
Five years ago, when STH was significantly smaller, we ran a short series that was almost therapeutic for me. At the time we were struggling with AWS instances segfaulting due to disk I/O issues and AWS bandwidth costs were just becoming burdensome enough that the switch made sense. Every year or so, the topic comes up, regarding whether it makes sense to self-host versus AWS. The team these days is bigger, we operate out of multiple data centers for parts of the business, but we still need to deliver STH to our readers. Many of our readers are likely going through the same discussion themselves or for their clients. We track this data and have the benefit of learning a lot of lessons along the way.
Before we get too far into this, assume this analysis is for 1/2 cabinet to 3-5 cabinet installations for a single tenant infrastructure rather than larger installations. Having a small number of machines (<200) simplifies some aspects to the point that lightweight automation tools are good enough. At the same time, companies like Snap that have enormous AWS bills for not dissimilar reasons. We often hear at $10,000/mo companies start to look at a hybrid private/ public model but we are doing so at a much lower monthly AWS spend.
The Dirty Myth – Physically Servicing Servers is Commonplace
Before we get too far in this. In the last two years trips to the web hosting data center happened for two reasons:
- There is some cool new technology that we want to try. For example, recently we recently hosted STH on Optane drives to generate some real-world performance data.
- We have a meeting nearby and something failed or needs an upgrade.
We have had nodes and switches fail and one spectacularly bad event years ago that we learned a lot from. At the same time storage is all clustered / mirrored. We have extra switches available, extra nodes available, and frankly we just overbuilt. There was a point last year where we ran an experiment on how low we could power a Xeon D hosting node. The node did not have enough cooling and was not stable. We simply offlined the node and it did not warrant even a visit to the data center for two quarters since that would have been a 20-minute trip each way.
What has made this possible is the decently reliable SSD. When we had nodes with hard drives, we saw a 4-6% AFR. If you have 30-40 drives, there is a good chance one or more is going to fail in a machine in a given year. Our actual AFR on the SSD population is down to under 0.2% even though we are often using used drives. Check out our piece Used enterprise SSDs: Dissecting our production SSD population for some information on the experiment. Moving to SSDs essentially means that we no longer need to regularly count on swapping drives on a service call. Fans rarely fail which we confirmed with one of the hyper-scale data center teams. Power supplies are pretty good these days, although we did see one fail in the lab this year.
Overall, the message is to build spare capacity. Expect things to fail. Bias towards more reliable components. Those concepts will allow you to minimize needing to service gear. It is not difficult to calculate what having online spares costs versus cloud and that is how we model our costs. We also assume a shorter lifespan than many installations. Our oldest web hosting machines are currently on the Intel Xeon E5-2600 V3 generation, and those are being evaluated for an upgrade in the next few months.
We have seen a lot of models that assume using ancient hardware (e.g. Xeon 5600 series and older) or just enough capacity to equal AWS capacity and those models typically result in higher failure rates. We also have seen a number of models rely upon using pricey virtualization software versus KVM and Linux based hypervisors. To compete with the cloud you will need to be OK using fundamental, well-known, and mature infrastructure technologies that cloud providers also rely upon.
AWS EC2 Costs v. Self-Hosting
We simplified our hosting set down to what we like to think of as a “bare minimum” set of VMs. It takes around 23 VMs to service our primary requirements, and that assumes we are not doing A/B testing or trying out additional services in additional VMs. These 23 VMs are essentially the “core” of running a site that services a few million page views per month plus runs a variety of services for our readers and clients.
We took these 23 VMs and constrained them to the mainstream AWS instance that most closely resembles our actual RAM usage. Our primary constraint, like many environments, is RAM. STH does not use a ton of storage, and we can effectively cache pages across the site. Since we are heavy on caching, we generally expect 18-24 month intervals between when we need more memory allocated.
We also are not including any temporary infrastructure such as VMs that are spun up to simply try a new feature or technology. We are using simply the base load.
