
Here is one of the chippier announcements we have seen in some time. Broadcom has a new switch chip called the Broadcom Jerico3-AI. That “-AI” may make one thing that it is doing compute functions in the chip, like NVIDIA Infiniband, but that is not the case. Broadcom further says that with its new Jericho3-AI line, NVIDIA Infiniband is bad for AI clusters.
Broadcom Jericho3-AI Ethernet Switch Launched
For those who are unfamiliar, Broadcom has three main high-end switch families. The Tomahawk line is the company’s high-bandwidth switch platform. Trident is the platform we often see with more features. Then at the lower bandwidth but with deeper buffers and more programmability is the Jericho line. The Broadcom Jericho3-AI BCM88890 is the newest member of that third line at 28.8T. This chip has 144x SerDes lanes, operating at 106Gbps PAM4. It supports up to 18x 800GbE, 36x 400GbE, or 72x 200GbE network-facing ports.

Broadcom’s presentation on the new switch chip sets up the simple message. Large companies and even NVIDIA think that AI workloads can be constrained by network latency and bandwidth.
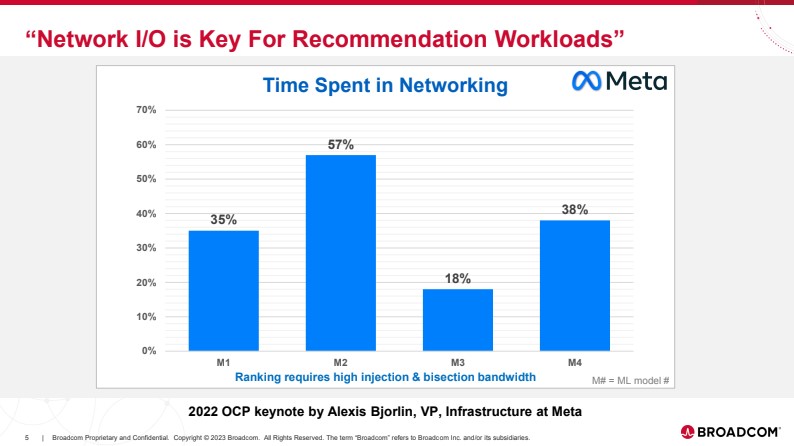
The Jericho3-AI fabric is designed to lower the time spent in networking during AI training.

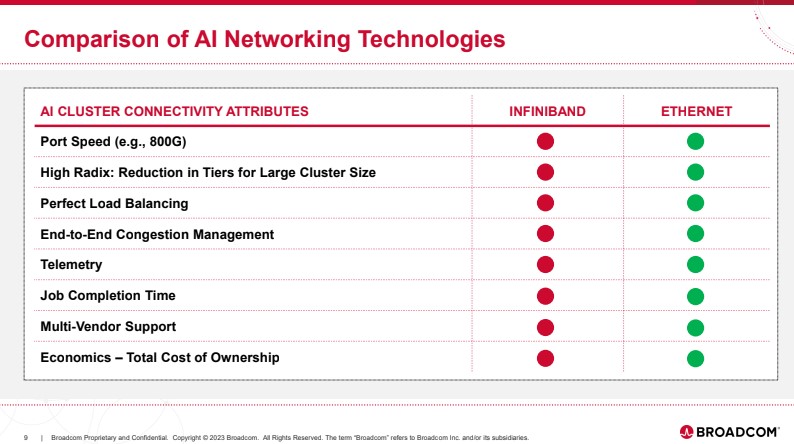
Key features of the Jericho3-AI fabric are load balancing to keep links uncongested, fabric scheduling, zero impact failover, and having a high Ethernet Radix. What is notable, is that while we see NVIDIA NDR Infiniband 400Gbps Switches with features like SHARP in-network compute, we asked Broadcom if they had a similar feature and they did not respond that hey do.

Still, Broadcom says its Jericho3-AI Ethernet is better than NVIDIA’s Infiniband by roughly 10% on NCCL performance. Note, the chart that Broadcom shows is not using a 0 scale.
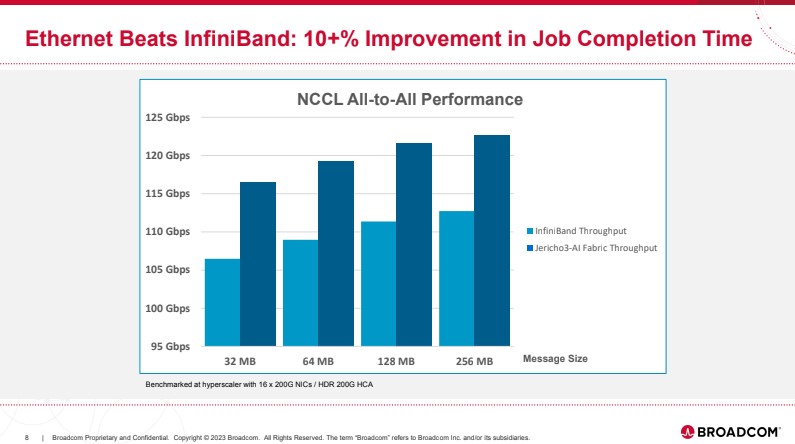
Further, Broadcom says that because it can handle 800Gbps port speed (for PCIe Gen6 servers) and more, it is a better choice. For putting “AI” in the name, it is interesting that Broadcom does not have network AI compute functions listing since that is a major NVIDIA selling point with its Infiniband architecture.
Broadcom is also showing its co-packaged optics, along with DACs, which we assume do not work together. It, however, says that its solution is more energy efficient.

It was a strange announcement since it was very light on speeds and feeds. The Jericho line is not Broadcom’s high-bandwidth line trailing Tomahawk and Trident, so that is likely why.
Final Words
We should learn more about Jericho3-AI at the OCP Regional Summit 2023 this week. We also expect it will take some time until we see products with the new chips. Usually switch chips get announced, then development of switches happens, then production silicon hits OEMs, followed by actual switch availability. In the meantime, we have a Tomahawk 4 platform in the lab that we will be showing with NVIDIA ConnectX-7 NICs when the video is finished being edited.



{kind=link}
“Braodcom”
An Ethernet manufacturer who belittles InfiniBand? What a surprise :-)
I guess Chelsio “converged Ethernet” buzzword is no longer potent.
I’ll still use pluggable optics for the modularity and flexibility down the the road. As I’m not in the hyperscaler space, I’ll get better power savings from decommissioning some cabinets full of old spinning rust.
My (layman’s) understanding is that one of the features you probably care about if doing networking for GPU clusters is the GPUDirect RDMA that allows GPUs across nodes to cooperate with some degree of efficiency.
Is that something that is supported on basically any networking option that will do RDMA, just with ConnectX parts being the ones that get featured in all the tutorial-level writeups and shipped by default with DGX/HGX boards? Is it a “If you aren’t going to use our NICs have fun re-implementing those features on yours; we won’t stop you but that’s not an ‘us’ problem.” or are there any things that are outright locked out at driver or firmware level if you aren’t using the Nvidia-specified combination of GPUs and network adapters?
Comments are closed.