
Marvell’s Hot Chips 32 (2020) presentation is nothing short of fascinating. We have covered the Marvell ThunderX3 a few times already. The reason it is fascinating is not that we know it will have more cores. Instead, it is fascinating because Marvell is doing more disclosure on the ThudnerX3 than we have seen in previous generations. For example, I spoke at the Marvell (then Cavium) ThunderX2 launch, and I never had access to the level of microarchitectural diagrams that Marvell is sharing at HC32. Later, we will discuss why this is likely the case.
Marvell ThunderX3 Overview
Looking at the key ThunderX3 features, we can see up to 60 cores in a single die and 96 cores in dual die per socket solutions. As with previous generations, we get SMT=4 which means we can get 240 threads in a single die and 384 threads in dual die configurations. Marvell is moving to more modern infrastructure including Arm v8.3, DDR4-3200, PCIe Gen4 (64 lanes.) It will be built on TSMC 7nm.
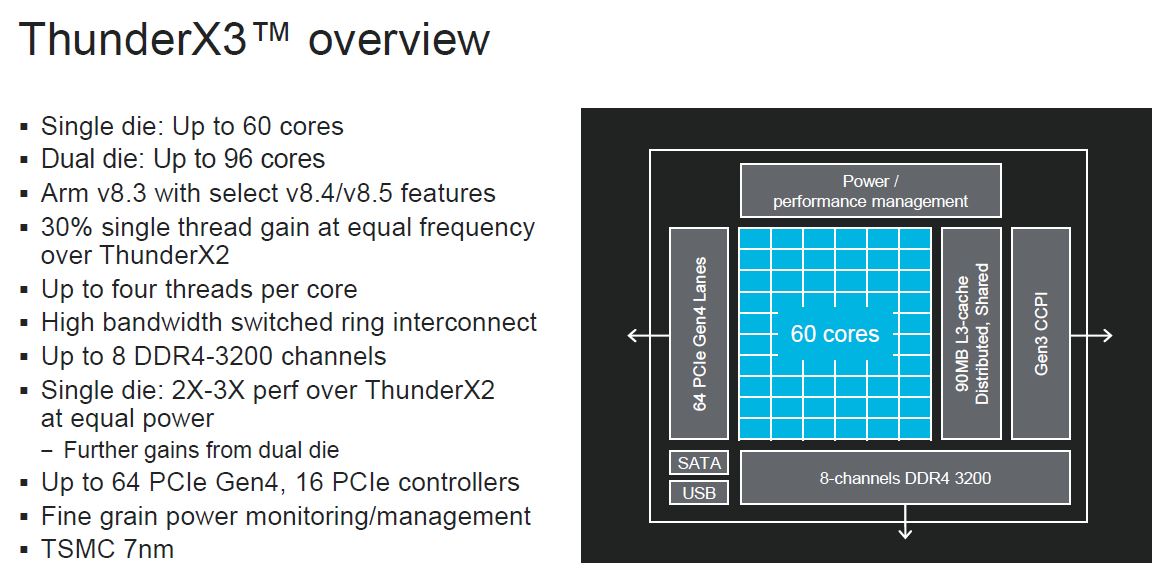
Here is the ThunderX3 block diagram. One can see the basics of how the chips work from this.
