
After publishing the Over 2000 SPEC CPU 2017 Results Flagged for Compiler Optimization piece yesterday, we have more details to share and a good example of the impacts. As a result, we thought we would share a quick follow-up piece.
Impact of Intel Compiler Optimizations on SPEC CPU2017 Example
Just for some context, while we said in our original piece that it is “over 2000” results, it appears as though it is over 2500 results that are impacted. These results have the following note added to them:
Compiler Notes
SPEC has ruled that the compiler used for this result was performing a compilation
that specifically improves the performance of the 523.xalancbmk_r / 623.xalancbmk_s
benchmarks using a priori knowledge of the SPEC code and dataset to perform a
transformation that has narrow applicability.
In order to encourage optimizations that have wide applicability (see rule 1.4
https://www.spec.org/cpu2017/Docs/runrules.html#rule_1.4), SPEC will no longer
publish results using this optimization.
This result is left in the SPEC results database for historical reference. (Source: Spec.org)
The SPEC CPU2017 integer rate 523.xalancbmk_r and speed 623.xalancbmk_s benchmarks were found to be impacted by a specific optimization in the Intel compiler. It seems as though these optimizations were in the 2022 version of the compiler, but the latest 2023.2.3 version that was generally used for the latest 5th Gen Intel Xeon “Emerald Rapids” launch no longer had the optimizations. Given 2022-2023 timeframes, most of the impacted results seem to be 4th Gen Intel Xeon “Sapphire Rapids” results.
While things like the die configuration, core counts, and memory speeds have changed between the Sapphire Rapids and Emerald Rapids generations, the cores themselves are essentially the same. As a result, we would expect most workloads, including SPEC CPU2017 to scale with clock speed.
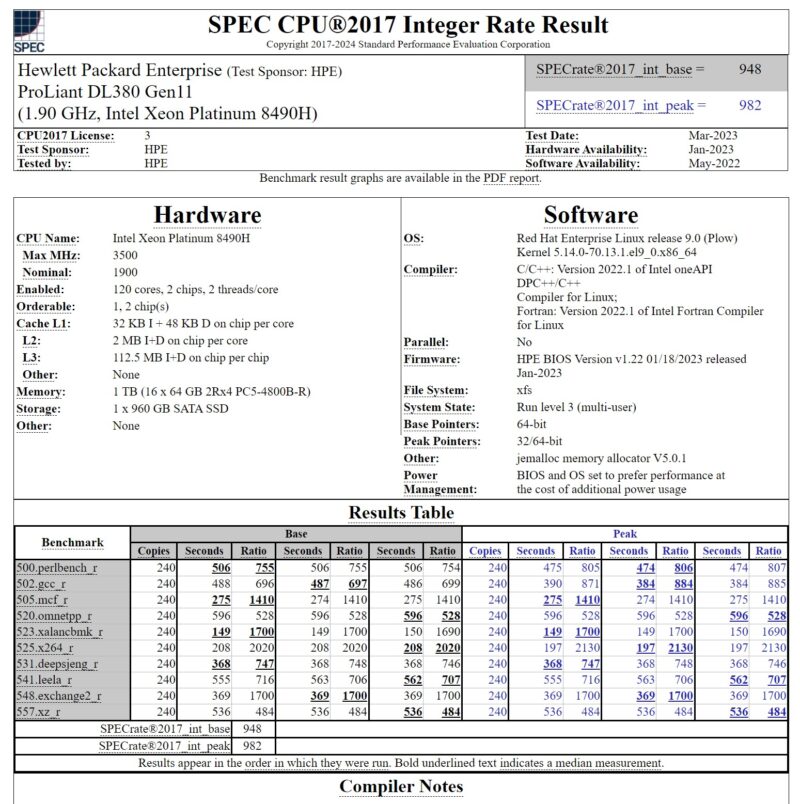
Here are just two examples of this. First, here is an impacted result from HPE using two Intel Xeon Platinum 8490H 60-core processors.
Here is an example of the Dell PowerEdge C6620 with the newer compiler that does not have this optimization and two 60-core Intel Xeon Platinum 8580 processors.