AWS EC2 Cost Breakdown
On the AWS side, it would be completely irresponsible to model using on-demand instance pricing as is often done. We know from years of experience what a base load looks like and we know the instance sizes that can handle our modest peak to valley traffic. We are using 1 year reserved instance pricing because we do tend to upgrade annually. While this year we are heavy on m5 instances due to their memory to compute mix, next year may be something different. We also do opportunistic upgrades on our hosting servers hence why we already have Intel Optane in the hosting cluster.
Since we know we will have capacity needs at least for a year, we can model using 1-year reserved pricing. We tend to not look at all up-front pricing since that is not what we have in our hosting cluster. Instead, we look at no up-front and partial up-front reserved pricing. We tend to move to newer hardware and newer instances on an annual basis which is why we are not using a 3+ year reserved instance tier.
AWS 1-year No Up-Front Case
If we want to model our costs for a year, we can use the 1-year no up-front instance option. Here is what our breakdown looks like right now:
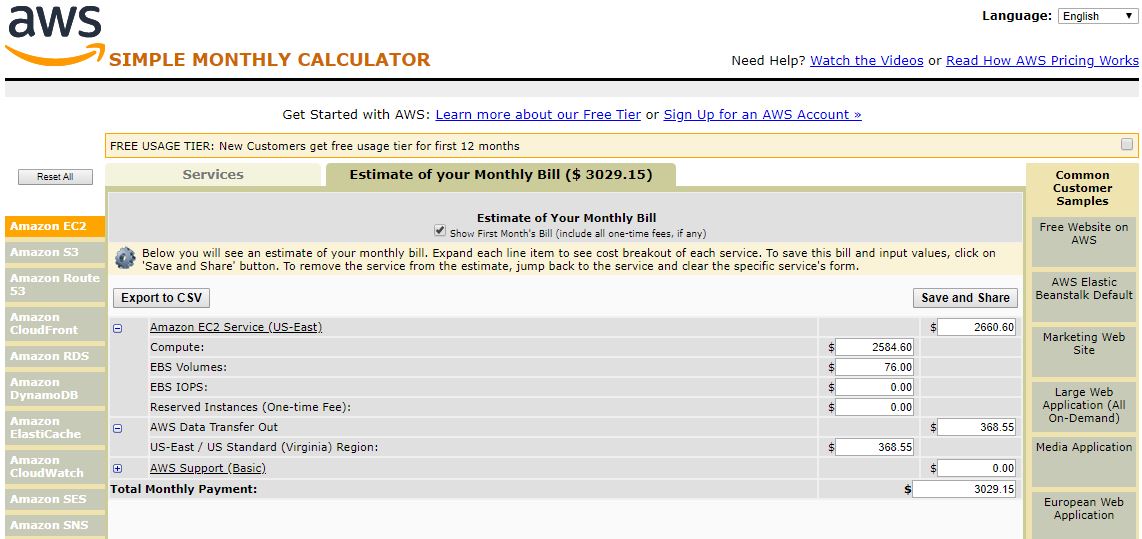
Our total cost for the 23 node fleet, in a single AZ, is $3029 per month or around $36,350 per year.
One item we should address, and more on this in the discussion, is that we modeled using 4TB of outbound traffic per month. That is a reasonable figure for us for Q1 2018 given our video and ad content is hosted externally.