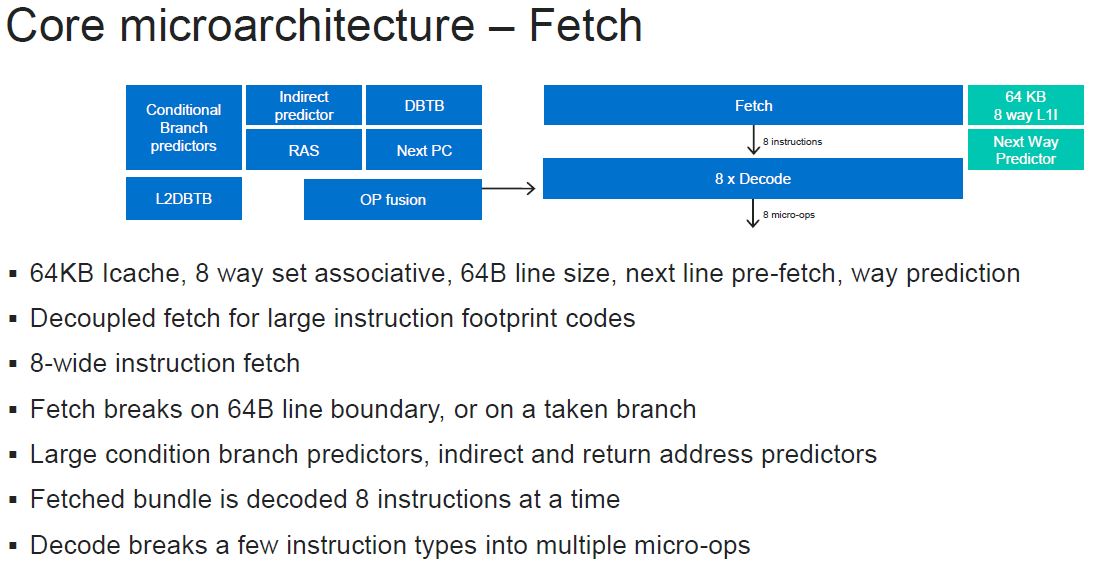
Here is the fetch diagram. The decoupled cache is an improvement over ThunderX2 and is designed to help keep fetching data while waiting for misses. The advantages are that the pipeline stays more full with this solution.