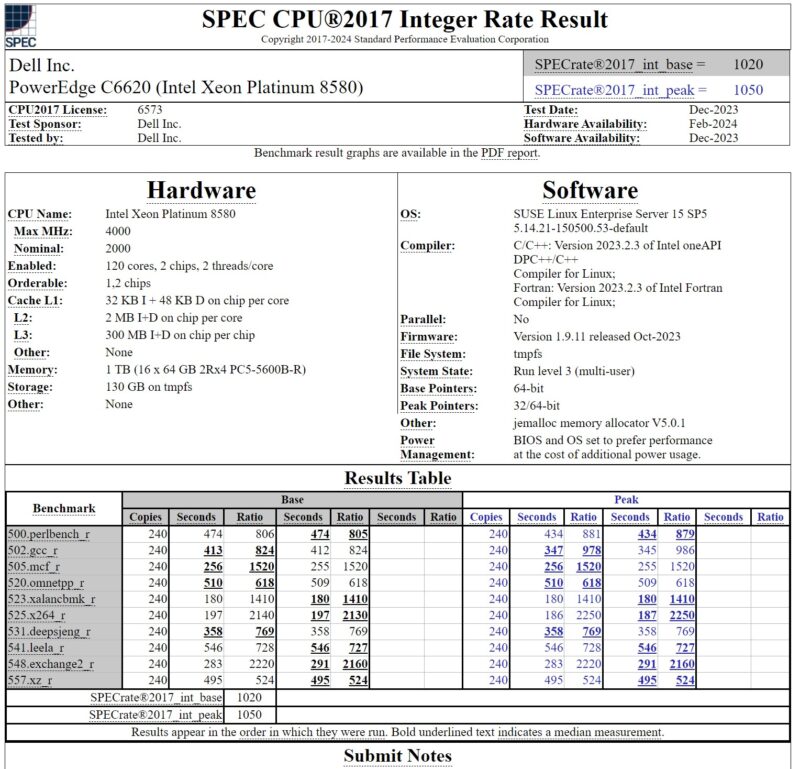
If you compare the two sets of results, the newer and higher clock speed parts with almost identical core architectures across the board are faster in 9 of the 10 tests. That makes sense. The one benchmark that stands out is the 523.xalancbmk_r result line for both. Here, there is a pronounced drop in performance on the newer faster part with the compiler that excludes the optimization in question. Based on the architecture, we would expect this to be faster. The Platinum 8580 has a 100MHz higher base clock and a 500MHz faster max turbo frequency, and we generally see it runs at higher clock speeds in the same servers we test. It is a faster part.
Also, the PowerEdge C6620 is a newer version of an old STH favorite Dell PowerEdge C6100 XS23-TY3 Cloud Server we worked with over a decade ago. We would not expect a 2U multi-node server to have a performance advantage over a 2U single-node server, even in the highly optimized environments vendors use for these benchmarks.
Final Words
Overall, it seems like Intel got single-digit percentage higher results in its Sapphire Rapids generation due to this optimization in its older compiler generations. The timing is also a bit interesting since the optimization was removed in the 2023.2.3 version used for Emerald Rapids, which was launched some time ago. The note was only added after the optimization was removed, so it feels like this was discovered a while back and is just being noted now. It feels like something was found and discussed, and then everyone moved on. As a result, all we get now are notes in over 2500 results.



{kind=link}
From what I understand the Spec benchmarks are not synthetic tests made simply for comparing hardware but real applications that perform useful work. For xalanbmc the Spec description states that the program is an “XSLT processor for transforming XML documents into HTML, text, or other XML document types” written by IBM and Apache.
It’s not clear what optimization the older C++ compiler did, but while specific to the pattern of code that appears in Xalan-C++ version 1.10 it’s conceivable that similar patterns also appear in other translators.
Thus, another possibility consistent with the timeline is that the optimization was originally removed because it somehow led to exploitable security issues–possibly due to buffer overflows resulting from automatic removal of a specific pattern of range checking. While this is purely conjecture, maybe only after the support team removed the optimisation was it discovered how it had been tuned on Xalan.
Given the historical way Intel compilers and libraries slowed AMD processors down using legacy code paths and instructions unless an Intel processor was detected, I can understand why people are suspicious now. While I personally don’t like compilers that change the code in surprising ways, I can see how such optimisations might naturally be created in the compiler development process.
Comments are closed.