVIDIA GPU systems.
Spectrum-X is for East-West traffic, while BlueField 4 is for North-South traffic. BlueField 4 comes standard with every one of the Vera Rubin compute nodes.

NVLink 6 Switch chip employs 400G SerDes. Twice the speed of NVLink 5, and twice the speed of most everything else. So that every GPU can talk to every other GPU at the same time.

(Apparently they forgot to drain the water out of the NVL72 demo system before shipping it)

NVIDIA’s SerDes drive cables form the top of the rack to the bottom. 2 miles of copper cables in NVL72. The NVLink spine.
Vera Rubin’s power consumption is twice as high as Grace Blackwell. But NVIDIA is able to cool it with 45C water?!
NVL72 will offer 5x the inference performance, and 3.5x the training performance.

Spectrum-X chip with silicon photonics. 512 200G ports.

NVIDIA’s co-packaged optics technology was developed in conjunction with TSMC. It is essentially how NVIDIA is making faster optical networking speeds economically viable at the scale they need for a supercomputer.
Now in a segue to talking about tokens and key value (KV) caching.

Inference generates a massive amount of context data – too much to keep on AI nodes. That data either must be tossed and recomputed, or a way is found to efficiently store it.
Enter NVIDIA’s Context Memory Storage Platform.

All made possible with NVIDIA’s ConnectX and BlueField networking products.

All combined, this makes up a Vera Rubin pod.
In other news, the entire system is now capable of confidential computing. Blackwell was previously capable of confidential computing, but Grace was not. Now, Vera is, meaning it can work in concert with Rubin to allow for confidential computing (encryption) over the whole rack/pod.
Rubin can train an example model in 1/4 of the time. Or constant time with 1/4 as many GPUs.
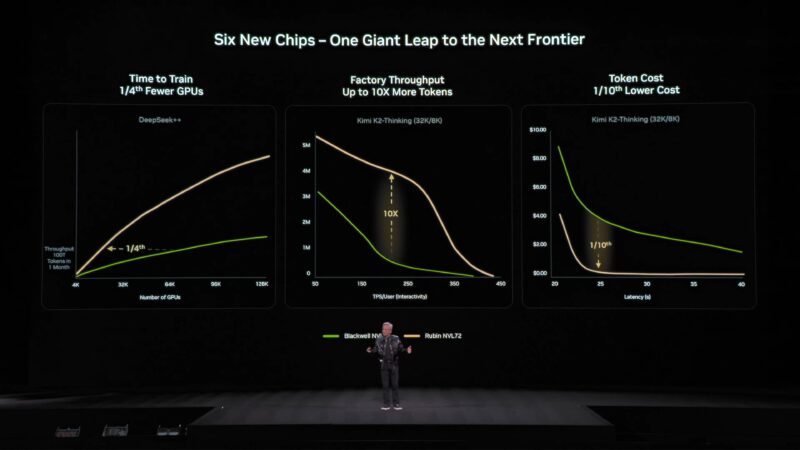
And very quickly recapping NVIDIA’s announcements. That’s a wrap for NVIDIA’s CES 2026 presentation.




{kind=link}