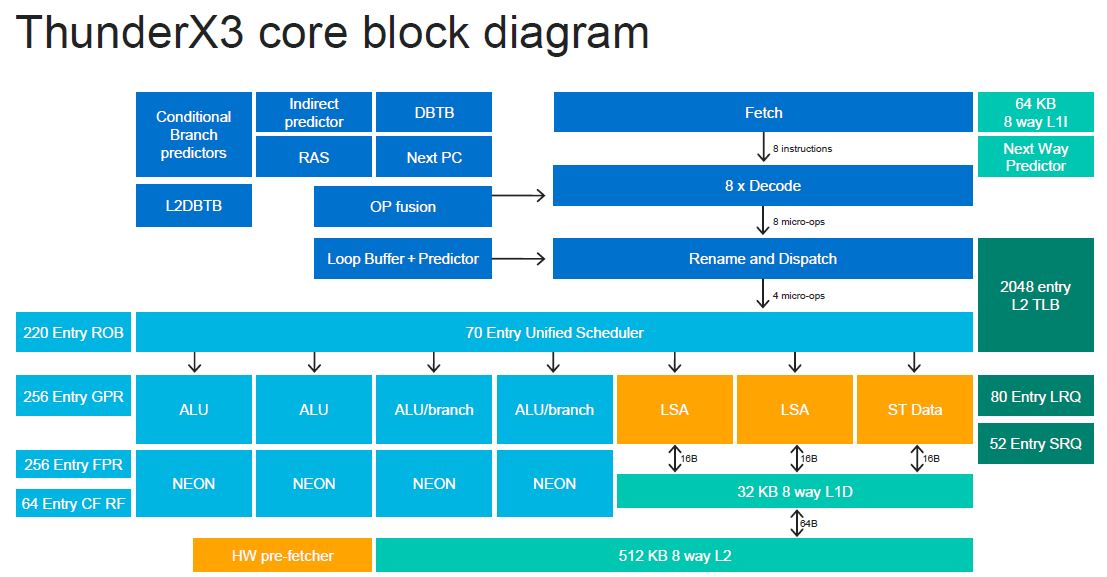
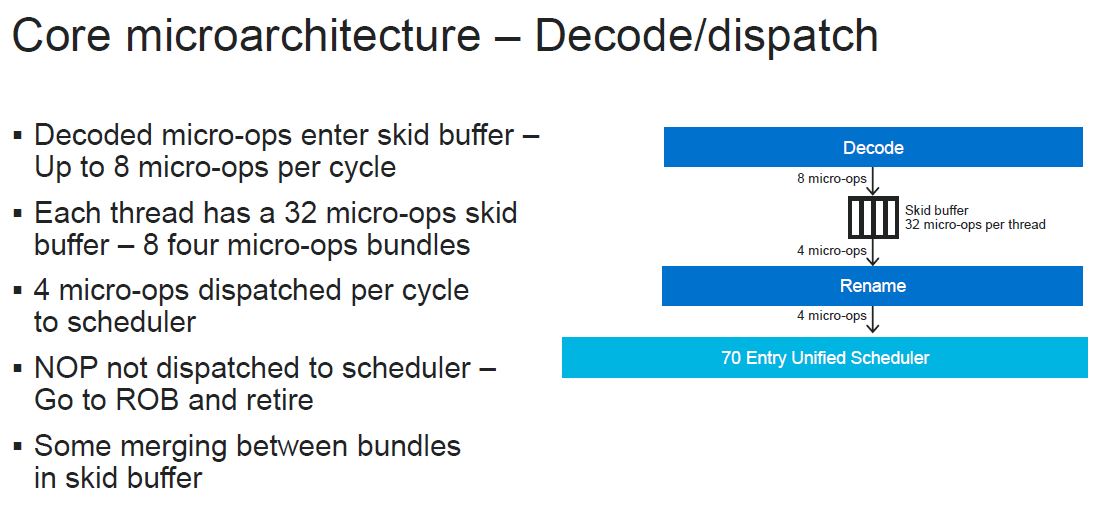
Here is the decode/ dispatch which we are going to let our readers simply read here.
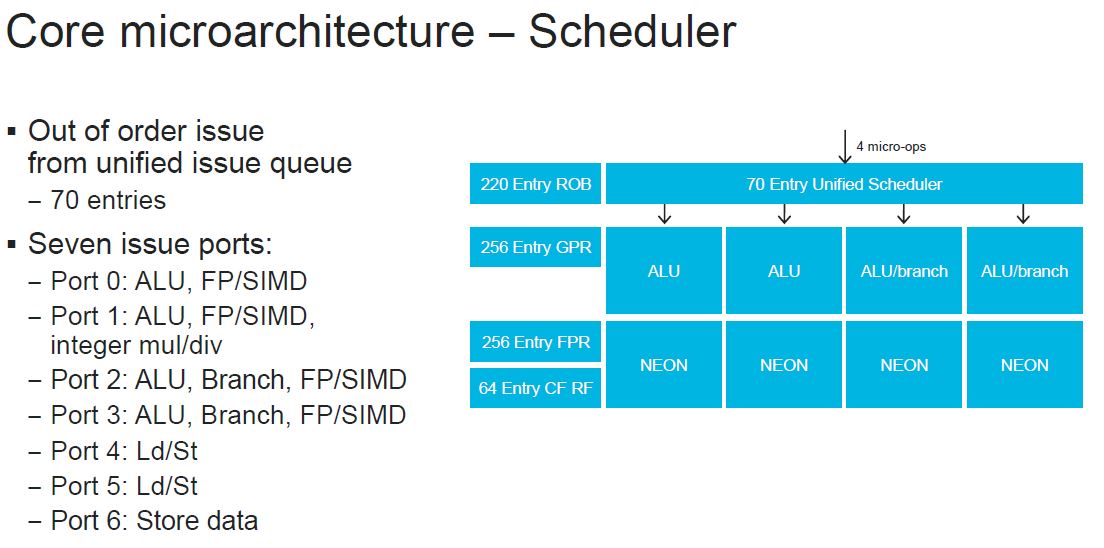
Here is the scheduler. These are relatively deep structures.
