
Today, Amazon AWS Graviton3 instances hit GA, after being announced almost six months ago. This is a big event in the industry and we saw something truly interesting: the systems that these are being deployed on have three sockets per motherboard. That is quite uncommon, but we will go into why shortly.
Amazon AWS Graviton3 Hits GA
The AWS Graviton3 is the company’s newest chip that will power its new C7g instances and more as we move forward. The company says it gains 25% more performance per core but also has some additional acceleration for floating-point, crypto, and AI workloads.

Acceleration is important because that is going to be a key focus of chips going forward. We looked at the previous generation instances and why accelerators matter using Intel Ice Lake Xeons and Graviton2. We will likely do the same as the next generation of x86 instances launch later this year.
For those wondering what those chiplets are on the silicon, AWS says its new chips use 7 chipsets. The main compute die of Arm cores is in the middle. One can see this is the large monolithic compute die that one can see in the AWS diagram below. There are four memory channels that seem to have two DDR5 channels each. That will put them more in-line with Sapphire Rapids instead of Genoa. There are also two PCIe Gen5 chiplets.
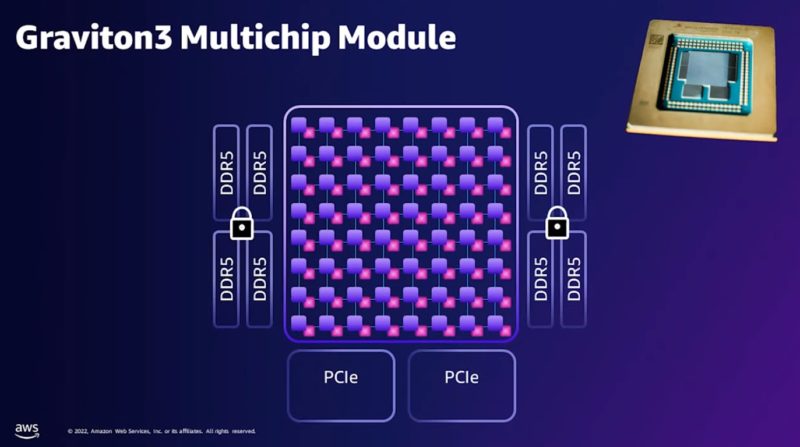
One interesting note is that AWS said one of the reasons that arrived at this breakout is that it allows the company to iterate portions of the design asymmetrically. So if it wants to upgrade to a new Graviton4 for a C8g instance, for example, it can just add a new compute die with more or faster cores. It can then re-use the DDR5 controllers and the PCIe Gen5 controllers and not have to re-design those chiplets. Intel struggled with PCIe Gen4 on 10nm so there is a good reason to design like this. Also, compute, cache, and I/O tend to get different efficiency scaling on new process nodes, so it should help with that as well.
Something that is important is that AWS says that by having a monolithic die and the chiplet DDR5 controllers it can offer more consistent latency than chiplet-based CPUs like Sapphire Rapids (four main compute dies as we showed) and AMD EPYC. While, as we see with AMD EPYC having external memory controllers is not necessarily the best for DDR performance, Amazon is less focused on outright per-core performance than it is on creating consistent platforms, even if that means consistently going over an extra memory tile hop.
The Graviton3 server design is really interesting. AWS is loading three sockets per server. Usually, we get 1, 2, or 4 sockets per server, but three is uncommon. If we have dual and quad-socket servers, Graviton3 is then a tri-socket server perhaps? The only link shown is through the Nitro networking interface so they seem like separate nodes.
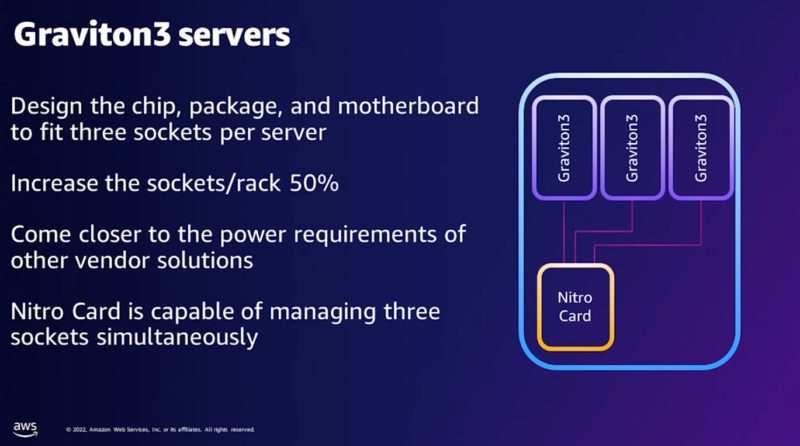
This is largely due to the fact it has its Nitro cards managing things like storage, networking, and security. You can see our AWS Nitro the Big Cloud DPU Deployment Detailed on why Nitro allows AWS to do things like this. It is also why we have been focusing so much on the rest of the industry’s efforts to catch up with Nitro. We even did a piece on the BlueField-2 DPU to help more folks understand it.
While today is the GA day for the AWS Graviton3-based EC2 C7g instances, we can expect Amazon to fill out more of its line with the new chips in the coming quarters.

