
At STH, we have opined on numerous occasions that to unlock true AMD EPYC “Naples” series potential you ideally want 8 DIMMs per CPU. That fills each memory channel with a DIMM. We understand that some configurations are more cost sensitive, but we still recommend at least one DIMM per die or four DIMMs per CPU as a minimum configuration. We are going to show why we make this recommendation.
Why this is Poignant for AMD EPYC Buyers
Configurators of popular server vendors allow for one or two DIMMs on AMD EPYC. This works, but it is far from ideal. Here is an example from the HPE ProLiant DL385 Gen10 QuickSpecs with pre-configured orderable models:
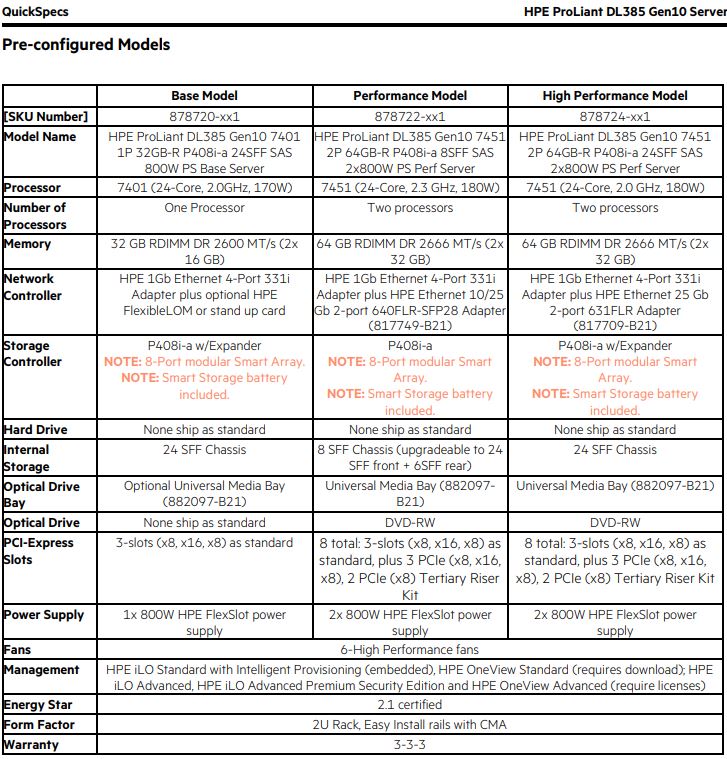
We were working with a system which is essentially the HPE SKU 878718-xx1 labeled a “Base Model” for HPE. This system comes with 2x 32GB DIMMs by default.
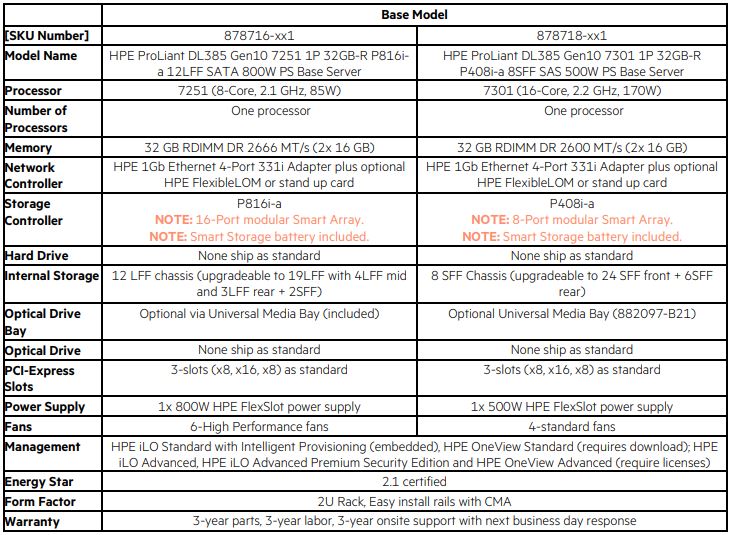
Likewise, offerings like the Dell EMC PowerEdge R7415 configurator start with a single 8GB DIMM configured. Technically, one only needs a single DIMM for these CPUs to work.
Given our guidance that one should use at least 4 sticks of DDR4-2666, one for each die, in an AMD EPYC “Naples” server, the base configurations do not conform to this.
Testing AMD EPYC “Naples” with 1 to 8 DIMMs
We decided to use an HPE ProLiant DL385 Gen10 for our testing with a single CPU. In this case, we are using the AMD EPYC 7301 16-core CPU. While we could have done every increment from 1 to 8 DIMMs, we instead focused on the four configurations we see as being the most likely: 1, 2, 4, and 8 DIMMs.
As a note: we were doing this testing for a client but the benchmark setup is not the same baseline we use for our main benchmark and review pieces. It still shows the delta, the numbers should not be a direct comparison to what we have elsewhere.