AWS 1-year Partial Up-Front Case
AWS offers an option for those that know they are going to have a base load. One can pay an up-front sum and have a lower monthly bill. Here is what our breakdown looks like under this scenario:
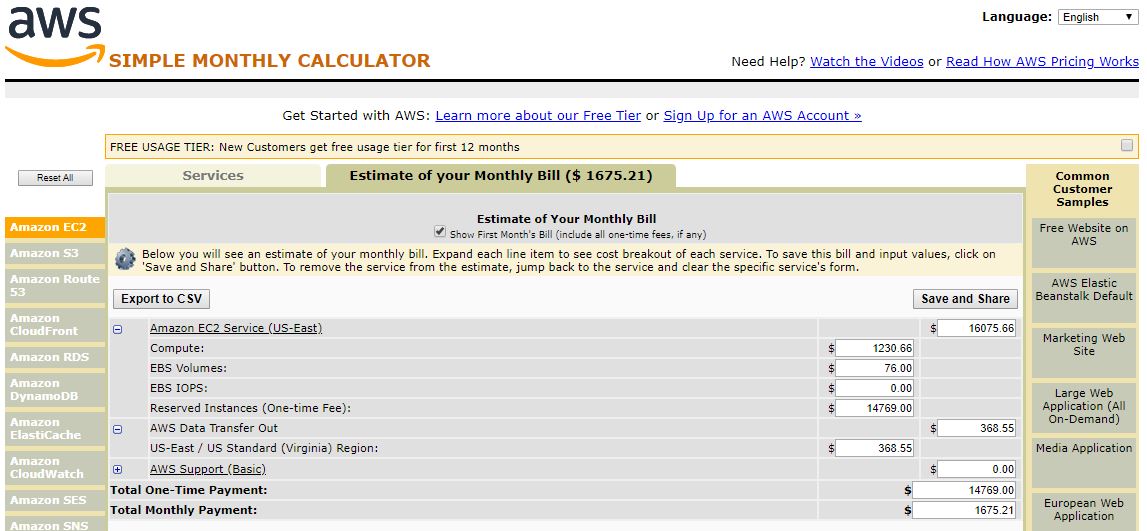
This option brings our monthly bill down to around $1675 per month or about $20,100 in the recurring total. We still pay an initial sum of $14770 at the outset so our total is $34,870 for the twelve month period. That reserved model got us a solid $1480 savings or around 4%.
Self-Hosting Option
Self-hosting is a different animal. While with AWS the costs of running the internal networking, sourcing data centers and components, dealing with hardware failures, and etc. are all factored into the price, if you self-host, these are items that cost real money. We also get (significantly) better VM and storage performance on the self-hosting option, and there is usually a small shadow fleet of VMs that are online at a given time that are “free” in the self-hosting option but would add costs on a cloud provider.
We have three primary hardware cost lines:
- Hyper-Converged Nodes
- Replacement/ Upgrade Hardware
- Networking and Cabling
For networking gear, we assume a 3-year service life. We simply take initial purchase price and divide by 36 months here. As a result, here is what our budget looks like:
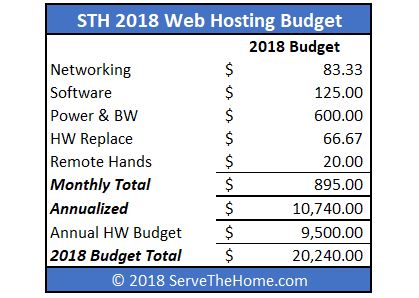
On the flip side, since we moved to all-flash hyper-converged nodes, this is not overly accurate. Actual expenditures in 2017 for web hosting were under $16,000. We also have undertaken a number of proactive upgrades such as making nodes 40GbE capable instead of 10GbE which added cost. We have been cycling in Optane and larger capacity flash. There are also a number of cost-cutting measures in the nodes that can cut another $4-5K per month by running higher utilization. We typically are building 4x the capacity we need to ensure that we can handle ad-hoc application needs and failures.
Comparing AWS and Self-Hosting Costs
Looking at what our 2018 budget is versus AWS 1-year Partial Up Front reserved instances, this is what our budget this year looks like:
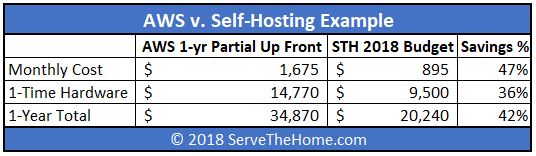
This analysis shows a 42% savings by self-hosting versus AWS costs. That is fairly compelling, but there are a few additional points:
- We excluded the 12-30 VMs we have running on the hosting infrastructure at any given time. The incremental cost is essentially 0 for us, but there would be several hundred dollars per month more AWS costs, especially if we had to use on-demand instances.
