
Yesterday, Intel sent us one bit of news about the TACC Stampede3 4PF Using Intel Xeon Max and 400Gbps OPA but announced something much bigger. Intel is taking its architecture to a new level with the new Intel Advanced Performance Extensions (APX) and a new AVX10. This is big news for the future of x86.
Intel APX Advanced Performance Extensions
Intel APX is the new set of extensions that are designed to improve general-purpose compute. One of the biggest is the additional registers. Unlike new instructions like AVX-512 and AVX10, this should help even general-purpose integer workloads. For Intel APX, here is the description from Intel:
Intel Advanced Performance Extensions (Intel APX) expands the Intel 64 instruction set architecture with access to more registers and adds various new features that improve general-purpose performance. The extensions are designed to provide efficient performance gains across a variety of workloads without significantly increasing silicon area or power consumption of the core.
The main features of Intel APX include:
- 16 additional general-purpose registers (GPRs) R16–R31, also referred to as Extended GPRs (EGPRs) in this document;
- Three-operand instruction formats with a new data destination (NDD) register for many integer instructions;
- Conditional ISA improvements: New conditional load, store and compare instructions, combined with an option for the compiler to suppress the status flags writes of common instructions;
- Optimized register state save/restore operations;
- A new 64-bit absolute direct jump instruction. (Source: Intel)
There is a lot of good here.
Intel AVX10
The other big announcement is the AVX10 instructions. This is the new update for vector instructions on Intel CPUs past AVX-512.
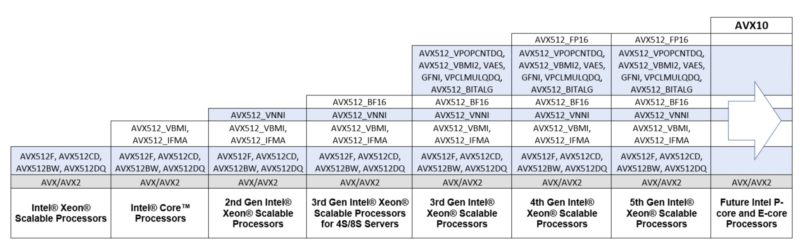
Intel Advanced Vector Extensions 10 (Intel AVX10) represents the first major new vector ISA since the introduction of Intel Advanced Vector Extensions 512 (Intel AVX-512) in 2013. This ISA will establish a common, converged vector instruction set across all Intel architectures, incorporating the modern vectorization aspects of Intel AVX-512. This ISA will be supported on all future processors, including Performance cores (P-cores) and Efficient cores (E-cores).
The Intel AVX10 ISA represents the latest in ISA innovations, instructions, and features moving forward. Based on the Intel AVX-512 ISA feature set and including all Intel AVX-512 instructions introduced with future Intel Xeon processors based on Granite Rapids microarchitecture, it will support all instruction vector lengths (128, 256, and 512), as well as scalar and opmask instructions. A “converged” version of Intel AVX10 with maximum vector lengths of 256 bits and 32-bit opmask registers will be supported across all Intel processors, while 512-bit vector registers and 64-bit opmasks will continue to be supported on some P-core processors.
The Intel AVX10 architecture introduces several features and capabilities beyond the Intel AVX2 ISA:
- Version-based instruction set enumeration.
- Intel AVX10/256 ? Converged implementation support on all Intel processors to include all the existing Intel AVX-512 capabilities such as EVEX encoding, 32 vector registers, and eight mask registers at a maximum vector length of 256 bits and maximum opmask length of 32 bits.
- Intel AVX10/512 ? Support for 512-bit vector and 64-bit opmask registers on P-core processors for heavy vector compute applications that can leverage the additional vector length.
- Embedded rounding and Suppress All Exceptions (SAE) control for YMM versions of the instructions.