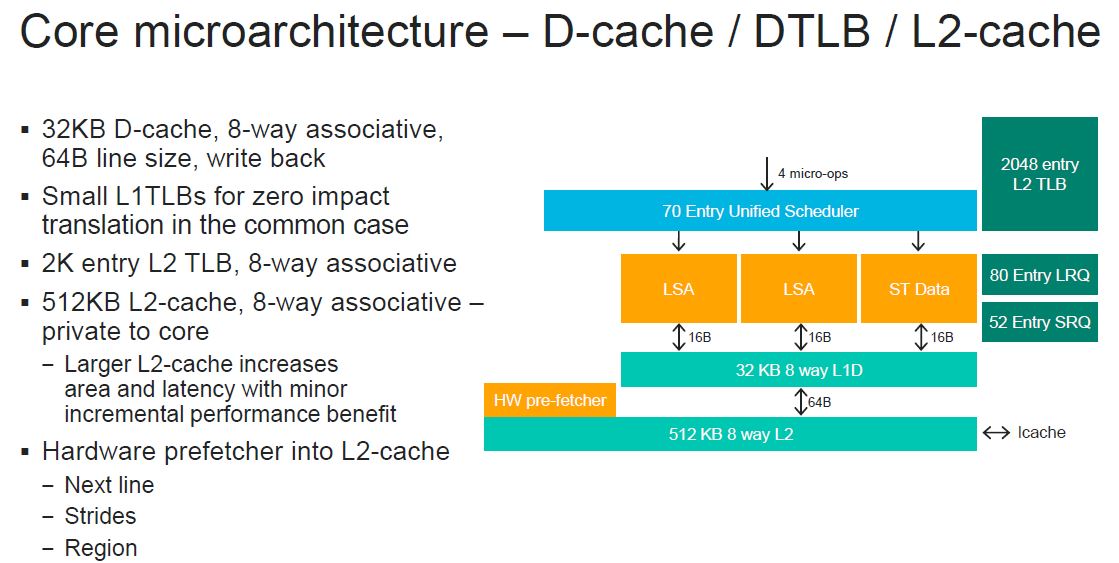
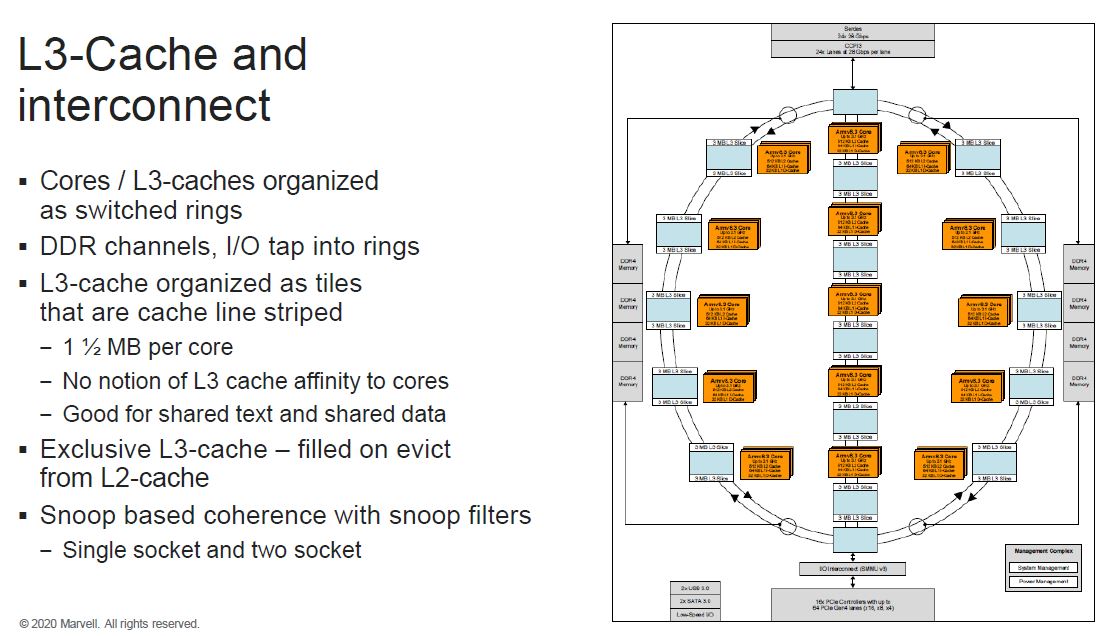
Marvell did more work on its caching and prefetchers with this generation. Here is the d-cache and L2 cache diagram:
Overall, here is where the performance improvements and how they give around a 30% gain overall in SPEC_int.

Here, Marvell is saying that its 4-way SMT implementation only adds around 5% area impact. The key feature here is that Marvell is saying that adding SMT is a relatively low-cost performance boost compared to adding more cores. That is important from a competitive perspective.