- Our last major hardware purchase was in early 2017. Since then DDR4 and NAND prices have risen drastically. Since we have so much overcapacity, we can choose to wait for better component pricing.
- We do not have on-site next business day service on the machines. This is usually a huge cost item, but we deal with one drive failure per year at most. Our colocation contract has provisions for “free” remote hands to swap failed hot-swap drives.
- We are using a $120/ hour rate to drive to the data center (20 minutes each way) and perform any service tasks, including racking new gear.
- Our budget for 2017 was similarly around $20,000 yet our actual costs were well under $16,000.
- As we decommission nodes, their value is not $0. We can often get over 15-20% of our storage and networking purchase price back selling our used gear if we wanted. This is not included in the modeling but is a reasonable caveat.
- Upgrading intra-node switches and cabling from 10GbE to 40GbE added significant cost that could be avoided. One could also move to single switch fabrics which would save additional dollars.
- AWS can have significant cost reductions each year. If this was a 5% variance we would probably go with AWS. As it stands, our “worst case/ way overbuilt” 2018 budget is a 42% savings over AWS.
- AWS projected 2017 costs (using m4 generation instances) were approximately 135% actual self-hosted costs in 2017.
- Moving from a 4x to a 3x or 2x overbuild ratio would have a transformative impact on our self-hosting costs but would increase the need to quickly replace failed hardware.
- Beyond spare compute and memory, we also have excess bandwidth and storage. The excess bandwidth means that STH site growth translates into near zero incremental cost in the self-hosted model but in the AWS model would add significant cost. With STH growing at a triple-digit annual pace, bandwidth savings quickly outpace cloud provider data transfer price cuts.
On balance, we are understating the benefit of self-hosting and still end up 42% ahead. Overall, this is simple to do, but it is something we look at each year to ensure it is worthwhile.
Why does everyone not self-host versus cloud?
There are a few key factors to why there has been a big push to the cloud. STH’s growth profile is aggressive, but it is entirely manageable. While 1000% annual growth this year would be awesome, it is also something we can handle in our current model at near zero incremental cost. If you have a larger operation with a more complex set of applications, the economics can change. Likewise, if you are expecting 1000% per month of growth, scaling in the cloud is clearly advantageous. Many VC’s specifically dictate that their investment companies use cloud infrastructure over self-hosting.
There is a marked push for running hybrid cloud models. Many companies are essentially looking at their “base load” that they can run in their data centers, similar to what we are doing. They can then burst using cloud capacity for seasonal events or specific tasks.
AWS in 2018 is Microsoft of 2000 in that there is a huge vendor lock-in as companies build on the AWS services infrastructure. At STH, we use few AWS-specific tools (and we still use some), but that also makes our workloads budgeted here metal agnostic. We also are not handling healthcare data so having a HIPAA compliant infrastructure, that cloud providers have, is not a top priority.

One will hear a number of industry analysts push cloud as that is undoubtedly a major thrust in the market. Hardware vendors who pay for industry analysts look at hyper-scale customers as a major segment. Cloud is still cool. STH self-hosting is decidedly uncool however it is hardly a trailblazing endeavor. It is an established model and companies like Box that leave AWS to tout massive cost savings.
Perhaps the #1 reason cloud is so popular goes back to just how much VC money has been spent over the past few years. Much of the top-tier IT talent that is capable of managing this type of infrastructure is working on building product and services rather than optimizing on the cost side of the equation.
