ASUS ESC A8A-E12U Topology and Block Diagram
In terms of the topology, one can see that there is a lot of PCIe I/O and three xGMI links. The three xGMI link design in AMD architectures allows for each CPU to use an additional x16 (32 total) root for PCIe.
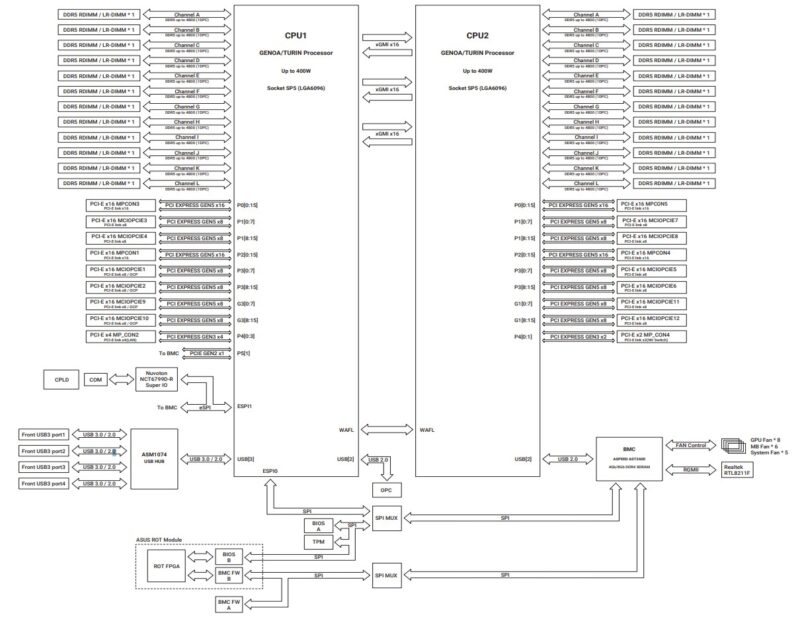
The implication of this design is that the goal is to push as much PCIe peripheral communication to avoid the links between the CPUs. There is a lot more bandwidth available to PCIe devices than there is between the AMD EPYC CPUs. This is the dominant way that AI systems are constructed these days.
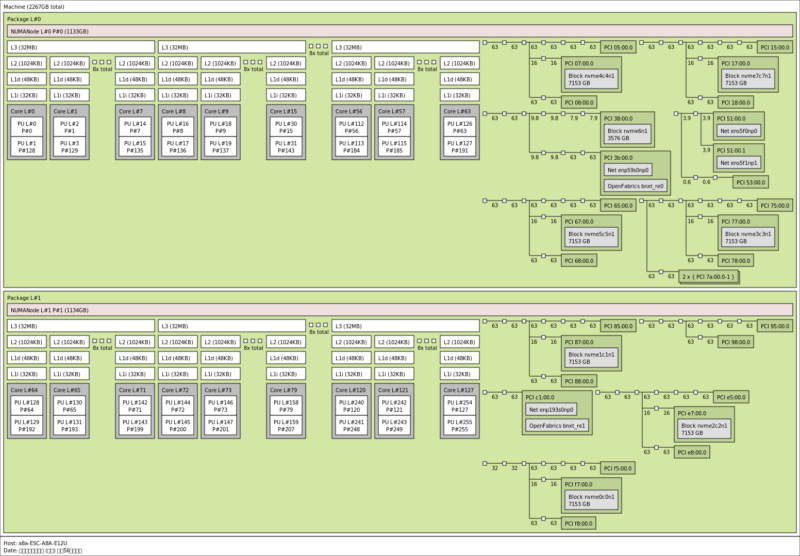
Still, it makes for a fairly massive topology diagram, which is always fun.
ASUS ESC A8A-E12U Management
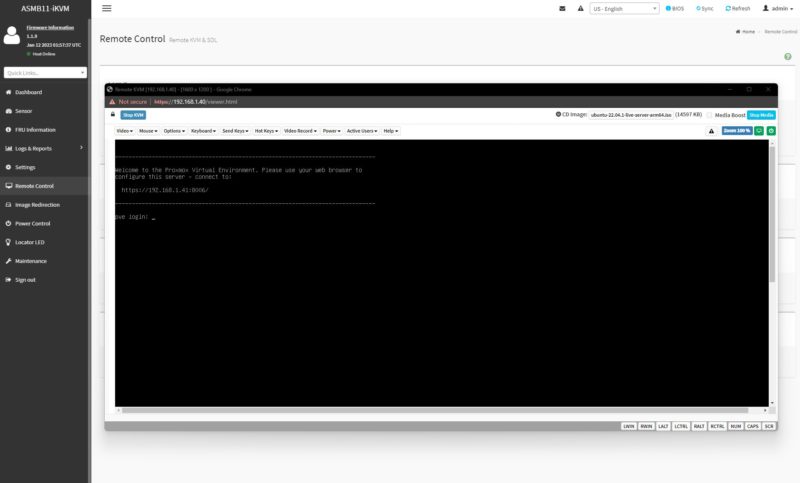
Running on this, we get the ASUS ASMB11-iKVM based on the industry standard MegaRAC SP-X.