- VMX capability to create Intel AVX10/256 virtual machines that provide a hardware enforced Intel AVX10/256 execution environment on an Intel AVX10/512 capable processor. (Source: Intel)
This is a big deal since it will allow for AVX-512 on both P-cores and E-cores specifically, Granite Rapids will have an implementation of some features forward compatible with AVX10.1.
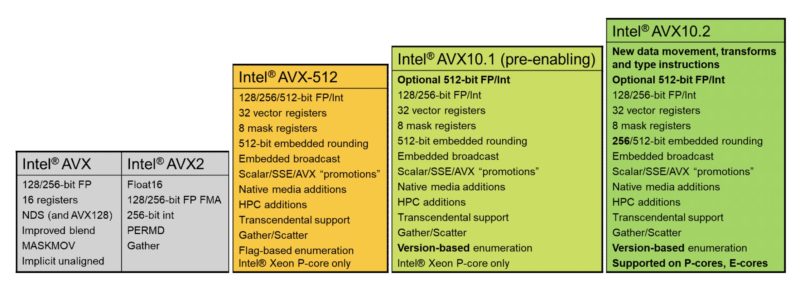
Intel AVX10 Version 1 will be introduced for early software enablement and supports the subset of all the Intel AVX512 instruction set available as of future Intel Xeon processors with P-cores, codenamed Granite Rapids, that is forward compatible to Intel AVX10. This version will not include the new 256-bit vector instructions supporting embedded rounding or any of the new instructions and will serve as the transition base version from Intel AVX-512 to Intel AVX10.
Intel AVX10 Version 2 will include the 256-bit instruction forms supporting embedded rounding as well as a suite of new Intel AVX10 instructions covering new AI data types and conversions, data movement optimizations, and standards support. All new instructions will be supported at 128-, 256-, and 512-bit vector lengths with limited variances. All Intel AVX10 versions will implement the new versioning enumeration scheme. (Source: Intel)
This is a big ISA improvement since it is how Intel will be able to support higher-end vector compute on both P-cores and E-cores going forward. We expect AVX10 to be the main development target for optimizations once Intel gets its hardware out and the transition happens.
Final Words
Overall, these should be net positive changes for x86. Higher general-purpose performance and a refined vector compute strategy will help Intel build more efficient processors in the future while also managing the complexity of integrating P and E cores in the data center. Something that is under-appreciated in the data center is that having P-cores with a significantly different set of AVX features versus its E-cores is a challenge for virtual machines. AVX10 is going to be a way to help that while also providing more capabilities to desktop CPUs.
If you want to learn more about APX and AVX10, you can find links on the Intel Advanced Performance Extensions page.


{kind=link}
APX won’t add a lot of performance but any overhead shrinking is good news:
Modern x86 have a lotmore than 32 INT registers (GP) but only 16 are exposed and the rest is used through register renaming. This is not changing too much regarding “real”/internal load/store.
It’s hard to see this as anything else than Intel making these changes because they have to rather than that they want to. Overall it’s a negative for the industry because it adds further segmentation and confusion on supported features, will undoubtedly have early adopter issues and overall seems to offer very little performance uplift at a real additional cost to Intel, either by increasing die size (for E cores) or by maintaining another branch of features in an already bloated and non-uniform ecosystem.
Does this change actually do anything to bridge the P-core/E-core gap?
“A “converged” version of Intel AVX10 with maximum vector lengths of 256 bits and 32-bit opmask registers will be supported across all Intel processors, while 512-bit vector registers and 64-bit opmasks will continue to be supported on some P-core processors.”
It sounds like future E-cores are getting some changes; but that they are going from “E-cores don’t do AVX-512” to “Everybody does AVX10! Except that 512-bit features are an optional component of AVX10 that only P-cores do…”
Will a system where some of the AVX10 cores have the optional features and others don’t actually be meaningfully less heterogeneous than one where some cores have AVX-512 and some don’t?
As I understand it, in a hybrid system (or client platforms in general) they will just limit the P-cores to 256 bits.
Comments are closed.