Final Words
Everyone has different workloads so this should simply be taken as an example and data point. We are starting to see more companies look at the hybrid-cloud model since that provides flexibility benefits while still allowing a company to reap the rewards of better cost models. Our cost savings are particularly small. Saving $15,000-20,000 per year is less than 0.1 FTE in Silicon Valley wages. That drives why we generally see this as a push as AWS bills exceed $10,000 per month rather than at a smaller scale. We also have access to a ton of different technologies so we know exactly where we can make trade-offs. Perhaps instead of simply reasonably prudent IT buyers we are exceedingly prudent IT buyers which makes the model work.



{kind=link}
How much colo space, power, and bandwidth do you get for $600 /mo though? That seems really low for a rack in a datacenter that offers the standard UPS, generator, and cooling redundancies expected.
To follow up on what Jared said , I cannot help but wonder what SLAs / commitments you get with such a low quote.
What type of bandwidth do you have? Are we talking a standard 10Mb uplink with burstable gig, 95% percentile kind of deal here? Multiple redundant-pathed power drops coming off different UPS / generators? 24×7 support line that someone will always answer?
You raised a good point about saving a good chunk of change by not needing to pay for support contracts, however a lot of companies absolutely do benefit from them. When a company can accurately map to the minute revenue lost from downtime, having a vendor get your SAN back online an hour faster than you otherwise would yourself can quickly justify the extra spend for that premium support contract. Hell, just having someone to call when you need logs analyzed to prevent said downtime from happening in the first place cannot be overlooked.
Full disclosure: I work for a data center (well, a company which has multiple physical data centers) that, among our many services, offers colo space. This gives me the unique opportunity to see into the environments of hundreds of different companies who roll their own infrastructure as you are doing. From industry experience I can say that the way STH treats their environment and plans their hardware refreshes / redundant architecture… It is not how most companies do it. STH is among a very tiny percentage of companies who take their architecture to this extent.
I’ve seen and worked with many companies on both ends of the competency spectrum, and I must say that I really would not advise a small to medium sized company go colo as a cost-saving measure if they do not already/also have a competent team and quality hardware with support contracts to go along with it. Having a single cloud architect and going for a cloud platform or managed environment would likely be cheaper and provide better up-time (read: revenue) than rolling your own in the long run.
The best option I can think of–for companies of any size (with some exceptions)–is going hybrid cloud. Run the mission-critical applications on a cloud platform that guarantees up-time without needing six-figure support contracts, and the less-critical or development environments in a small colo space that can be built on years-old hardware that has been cheaply scaled out. The best of both worlds.
Jared and Rain I do this all the time too. To run that many VMs there’s no way they’re using more than 1kw. They said m5 instances so they’re not using much CPU. IP transit costs well under $0.20/Mbps so if they’re going through an upstream provider that can oversubscribe even a little bit they’re going to have more than 10mbps. 4TBpm is 13mbps average and this site gets reddited a few times per month so they can’t survive on 15mpbs if 13 is their average. Need a few hundred Mbps and at least 100mbps 95th to handle that visibility.
I suspect that the real reason they’re doing so well is that these aren’t people that use PSU capacity of each server and switch. Most buyers see a 1kw PSU and assume they need 1kw contracted at the DC even if the max power consumption is 500w and the real operating range for the server is 200-300w. You’ve missed that competency in your article but that’s STH’s business to know and help other companies with that.
I’m more surprised that STH pays for hosting. You must have offers from readers for free hosting.
Good read STH
Kingsman is right. You can be a moron and operate AWS infrastructure. Take all the companies with open S3 buckets with passwords, PII, and API keys out there.
This is really interesting and thanks for writing this. A couple of questions though, apart from the DC stuff posted.
1. If you go with AWS v self hosting, does your labor change at all? I’m wondering a) if you think you need less people on the team, though that’s not realistically an option for most orgs, but more b) do you have other things that they can do, or really, do perform? Meaning they tackle other work that is backlogged, or make other improvements. Or are they more idle?
