
We covered the high-level AMD Instinct MI350 launch today, but AMD also shared some additional architectural details in a briefing we attended. We wanted to break those out for a dedicated piece around the new CDNA 4 architecture.
AMD MI350 and CDNA 4 Architecture Launched
The AMD Instinct MI350 platforms are based on the OAM UBB (Universal Baseboard), the industry’s standard 8-GPU form factor. The AMD Instinct MI350X air-cooled and MI355X liquid-cooled platforms use the UBB form factor but the liquid-cooled version can scale to 1.4kW with liquid cooling.

As a result, we get designs for up to 128x liquid cooled MI355X GPUs. That is sixteen UBB 8 GPU trays. Even at 2U each, that is 32U worth of GPUs. Even if you have 1U host nodes, that is 48U of rack space which is significant. Remember, the NVIDIA GB200 NVL72 rack is only 72 GPUs in a rack.

If you want to see rack scale integration on the NVIDIA GB200, you can check out our Dell AI Factory tour.
Racks scaling to 48U then 52U and beyond is not trivial since often it requires facility changes even on the manufacturing side.
For CDNA 4, AMD is moving more towards an AI optimization versus HPC FP64 compute which was a major focus in the original MI300 series.
While the new chips will use more power at the accelerator level, AMD says its new parts more than make up for that power delta in increased performance, especially at lower precision compute.

In many ways, the AMD Instinct MI350 is built in a similar manner to the MI300 and MI325 with the 3D Integration. The new accelerator compute die (XCD) is now on N3P process versus N5 in the previous generation. The I/O die (IOD) is between those XCDs and the interposer.

There are eight 32 CDNA 4 compute units per XCD. With eight XCDs that is 256 compute units total. You may note that is fewer than the full MI300X/ MI325X even with the N3P process shrink. AMD said that it added more compute to CDNA 4, so those are beefier compute units.

The IOD is different. Instead of having four IOD, there are two IOD in the package. Fewer IOD means that there is less opportunity to cross off of one IOD to another. Another way of looking at it is that each IOD now covers a larger compute and memory topology.
Here is the block diagram including the Infinity Fabric and Infinity Cache. You might notice that on the XCD there are several compute units that are different colors. AMD has additional compute units that it can use to help bin chiplets and increase yield by binning for the best CUs.
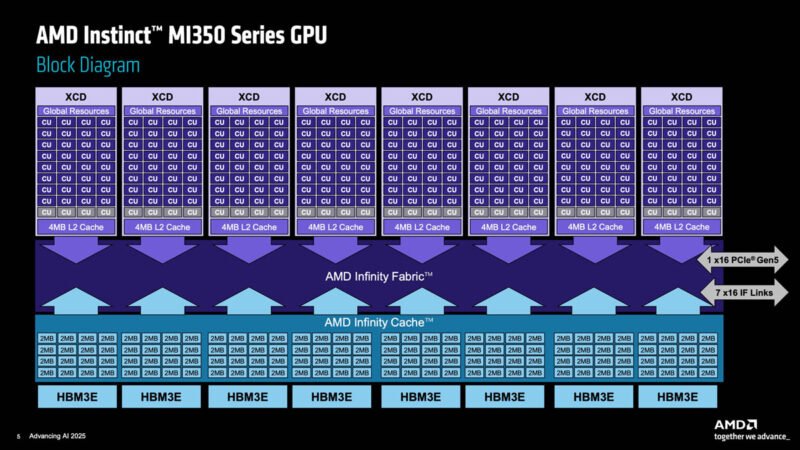
With more memory capacity, more data can be held on the accelerator at a relatively close distance from the compute. More memory capacity and memory bandwidth means that the performance of the accelerator can increase.

We are going to let you read through the slides, but AMD’s architectural change in the MI350 series was more about increasing memory capacity as well as memory bandwidth per compute unit, while increasing the lower precision compute capacity of the accelerator. You often hear about AI accelerators being limited as compute units wait for data. These architectural changes are designed to address that challenge.

