
It is little secret that machine learning and AI are driving a major arms race within data centers. NVIDIA got a major jumpstart on this market launching CUDA over 10 years ago. As a result, we are now seeing Intel make major plays in CPUs, many core chips, special Nervana chips, and FPGAs to keep the next generation of AI on its silicon. AMD has certainly not sat still but its approach of OpenCL first has lagged behind NVIDIA in terms of adoption. Furthermore, while NVIDIA has had several generations of compute only chips, AMD has focused on visualization. AMD is officially putting their hat in the ring with the new AMD Radeon Instinct card line.
Background
Here is how AMD views the machine learning world today:
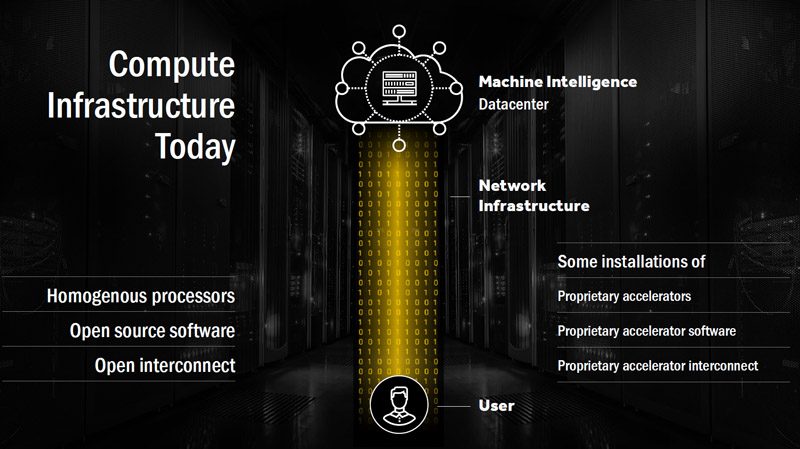
Going through the stack, “Network infrastructure” is primarily Mellanox and Intel. “Proprietary accelerator*” refers to NVIDIA CUDA and GPUs as well as FPGAs/ ASICs (Google’s Tensorflow). The proprietary accelerator interconnect we see as new technologies such as NVLINK not PCIe. Here is AMDs vision of the future:
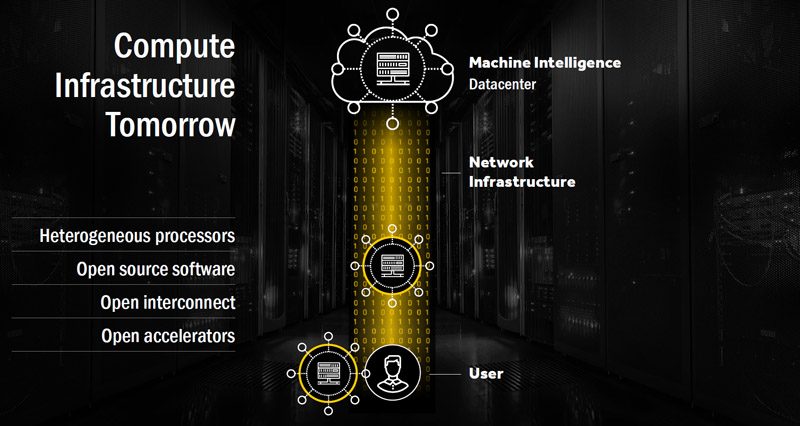
It is interesting that “heterogeneous processors” could be analogous to having CPUs as well as “proprietary accelerators” but that’s beside the point. AMD’s play hinges strongly on the software and interconnect sides working well with their technology.
Before we get to the new hardware, we wanted to quickly explore ROCm Software. ROCm is essentially AMD’s software solution to get developers to use its GPUs rather than simply using CUDA and/ or Intel’s MKLs to do machine learning.

We like the idea of ROCm but there’s a major obstacle. It is still in its infancy. If you head to the average website today virtually all of the learning materials are for doing machine learning on x86 CPUs or NVIDIA GPUs. We think that one potential win for AMD is that folks developing machine learning applications on Macbook Pro’s will want to use their onboard AMD Radeon GPUs for development. That could boost ROCm adoption.
Another very interesting part of this is that MxGPU is enabled on AMDs new accelerators. While the SRIOV virtualization is good, if this is the same technology found on the company’s VDI cards it also will mean a reboot is required to change core/ memory allocations do different partitions.

AMD’s value proposition is that this is free software.
The new AMD Radeon Instinct Cards
One item that AMD did really well on is naming the product. Instinct. It is at least something fresh beyond Tesla and GRID and Intel’s “exciting as a manilla envelope” accelerator branding. There are a total of three cards in the initial launch.

For these cards, we see a lineup from the MI6 (low power and lower performance) to the MI25 with the next-generation Vega architecture. We are excited to see how these cards perform. The MI8 is the middle-of-the-road option with much higher memory bandwidth.
We do think that in order to gain significant market share, AMD will have to give substantially better math performance on its lower-end “consumer” cards. Many of the high-end machine learning GPU clusters we have seen utilize consumer GPUs such as Titan X parts. By competing in the GTX 1070 to Titan X range AMD has an opportunity to attack the segment of the market NVIDIA has been handicapping in order to sell more expensive Tesla GPUs.
System Announcements
It seems as though AMD is taking note of a weak spot in its Opteron A1100 launch and launching the new Radeon Instinct systems through larger server vendors.
The first system we thought was familiar as the Supermicro SYS-1028GQ-TRT is a 1U server platform with up to four GPUs and two Intel Xeon E5 V4 processors. We reviewed the Supermicro SYS-1028GQ-TRT platform in August 2015.

This was a quick integration choice for the company as our test system had AMD FirePro S9150’s onboard. We were intrigued as to why we do not see newer 8 or 10 GPU 4U systems mentioned.
Also from Inventec there are larger GPU solutions available. One example is the Invtentec K888 G3 which is a 2U system with expanded storage and up to four GPUs.

The company also has a giant PCIe switch chassis that can hold up to 16x AMD Radeon Instinct MI25 GPUs.

Overall these systems are missing on major component, Zen. We did see a quad GPU setup there which may indicate up to 64x PCIe lanes. We also saw a NIC which is important.

Many folks may automatically assume that 64x PCIe lanes (per CPU) in a machine learning system will be used for 4x GPUs. The RJ-45 based NIC we believe is integrated 10GbE which we expect from the Zen Naples platforms and others in 2017. In most machine learning clusters you will see at minimum 40GbE but more often FDR or EDR Infiniband (and now Omni-Path) so we expect systems, without PCIe expanders to use some of their lanes for networking.
Final Words
AMD’s challenge with machine learning is that the software development community is using x86, CUDA, FPGAs/ ASICs first, and then AMD. There is little doubt that AMD can put together competitive GPUs. The challenge is getting all of the years of tutorials to iterate and include ROCm steps. Also, one must remember (as we pointed out at Intel AI day) that Intel and NVIDIA are funding much of the larger machine learning education programs. We do hope that AMD brings strong math capabilities to the lower-end of the market as it can deliver wins in an area that NVIDIA has been trying to handicap.



{kind=link}