STREAM Triad
When we look at raw memory bandwidth, STREAM by John D. McCalpin is what the industry uses (learn more here.) This is the micro-benchmark we expect to have the largest performance deltas by filling memory channels. We also had AMD’s secure memory encryption enabled for this test and were using GCC, however, we did not perform any NUMA node locking as you would do with EPYC seeking a maximum throughput run.
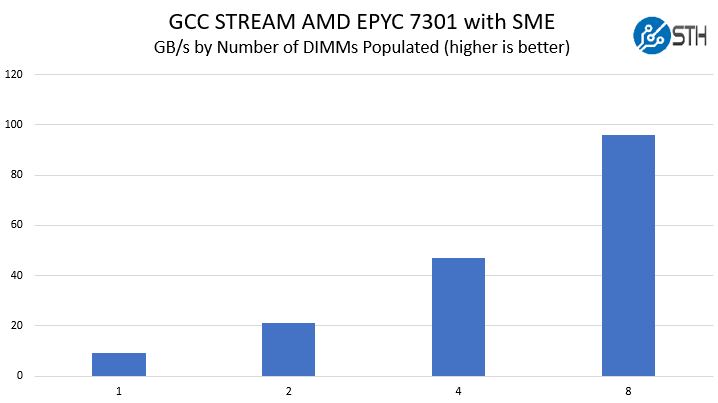
This is an extraordinarily interesting result. We re-ran the test and even Dockerized everything to verify what we were seeing. Each time, we got slightly better scaling than just 2x from doubling the types of DIMMs. We were told that this is due to not pinning NUMA nodes which would align with what one would see on a four-socket Intel Xeon machine.
Linux Kernel Compile
We took a version of our Linux Kernel Compile benchmark and let it rip. This is a CPU benchmark, but it is representative of a common workload that many servers do every day. We
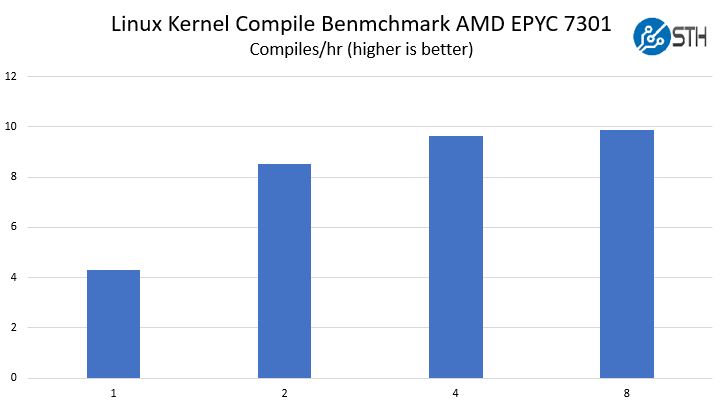
What we saw was some extreme scaling from 1 DIMM to 2 DIMMs almost doubling performance. Then a significant but more muted 13% improvement from 2 DIMMs to 4 DIMMs. 4 DIMMs to 8 DIMMs was still noticeable and repeatable with a 2.5% gain.
Taking a moment here, these improvements are as much as moving to another SKU in the abridged AMD EPYC first generation SKU stack.
Compression Tests
Here we are using our 7zip Compression benchmark. One can see that the number of DIMMs populated again had a significant impact.
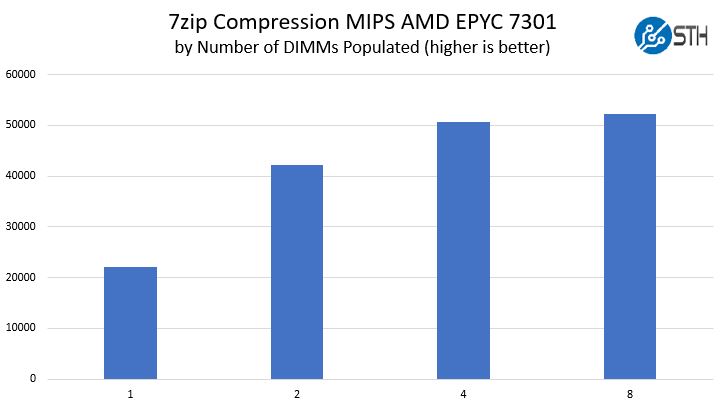
Here we got slightly more muted scaling from 1 DIMM to 2 DIMMs, only about 92% better. 2-4 DIMMs gave us a 20% performance improvement. We received a 3.5% improvement moving up to 8 DIMMs.
Opposing Case C-ray
Going into this exercise, we expected our c-ray rendering benchmark results to be very close. This primarily runs in CPU cache so this is a case where there is de minimus RAM access. We are using our 4K render to add additional complexity and time hoping to tease out differences.