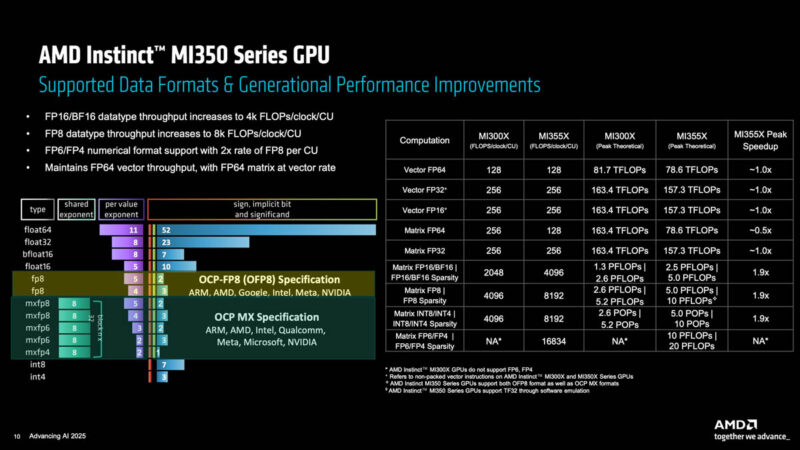
Here is the chart on compute formats and peak performance. The FP64 was not the focus. Instead, lower precision was the focus. A few notes. TF32 was not seen as being widely used, so it is now a software emulation option. Second, the FP4 and FP6 engine was added and AMD is putting a big focus on FP6. Instead of using the FP8 units and running FP6 through them, AMD is doing the higher performance (at a transistor cost) option of adding FP6 to the FP4 pipeline to give it a big boost.
Beyond the hardware, we also heard a lot on the software.
ROCm 7 Launched
AMD shared a ton of examples of how it both knows it has some way to go, but it is investing a lot in its software side. ROCm 7 is the next step in this journey supporting MI350. Beyond this though, AMD is also focused on making installing ROCm a pip install rocm experience.

AMD is also announcing not just ROCm 7 and fast performance, but also the AI Developer Cloud. The company also is launching its Enterprise AI efforts.
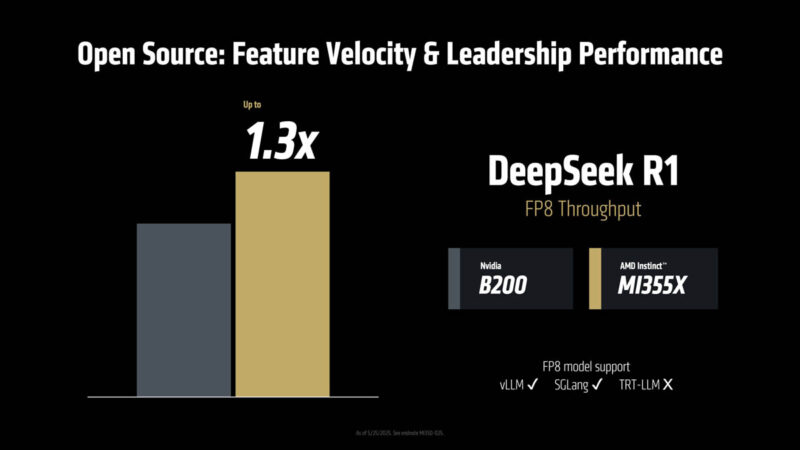
This is one of the benefits of shipping new generations regularly. AMD ROCm has a new mantra “Developers, Developers, Developers.” It is helping to give speed and access to compute for its developer community.
Something else that is important is that AMD is extending ROCm to notebooks later in 2025 to Red Hat EPEL, Ubuntu, OpenSUSE, Fedora, and even with full Windows support without needing WSL. That means if you have an AMD Ryzen AI MAX+ 395 system (our review is coming soon) running Windows, using ROCm will just work.
Final Words
There is a difference, of course, between what you can do on RDNA 3.5 and CDNA 4 as an example, but AMD is committing from developer workstation to data center. Between ROCm 7 and CDNA 4, it is clear AMD got the message that it needs to focus its technology on the needs of AI and also put some full-court press on its software. That is happening now.



{kind=link}