
Today we have exclusive third party benchmarks of a dual socket Cavium ThunderX platform which has two 48 core ARMv8 64-bit processors for a total of 96 ARM cores. We are only releasing a teaser benchmark result set at this time as we had this benchmark submitted by a developer who requested to remain anonymous. We did give Cavium a week of advance notice that we are going to publish these numbers and offered to do a more formal testing round. Cavium apparently does not respond to such requests however our invitation remains open. We first saw Cavium ThunderX promised in 2014 and teased again in 2015. Customers are running ThunderX, but from what we understand, there is more demand for the silicon than the company is able to produce from foundries. To say we are eagerly awaiting silicon in our data center labs is a conservative statement as we are excited to see anything come out of the ARM vendors.
Select 96 Core Cavium ThunderX Benchmarks
Selecting a comparison group for this benchmark set was difficult as the ThunderX chips support massive amounts of memory, up to 512GB per CPU or 1TB in a dual socket system like this. Indeed, the test system had more RAM installed than a quad Intel Xeon E7-8870 V3 system we recently reviewed. The Intel Xeon E5-2600 V2 and V3 lines can support up to 768GB of RAM per CPU, or about 50% more per chip than the Cavium parts. The older E5-2600 V1 chips were limited to 384GB per CPU. Currently the Xeon D-1500 series is limited to 128GB and single socket configurations, however that is the chip Intel launched to keep most ARM vendors at bay. An ARM core is currently nowhere near a Haswell or Broadwell core in terms of performance (we will show single threaded performance shortly) so in some cases we moved down the stack to show what this might look like. We also included results for an AWS c4.4xlarge instance in our data set for a cloud performance baseline. At the end of the day, we have a huge result set and tried to add-in a few comparison results that we thought would be useful in each benchmark.
As an editor’s note, I do believe these benchmarks can be more highly optimized. At STH, we do not optimize benchmarks using 4 lines of compiler flags and instead try to mirror real world usage. For example, the number of individuals who use apt-get install openssh-server versus the number who compile from source is likely a wildly lopsided ratio in favor of using a package manager. On the other hand, at this point Cavium is targeting those who not only compile their own openssh-server but also have a custom version that they run internally. There is quite likely a lot of performance left on the table here, but assume this is what your average admin would see in terms of performance at this point in time. We are happy to work with Cavium and other arm64 providers to improve performance and publish updated results.
With those disclaimers, it is time for benchmarks.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. It scales well based on IPC performance changes and scales well from 1 thread to systems that have close to 200 threads (we have not tested it on any larger systems yet.)
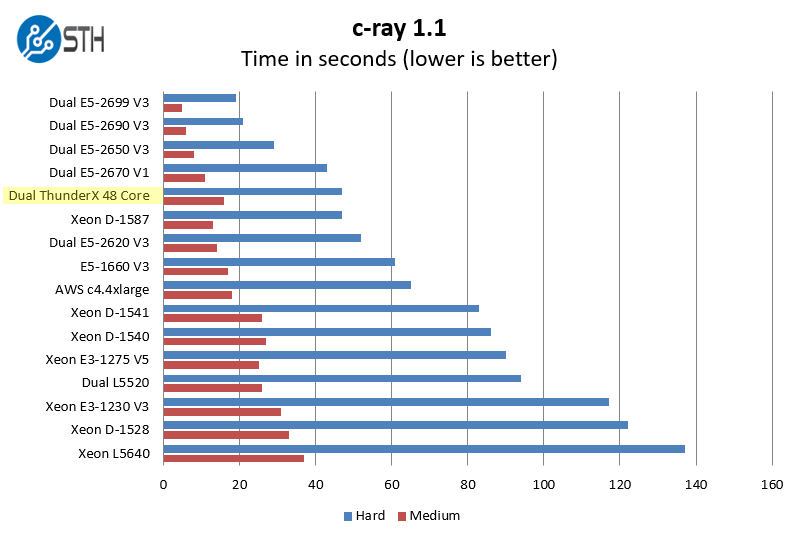
In a highly parallel workflow, the Cavium ThunderX dual 48 core chips perform well. We can see the that they are besting the 85w TDP E5-2620 V3 parts. We do not know how the Cavium ThunderX 48 core chips are priced, but if they are around the $400 each street price of the E5-2620 V3 that is a fairly compelling benchmark.
