
Graphcore is moving to scale its systems to even larger numbers. The latest announcement is the availability of the Graphcore IPU-POD128 and IPU-POD256 adding, even more, compute to Graphcore clusters.
Graphcore IPU-POD128 and IPU-POD256 Extend Scale
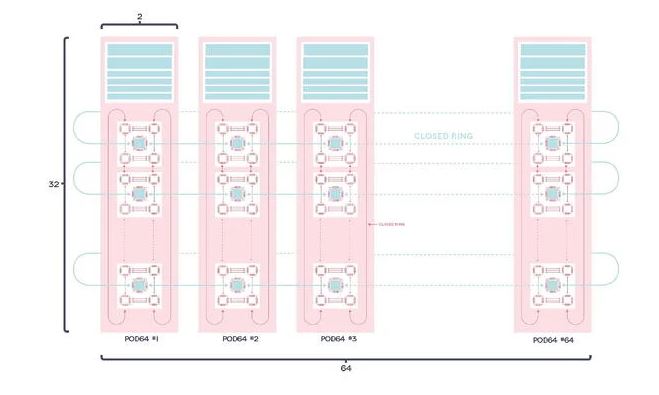
Graphcore already had IPU-PODs ranging up to 64 units (IPU-POD64) but the new announcement covers clusters two and four times as large. Scaling in a Graphcore IPU-POD is accomplished via a 100GbE switched architecture. Each IPU-M2000 has a IPU-Links/ IPU-GW that allows the company to tunnel Gateway Links over 100GbE. The Gateway Links are the rack-to-rack communication links.
The company had two scaling benchmarks it was showing. The first is the scaling all the way to 256 nodes. Something that should be noted here is that while your eye may be drawn to the 95% scaling figure on the chart, just taking the images/ sec and dividing that by the IPU number actually means the waterfall is delivering about 25% efficiency loss going from the IPU-POD16 to IPU-POD256. We think the key that Graphcore is showing here is that it is taking less of a scaling hit from 128 to 256 than it does from 16 to 64 or 64 to 128.
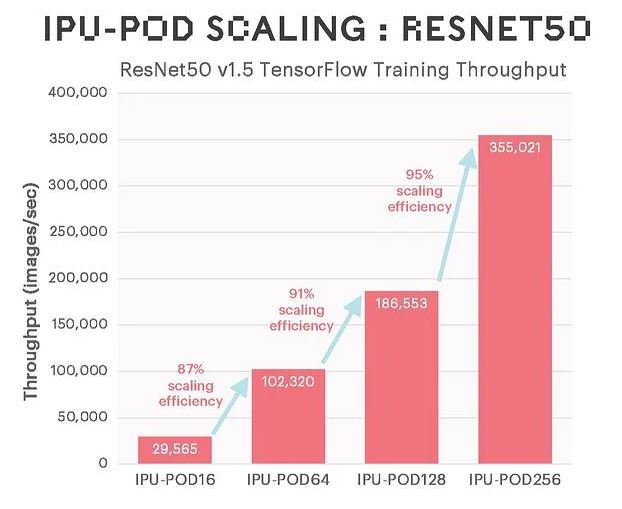
Graphcore also shared a ResNet50 result.
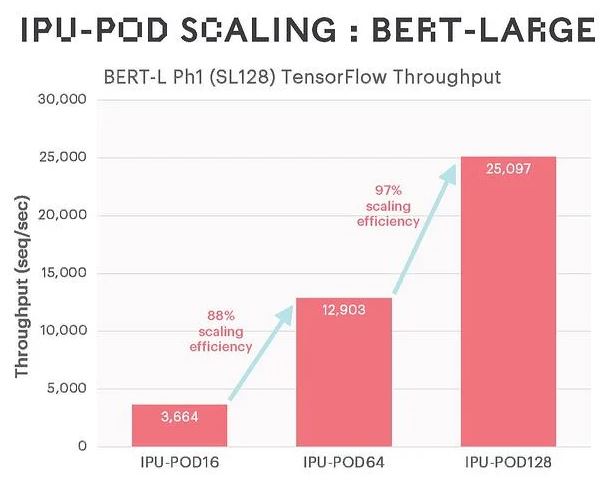
This one had better scaling but it is a bit strange to have in a release saying your system scales to 128 or 256 when you are presenting one of the two scaling efficiency charts without the 256 results.
Final Words
It is good to see Graphcore demonstrating a commitment to scaling. After Graphcore celebrated a stunning loss at MLPerf Training v1.0 the company needs to come up with a better storyline. That is not uncommon for startups. Doing this announcement outside of MLPerf allows them to share the story without having immediate direct comparisons which seems like a wise move by the company at this juncture.



{kind=link}