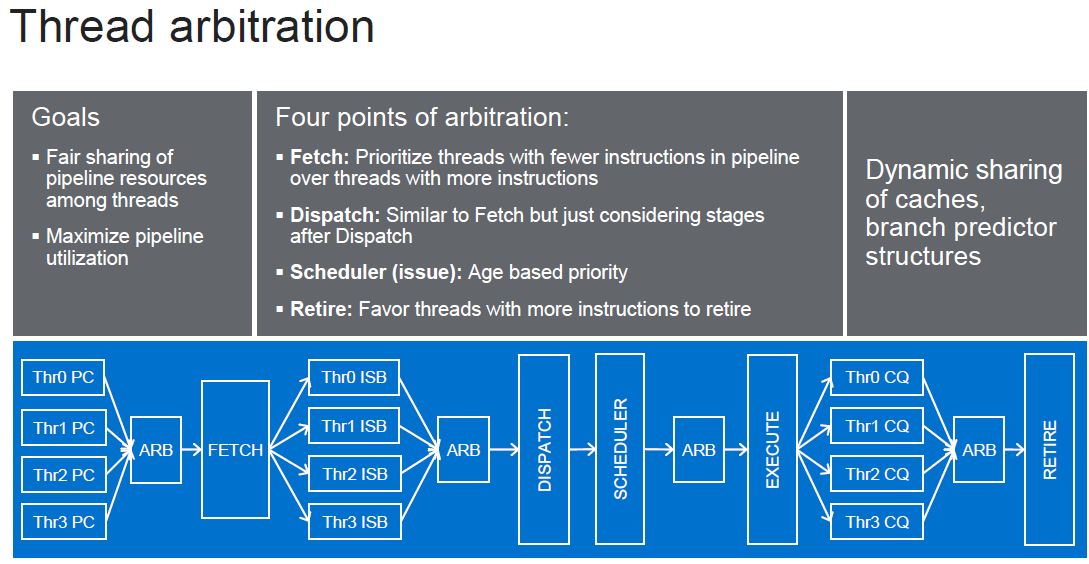
Since it has competition discussing how no SMT is better, largely because stock Arm Neoverse cores do not support it, Marvell is discussing its thread arbitration in terms of how it keeps the pipelines full.
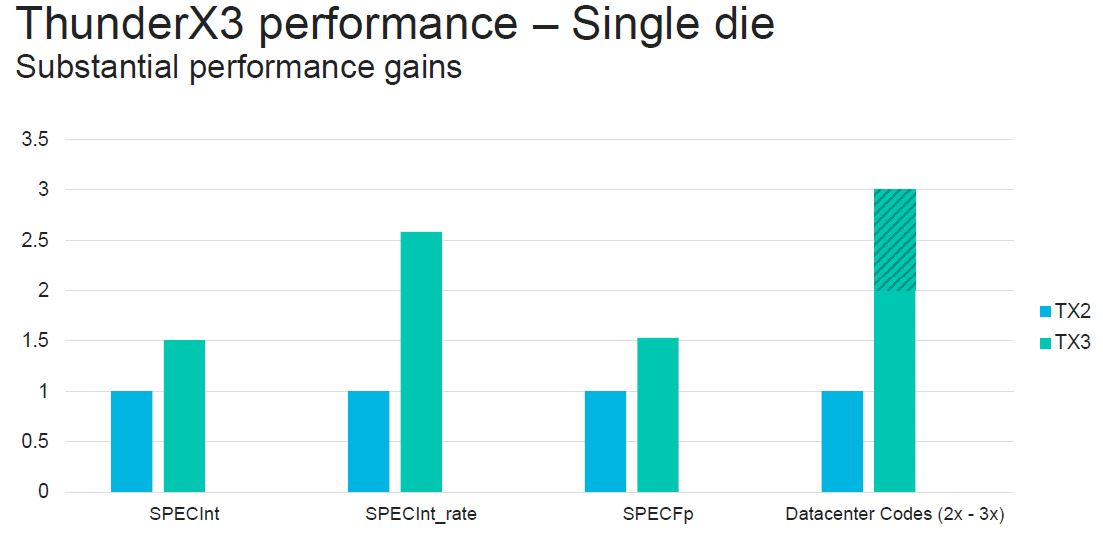
With these cumulative improvements, plus scaling to more cores, Marvell expects large gains. One of the more interesting bits here is that on SPECfp there is only a 50% improvement. Perhaps Marvell is getting TDP limited. Still, this is a significant improvement.