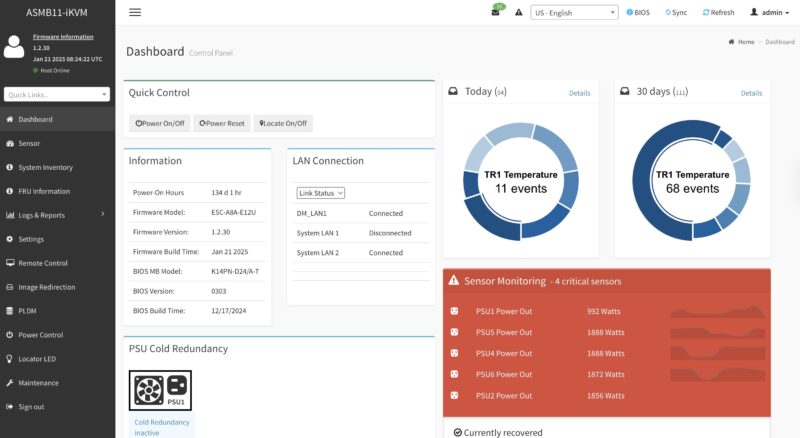
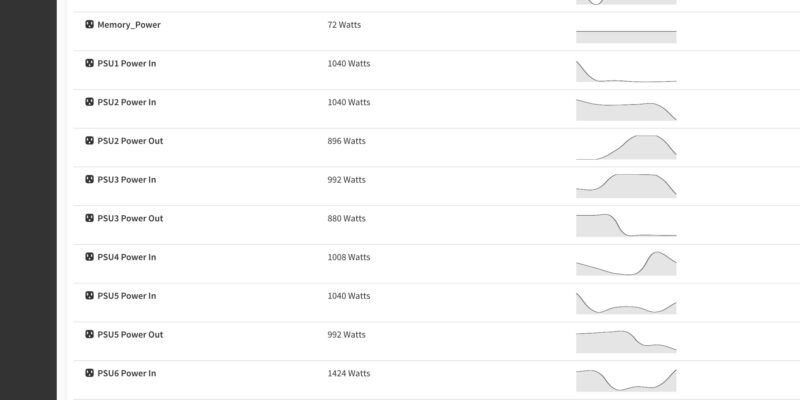
This allows monitoring of the various components in the system.
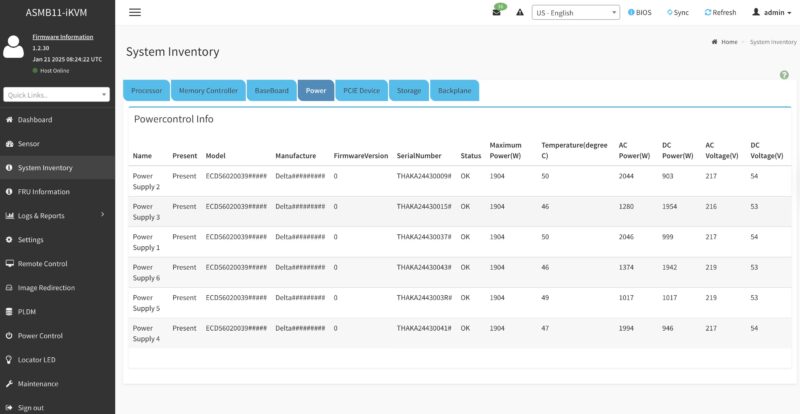
The BMC also has access to the telemetry data. While this may seem trivial, being able to get inventory and telemetry information on each machine is vital to operate and maintain these large AI systems.
Of course, we also get the HTML5 iKVM and other standard BMC features.
Next, let us get to the performance.
ASUS ESC A8A-E12U Performance
In terms of performance, we had dual AMD EPYC 9575F CPUs, which are popular 64-core models in this space because they also maintain a high frequency. There are often a few schools of thought regarding CPUs for these systems. Some go with the highest core counts, which we have here. Others go for lower core count but higher frequency parts. This is the second school of thought being implemented.