2. In line with that, I don’t see you accounting for additional labor efforts in self hosting, setting up/install, choosing hardware, making decisions about when to refresh and looking at options, selling used gear, etc. Those are items I can often find become time sinks, and low value items that people do because they’re easy or they overthink the effort to sell, price, pack equipment, or they need a break. Sometimes good tasks, but easy to overwhelm other items.
Great comments thus far and there is a thread in our forums discussing this as well. https://forums.servethehome.com/index.php?threads/falling-from-the-sky-part-4-leaving-the-cloud-5-years-later.18909/
On the DC costs, I can say our budget is higher than actual, and Joseph Kingsman nailed it. We know exactly how much power a system will use due to our hardware reviews. That is also why we started adding a 60% load figure in many of our CPU and system reviews. This is not a huge hosting cluster, but we are paying retail rates. We do consult on how to more accurately spec cluster power.
On the bandwidth, it is dirt cheap these days for this type of setup.
Steve Jones 1) not really. We tend to use contractors for any unscheduled maintenance. Anything else is done when we are visiting vendors nearby and the install process is very fast. We can have a new system loading dock to online and provisioned with the boxes clear in 30 minutes. 2) In terms of doing the refresh, that point is well taken. The 2017 buy took under 15 minutes of time to spec, quote, and order beyond the 30-minute window to get into the rack. Realistically, the target is one single hour visit every other quarter. We sometimes bring industry guests such as vendors we work with just to show the hosting cluster, but those do not involve hands-on maintenance.
On the analysis paralysis front, this expertise can be bought for a low enough dollar figure that it would not have a meaningful impact on this analysis. Sure there are people who need help and do not seek it, but that is the responsibility of the organization spec’ing servers to get this expertise. If they do not do so, then it can be a waste of time.
As mentioned, there are a few ancillary upgrades that happen. For example, when we saw the Optane 900p performance in the lab, we had already purchased a dozen drives and tacked on additional units for the hosting cluster. Unpacking a drive and putting it in a tray takes us about 2 minutes per and the trip to install drives was in/ out of the data center in under 15 minutes. The Add-in cards take about 2 minutes to unpack and then took 4 minutes to install in the one machine we did AIC drives for a test.
Great discussion.
Killer analysis. Do again when you’ve added those extra VMs
Running on Hardware you pick and control you can make use of technology not available in the cloud (think RDMA, NVRAM kernel bypass), this can drastically decrease your cost. Very often I see the opposite being done, for example companies buying VMWare licenses, then ending up running Kubernetes on VMs or trying to build a cloud-like environment with OpenStack.
I’m curious why, given you state you have predictable load you opted for RI’s in your calculations and not an ASG with a mix of On-Demand and Spot Instances – there is a nice Lambda function which replaced in the best instance type compared to your instance vs the spot cost as an example. RI’s aren’t really suited to that sort of workload IMHO as you are basically burning money when you aren’t using the compute. Sure it’d complicate the calculations, but if your going to compare then really should be compared in the way you’d be (or should be) using it – just like you do for the self hosted.
You also don’t mention if you switched to RDS or self hosted your DB – not the use of things like CloudFront to case and ease the amount of backend compute you may need.
I’m not all for cloud to be clear, I sink money into rackspace in New Zealand for various reasons, I just wonder if the numbers would come out better if you did compare it in a more detailed manner – which isn’t easy and partly why people get put off or get sticker shock.
Alex, great points. We looked at that and you are right, we have the ability to scale in the colo infrastructure at near 0 cost. On AWS on heavier traffic days we would need to add additional capacity since we are using more CPU on those days, this is more of our base load (e.g. the minimum necessary to keep the lights on) for AWS than our maximum load.
We are not using RDS as there are some application age gremlins that we have. For bits like the forums, there is also an enormous performance gap between what RDS offers and what Optane backed storage offers. On storage, we used general purpose SSD EBS but that is nowhere near the storage performance we get with our current setup.
Your point is valid that this is an imperfect comparison since we are leaving performance out of the cost side.
Extremely interesting and a bit of history lesson.
Comments are closed.