Single Threaded Performance with UnixBench Dhrystone 2 and Whetstone Benchmarks
Of course, these chips are not meant for heavy compute but we pick out the UnixBench 5.1.3 Dhrystone 2 and Whetstone results to show some of the raw performance they are capable of. UnixBench is widely used so it is a good comparison point. We are only publishing single threaded results for these:
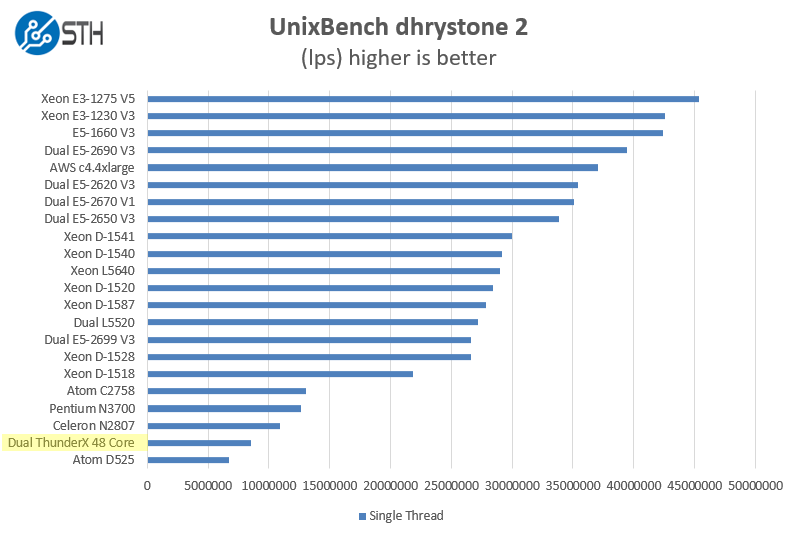
As one will noticed, we added a few more comparison points into this section. In terms of integer performance, this is not really a surprising result.
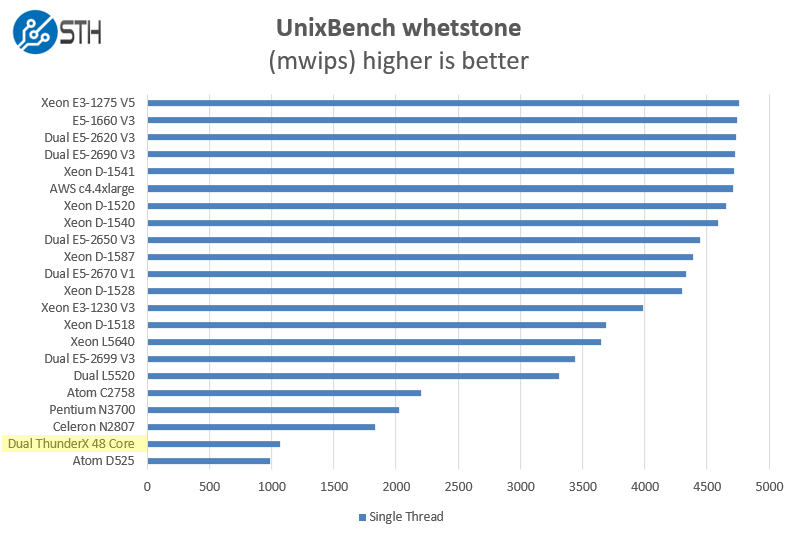
On the floating point side, we see a similar enough story. Frankly, this is what we would expect. ARM may have a core count advantage, but an Intel out of order core is still too much for the ARM chips we have seen to date handle.