To hammer home how much that 5% die impact for SMT helps, Marvell, is sharing single-core benchmarks to show speedup by moving to higher thread counts.

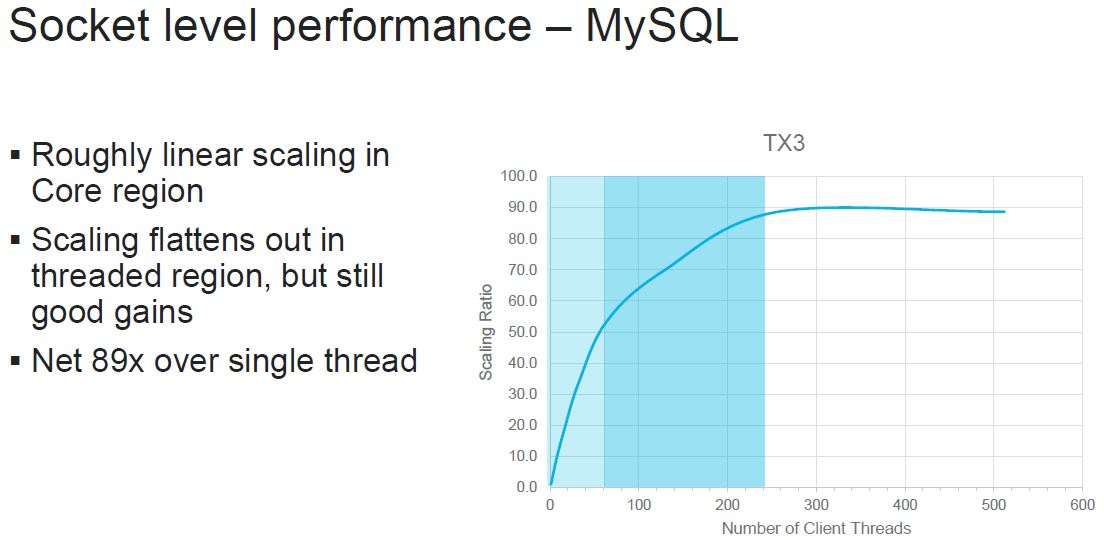
Marvell picked the best of those three and is showing MySQL performance where it gets a large SMT performance boost.
The L3 cache is 1.5MB per core. That is more similar to an Intel Xeon CPU rather than an AMD EPYC 7002 CPU. Marvell is focusing on Intel as its x86 comparison point. While it is moving to multi-die similar to IBM Power10, it is also not going to the level of disaggregation that AMD has pioneered.
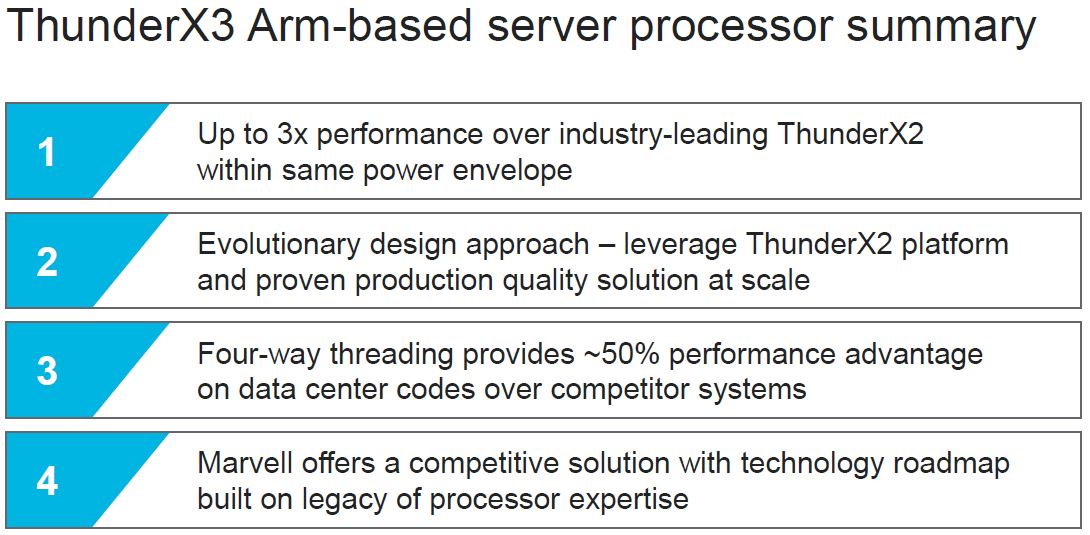
Just to hammer home the competitive approach, we see not just the benefits of ThunderX3, but also a defense of SMT=4 in the summary.
