Power Tests
For our power testing, we used AIDA64 to stress the NVIDIA Quadro RTX 8000 NVLINK configuration, then HWiNFO to monitor power use and temperatures.
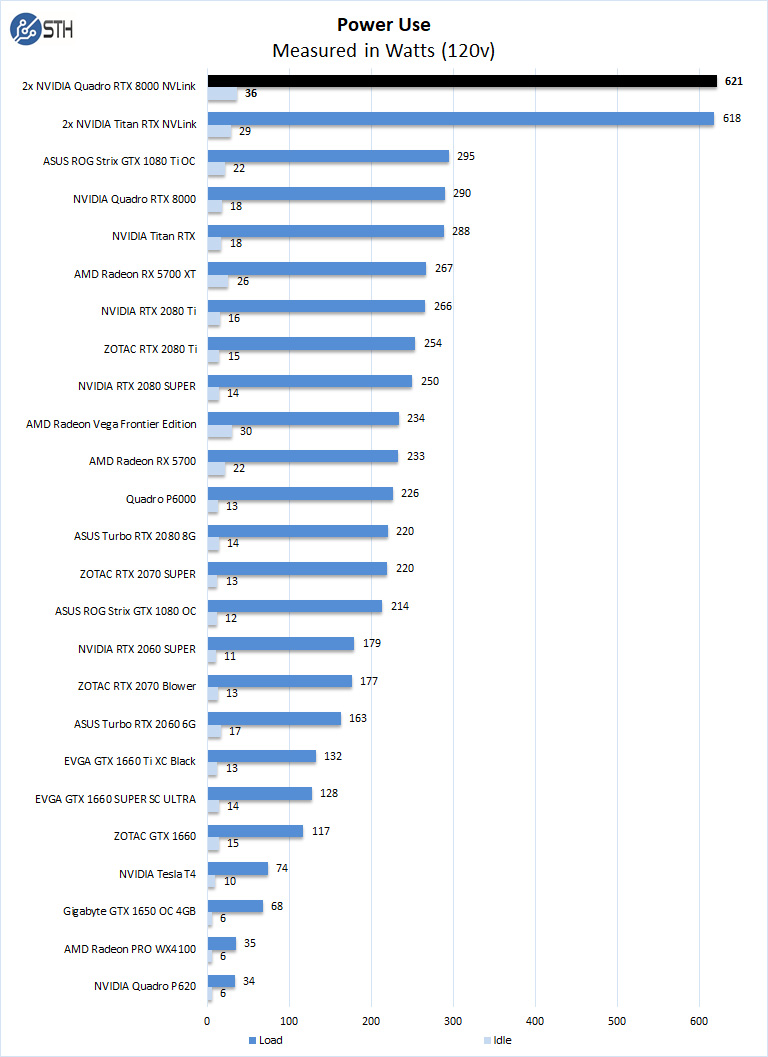
After the stress test has ramped up the NVIDIA Quadro RTX 8000 NVLINK configuration, we see it tops out at 621Watts under full load and 36Watts at idle.
Cooling Performance
A key reason that we started this series was to answer the cooling question. Blower-style coolers have different capabilities than some of the large dual and triple fan gaming cards. In the case of the NVIDIA Quadro RTX 8000, which is passively cooled, temperatures will vary depending on server cooling configurations.
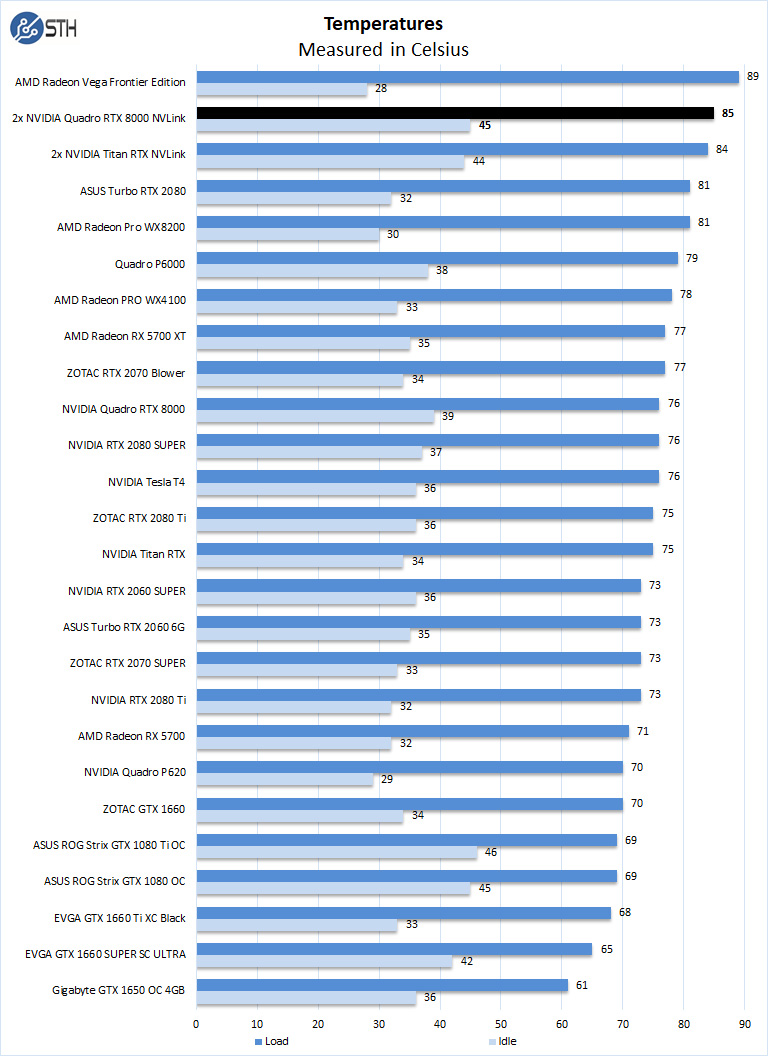
Temperatures for the NVIDIA Quadro RTX 8000 with NVLINK ran at 85C under full loads, in this case, the highest temperatures we saw achieved while running OctaneRender benchmarks. Idle temperatures were reasonable at 45C at idle, which is 1C warmer than the Titan RTX and its dual-fans.
Final Words
Back in November 2019, when we reviewed a single Quadro RTX 8000, it impressed us a great deal with its Deep Learning and content creation capabilities. The Titan RTX is impressive in itself, but the Quadro lines expand on RAM capacity and certifications that the Titan RTX is not designed to handle.

If we break down what this means, it goes like this. With OctaneRender we can set the RAM limits to double that of what we used on the Titan RTX. The dataset used for our benchmarks is 12GB is size, we could easily go 3-4 times that size with a single Quadro RTX 8000, using NVLINK and two Quadro RTX 8000 we can double that. Other applications we test can do similar tests resulting in massive datasets processed quickly, which results in time saved.
With Deep Learning AI use, no GPU chews through Inferencing and Training at rates the Quadro RTX 8000 can do, except for the Titan RTX. With these two GPUs compared, Quadro RTX 8000 as it can go far deeper in batch sizes than anything else we have tested due to its massive memory capacity.