7-zip Performance
7-zip is a widely used compression/ decompression program that works cross platform. Compression/ decompression algorithms are widely used in areas such as storage so this is a bit more of a real-world benchmark application.
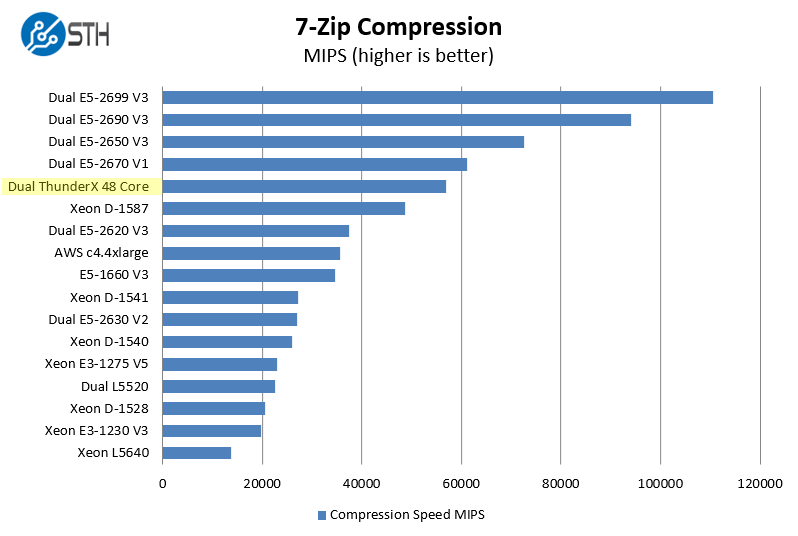
This is one benchmark where we see a strong showing by the Cavium ThunderX 96 core machine actually besting an AWC c4.4xlarge instance performance.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. Many vendors have optimizations specifically for use with cryptography but we are only looking at the non-accelerated performance here. If vendors typically tailor benchmarks to show off how good their performance is in an OpenSSL workload, that is not what we are running. We first look at our sign tests:
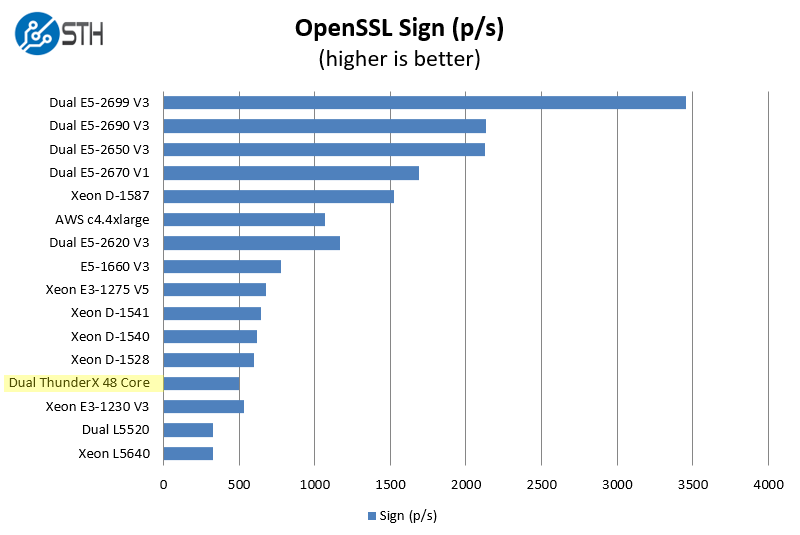
And on the verify side:
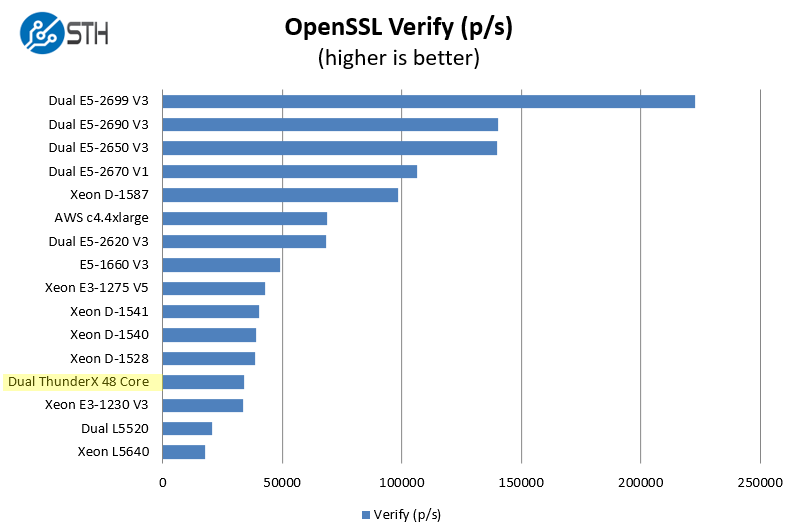
Of course, with proper optimizations, OpenSSL using hardware crypto accelerators can be sped up many times. This is really a pure CPU grunt test as Cavium has specific hardware accelerators that you would normally want to use with OpenSSL. Others like Intel and AMD likewise can get massive speedups using hardware accelerators. Frankly, the x86 world is going to be more optimized, so we would expect the ThunderX to get better with time, especially as some of the larger shops get ahold of the chips and give back to open source projects.
Final Thoughts
One area that cannot be underestimated at this point is that the early adopters of this technology are likely those who need massive amounts of RAM and high speed networking as Cavium is lending its networking expertise to this project. The ThunderX parts can have 10Gb/ 40Gb/ 100Gb networking integrated which is far beyond what Intel is offering. For companies that are utilizing the workload specific processors (e.g. companies that are selling optimized software in a hardware appliance) this is can be an awesome capability.