This is one of the early examples of Arm marketing targeting another Arm architecture.
Marvell ThunderX3 Roadmap
On the roadmap side, Marvell will have the single die solution in 2020, the dual die in 2021, and then is working on ThunderX4 for 2022. We suspect ThunderX4 will be a 5nm chip since process technology should shift by then.
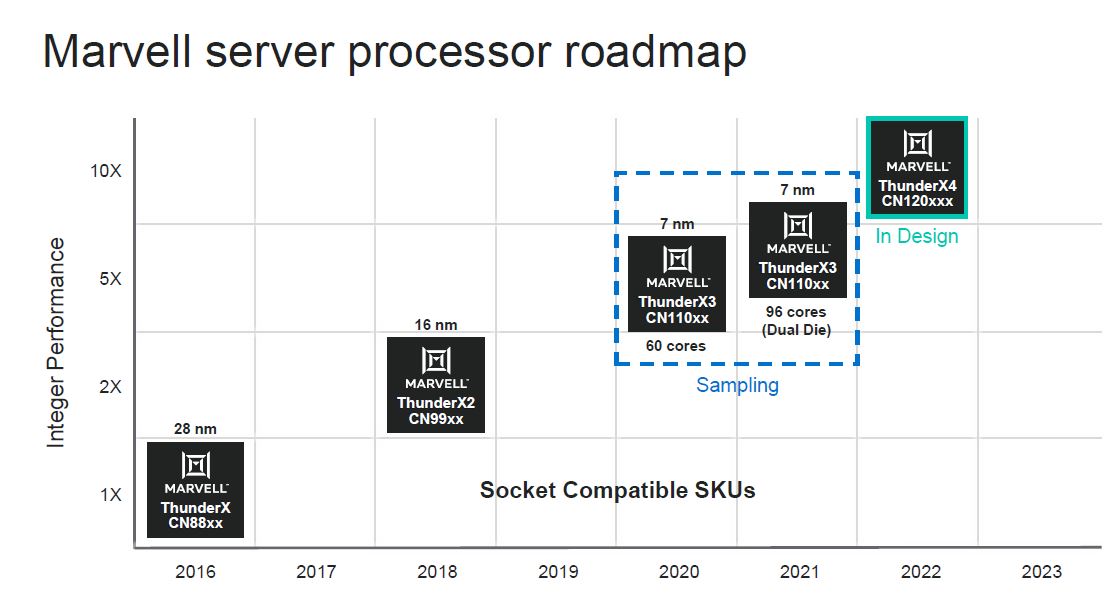
We asked Marvell prior to Hot Chips to give more firm timeframes on when ThunderX3 will be available. Marvell declined to give timing. To us, that likely means that we are going to see Ampere Altra in the lab, in a production (non-development) system well before ThunderX3.
Final Words
There are a few great tidbits here. First, Marvell is finally opening up more about ThunderX architecture. Just for some context to see how much more disclosure this is, here is the ThunderX2 block diagram from our Cavium ThunderX2 Review.

Perhaps the other interesting bit is how much the presentation resonated as a competitive piece Arm v. Arm. This is a new competitive vector we have not really seen over the years. Traditionally Arm server chip marketing was Arm v. x86, or specifically Intel x86 Xeons. This presentation was a very thinly veiled response to the Ampere Altra and Ampere Altra Max CPUs. It is great to see enough uptake that there is now a sense of competition on the Arm side as well.


 we get a deeper look into the Marvell ThunderX3. Something interesting is that we are now seeing Arm v. Arm marketing efforts){kind=link}