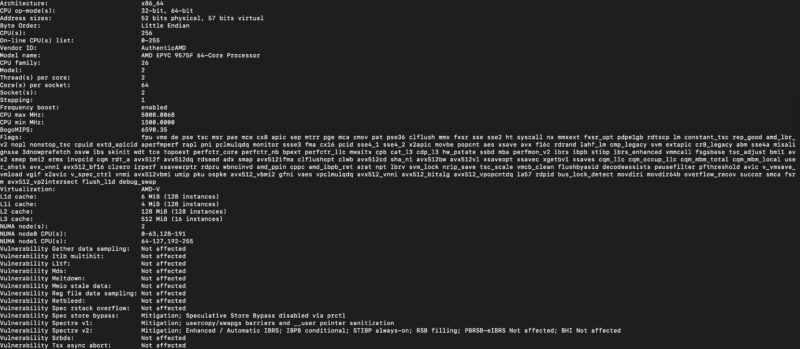
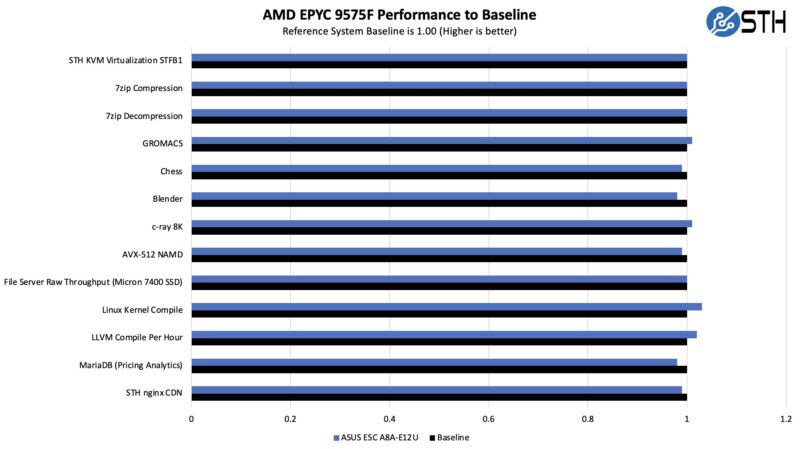
Still, we wanted to validate that we were getting the performance we would expect from the CPUs so we compared the performance to our reference 2U server:
One of the big challenges in these big AI servers is keeping the CPUs cool. ASUS is doing a good job in this area.
On the GPU side, we have been testing a number of these systems. We used vllm for Llama 3.1 and sglang for Deepseek-R1. On the LLama 3.1 side we used 128 input tokens and 2048 output tokens since that tends to be a sweet spot we found. We also used a batch size of 8 for our latency comparisons. On the Deepseek-R1 we were using the same 128/2048 and at a concurrency of 64 with the mean inter-token latency as our latency comparison point. Performance was on par with other systems.
Overall, here is what we saw.
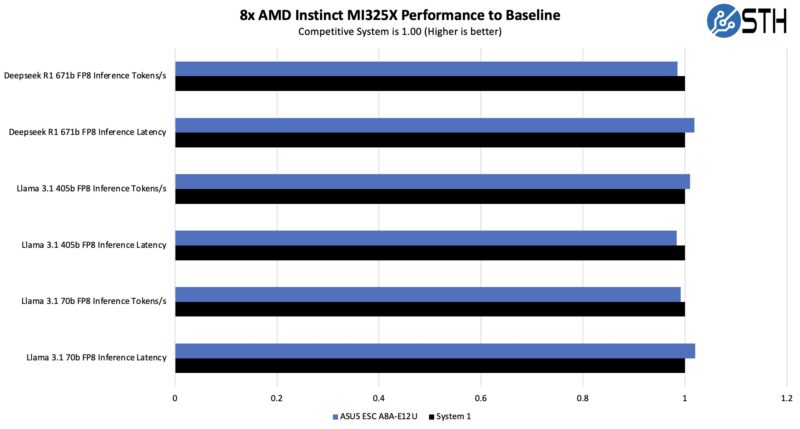
This is certainly good performance for the MI325X GPUs, so we know we are getting solid cooling.
Next, let us get to the power consumption.



{kind=link}
Also the image link for the image captioned: “ASUS ESC A8A E12U Llama 405B FP8 On AMD Instinct MI325X 5K Tokens Per Second” is wrong. It takes you to a picture of a 10GbE switch from a different review.