With that said, anyone who has tried to port server scripts and applications from Ubuntu amd64 to Ubuntu arm64 has probably run into a few roadblocks. The ARM server ecosystem is just nowhere near the maturity of the x86 ecosystem. Cavium is targeting larger cloud players which makes sense. If you are coding all of your infrastructure custom to begin with, and have a massive deployment scale, then developing for ARM is not the largest burden to bare. For the folks installing a handful of racks of gear, or buying dedicated servers, arm64 being a seamless alternative is still a little bit away.
From a compute performance perspective it is an interesting picture. Most of the technically savvy press that I previewed these results with were not surprised at all. Cavium’s marketing stance here is rather good since 96 cores in a system or 384 in a 2U chassis seems amazing. On the other hand, one can pick up a 4 core arm64 development board and very quickly see that an ARM core is not equal to an Intel Haswell/ Broadwell core. For applications like redis clusters where having a lot of memory and low latency networking is a big benefit, these chips could be extremely beneficial. There are also a myriad of appliances that do not rely heavily on CPU horsepower such as storage appliances. We do hope to have better performance numbers but since there is a dearth of third party data out there, we decided to get the ball rolling. Hopefully this is one of the articles out there that gets that ball rolling and Cavium/ AMD and other ARM vendors actually start sampling their chips on a regular basis to the 5-10 sites like STH that regularly cover enterprise IT.



{kind=link}
It is pretty useless without knowing the price. Also openssl might require some recompiling and optimizations, It is weird to be so low performance.
Cavium has started working with us for official benchmarks with a ThunderX platform. We have a single CPU system in the lab and have started benchmarking. Since we are still using Ubuntu 14.04 LTS we will have to compile patch a bit.
Hi Patrick,
A basic query, why we are comparing 48 cores of ThunderX with 12 cores (or any other) of E5-2690 here? what is the reference point or the common point among all of these processors?