Here are the new AWS C7g instance specs from Amazon:
| Instance Name | vCPUs |
Memory |
Network Bandwidth |
EBS Bandwidth |
| c7g.medium | 1 | 2 GiB | up to 12.5 Gbps | up to 10 Gbps |
| c7g.large | 2 | 4 GiB | up to 12.5 Gbps | up to 10 Gbps |
| c7g.xlarge | 4 | 8 GiB | up to 12.5 Gbps | up to 10 Gbps |
| c7g.2xlarge | 8 | 16 GiB | up to 15 Gbps | up to 10 Gbps |
| c7g.4xlarge | 16 | 32 GiB | up to 15 Gbps | up to 10 Gbps |
| c7g.8xlarge | 32 | 64 GiB | 15 Gbps | 10 Gbps |
| c7g.12xlarge | 48 | 96 GiB | 22.5 Gbps | 15 Gbps |
| c7g.16xlarge | 64 | 128 GiB | 30 Gbps | 20 Gbps |
One interesting note here is that the maximum vCPUs is only 64 so it does not seem like AWS is focusing on delivering instances that span multiple Graviton3’s at the moment. The Graviton3’s may be on the same motherboard, but it appears as though they are being treated as separate nodes. If they were all in the same node, we would likely have >64 core instances.
AWS is also spending resources to bring its managed services to Graviton as it increases vendor-lock in by having proprietary hardware and software solutions. AWS is following the path largely abandoned by companies like IBM and Sun-Oracle in previous eras.
This is a big change in the AWS business model and Amazon has a design philosophy that will help it accelerate its pace of innovation in the future.
Final Words
Overall, this is a very cool launch with the new tri-socket servers. Amazon is leading the way with Arm server infrastructure and cloud infrastructure in general. Looking back, the Annapurna Labs acquisition has done a lot to transform the AWS infrastructure as well as the industry. By making its own server chips, and driving low margins from vendors, it is able to price its own silicon offerings lower than others in its cloud and in the market to increase adoption of a platform without direct alternatives.
Still, there is a lot more coming this year in terms of server processors and Graviton3 will be nowhere near the fastest we will see. That is not Amazon’s goal. Amazon is more focused on instance performance and consistency on an array of Arm cores than on driving the maximum per-core performance. It is certainly an interesting model.
Still, this is a very exciting day indeed.

Note: Added a fun picture for the Twitter comments.


{kind=link}
Indeed, there are no cross-socket links. The three servers run fully separate OSes with the shared part being the Nitro card.
If you’d like to communicate to another node on the same server, you can use RDMA through Amazon EFA (like if it was on another machine entirely), going through the DPU.
But you have zero guarantees that two VMs that you start will end up on the same server anyway.
The reasoning for the tri-socket setup is likely more straight forward than you think: it’d be the full width of a rack when the memory slots are included.
The usage of Nitro is interesting but nothing new to this market: it is effectively a service processor for the bigger chips. Main frame architecture would delegate IO tasks to coprocessors so that more time would be freed upon general CPUs to crunch additional data. Similarly, the main frame architectures of old wouldn’t run the hypervisor either for similar reasons: freeing up main CPU cycles.
Graviton isn’t really a lock-in. You can always recompile your code and run it on another platform. I have Xeon, Epyc, and Graviton systems in production.
Triad or ternary tablature?
But a Z system isn’t running a different image on coprocessors.
@Mark Rose that’s only if you have the code to compile. If you’re running a managed service on Graviton you aren’t running it on another cloud vendor.
For a mixture of floating-point and integer computations that include a prime sieve, sorting, Fourier transform and a dynamical simulation I find the Graviton 3 to be about 1.7 times faster than the Graviton 2 and 3.3 times faster than the original Graviton.
On the same benchmark the Graviton 3 appears 1.4 times faster than the ARM Altra-based instances in the Oracle cloud.
I wonder how the per-core speed compares to the performance cores from Apple.
Moved over to G7 and it has been a dramatic shift from G6. In fact dropped down 1 instance size and still achieving 60% improvement over G6. Something doesn’t compute, but loving the performance.
Comments are closed.