Pricing for the Quadro RTX 8000 is $5,500, which is double and then some for a Titan RTX. Here we are using two Quadro RTX 8000’s which is a significant cost, no doubt. Add in the cost of the workstation/server to run them in can get pricey rather quickly. However, for those that use these types of GPU setups, the ROI can be made up quickly with improved workflows and productivity.



{kind=link}
Why is the Radeon VII not in the comparison, William? It would be competitive in some tests.
Emerth – we do not have one to test and they are discontinued. As a result, it is a low priority. We may look at the Radeon Pro version, but that just started shipping.
Can it run fortnite at 60 fps though?
I would really love to see some testing with this card for VGPUs in VMWare :P
@Jeremy likely it can simulate running Fortnite at 60FPS.
About AIDA64 GPGPU Part1 graph of Page 3, My Titan Black’ Double-Precision FLOPS value is 1842 when “Double precision” is enabled on NVIDIA control panel ? Manager 3D settings. Default is disabled! when disabled, the score plummets to 256.7 GFLOPS and it matches the graph value.
It is better to show the better score, their double precision circuit is fully utilized IMO
OctaneRender 4 does not take advantage from quadro or Titan cards, rtx 2080ti result should be comparable to rtx 8000, SLI should just halve the time.
https://render.otoy.com/octanebench/results.php?v=4.00&sort_by=avg&filter=&singleGPU=1
I guess something went wrong.
yamamoto wrote: About AIDA64 GPGPU Part1 graph of Page 3, My Titan Black’ Double-Precision FLOPS value is 1842 when “Double precision” is enabled on NVIDIA control panel.
This is a very important point.
When reading through the review I was about to ignore this card as yet another AI GPU unsuited for doing science. Now your comment has me wondering which other cards treated here suffered a similar methodological problem with double precision arithmetic.
@Eric
Maybe other Kepler GPUs such as GTX Titan or Quadro K6000 are affected
I have a Titan V, there is no “Double Precision” menu item on NVIDIA Control Panel on this GPU and its AIDA64 Double-Precision score is 6283 GFLOPS. It is cost effective solution for some scientific calculation IMO.
Can this gpu beat the titan v in case of gaming and editing .
Comments are closed.