GIGABYTE G383-R80-AAP1 Power Consumption
In terms of power, we get a 4x 3000W CPU in a 3+1 configuration.

The APUs air cooled are rated at 550W each, and we did not have this hooked up to our standard power monitoring gear since it was being done remotely, but you can expect this system to use a fair amount of power. We saw the system running at closer to 3.4kW via onboard power. There was a lot more room to go up from there though, especially with all of those PCIe Gen5 x16 slots and SSD bays. That means when you compare it to a modern 8-way GPU server, you are probably closer to 3-4 of these systems in a similar space/ power envelope. Or 1.5TB to 2TB of HBM3 memory in the space and power of a typical 8-GPU system. My sense is that is why this was used in a higher-efficiency DoE supercomputer architecture.
We should also mention that the APUs can go up to 760W each so that would add roughly 1kW more just from increasing the APU power limits, plus the various cooling and other power delivery features. The benefit would be having additional TDP headroom.
STH Server Spider: GIGABYTE G383-R80-AAP1
In the second half of 2018, we introduced the STH Server Spider as a quick reference to where a server system’s aptitude lies. Our goal is to start giving a quick visual depiction of the types of parameters that a server is targeted at.
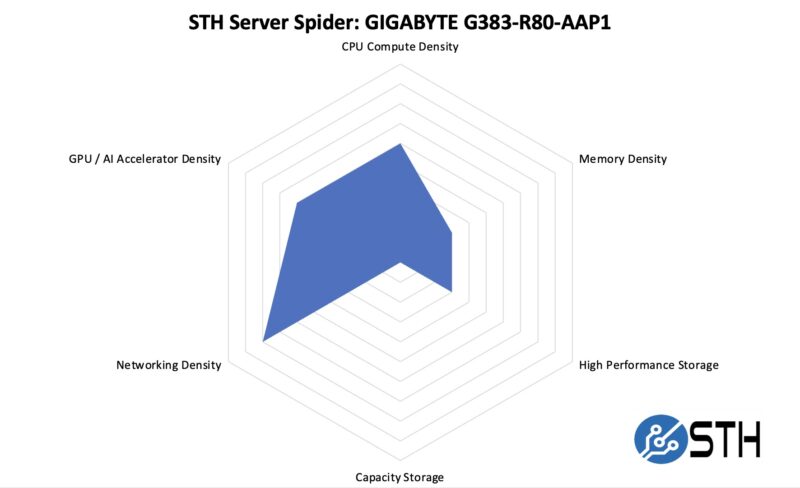
This is not a server designed for the highest density of GPUs, CPUs, memory, or storage. Instead, it is designed to put a dense and unique combination of HBM, GPU compute, and CPU compute into a single platform. It was certainly fun doing the STH Server Spider for this one.
Final Words
This server is incredibly cool. Something hard to articulate is that we have seen this server before, but it took until actually taking it apart and using it to realize what GIGABYTE and AMD are actually doing.

This is clearly not a server for everyone, nor frankly for most of the workloads out there. At the same time, there is a reason the #1 supercomputer in the world is using these chips for high-end compute. The big difference here is that your organization can go and buy this server from GIGABYTE and you can run it or a cluster of these servers without committing to buying a Top500.org leading supercomputer.

At the same time, it highlights many of the opportunities and challenges of building high-end APUs. There is an aspect to this that one gets 512GB of HBM3 memory across the four APUs, CDNA3 GPU IP, and even the same Zen 4 CPU architecture that is found in standard servers. For the HPC folks, this is an awesome architecture. On the other hand, for the AI crowd, they might want to see 1TB or more in a system like this these days and we are limited to the onboard HBM3 memory across four sockets. Still, for high-end APUs, AMD has something awesome, and if you have an application that can use an architecture like this, then this GIGABYTE system is the one you probably want to use. For anyone else, this is just a really cool server.



{kind=link}
From the first page,
“Compared to the big 8x GPU servers, this is a relatively lower power machine which is fun to think about.”
Something else that’s fun to think about is a single one of these chips in HPC-dev workstations. Any indication that we might see something like a DGX Station (GB300 Grace Blackwell) from AMD?
Has the time come once again for serious fp64?
They can do this, but can’t make a high end gaming card. ???
I appreciate this article, but this is fun to think about instead, the SuperMicro GPU A+ Server AS -4126GS-NMR-LCC with 8 Instinct MI350 (8 x 288GB of HBM3E mem) and 2 EPYC 9005 series supporting 24 DIMM 6TB memory in 4U.
Comments are closed.