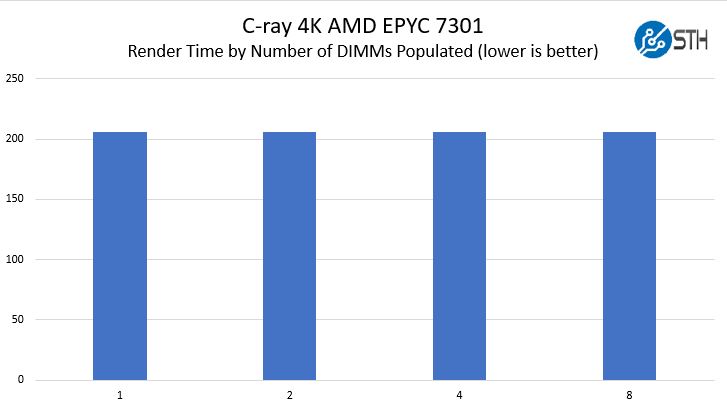
We use seconds here and each configuration was 206 seconds. Going down to the millisecond level would give us a 0.48s difference between 1 and 8 DIMMs. This is an extremely consistent application but we are getting into the range where 1 to 8 DIMMs is an approximately 0.2% delta which is negligible.
Summary View
Here is the summary view of our quick testing where we took the deltas of populating more DIMMs in the system.
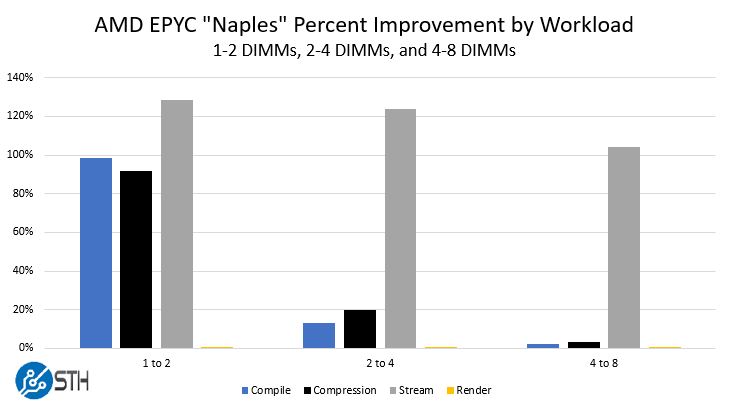
This gives us some ballpark guideposts to have the discussion around how many DIMMs you want. The relative 4 to 8 DIMM indifference toward moving to dual memory channels shows that there is a bigger impact to populate up to 4 DIMMs and having a single channel of memory per die than having dual channel memory per die. The takeaway here for larger applications is that memory access to a different NUMA node is expensive.
Another takeaway is the cumulative impact. For example, on our compile and compression benchmarks, moving from 1 DIMM to four DIMMs was a 125-130% performance improvement. If you were using 16GB DIMMs, this means that for under $600 you can get more than twice the performance out of your AMD EPYC CPU by adding three more DIMMs to unpopulated sockets.
Final Words
This picture is going to change quite a bit with AMD EPYC Rome generation. At the same time, the current generation is an amazing value. We still strongly recommend using at least 4 DIMMs per CPU as performance otherwise will suffer greatly. Compared to some of the other workloads we run, these all fit in a relatively small RAM footprint. Running a virtualization server, for example, would show these deltas to a more extreme degree over time.
For those wondering about the AMD EPYC 7301 it is a lower clocked 16 core CPU, but it still has a full 64MB L3 cache. In initial testing, we are seeing the EPYC 7281 with only 32MB L3 cache and the higher core count 24 and 32 core count parts being more sensitive to memory population. That makes some sense as those are combinations that have less cache per core.
Our bottom line: with AMD EPYC “Naples”, get at least 4 DIMMs per socket.



{kind=link}
It would be much appreciated if the same tests would be run on some Xeon Scallable platform. Many keep configuring those with 4 DIMM instead of 6 per CPU. The impact is probably not as large as on the Epyc platform, but a confirmation would remove guessing.
Try doing a test where there are 4 DIMMs that fully populate the memory controllers for 2 of the dies while leaving the other two dies completely disconnected from RAM except via an indirect hop through another chip.
Great data.
Can you do 32 core too? I don’t care about the epyc 7251 and 7281. Testing lower cache to core ratios is useful to me.
Don C why would anyone configure it that way?
Brianmc: probably because of a hope that Threadripper 2 will be wired this way.
@brianmc “Don C why would anyone configure it that way?”
Well given the rumors about Threadripper 2, which is basically a repackaged overclocked Epyc that is rumored to have exactly that memory configuration (2 dies fully connected to RAM and 2 dies that only access RAM by hopping through the connected dies), it’s a very interesting test point to give a preview of a commercial product that AMD is about to put on the market.
+1 for Don C.
I would have also liked to see if there is any difference between using one channel per each die and two channels on two dies. Especially in applications that don’t use many threads or are straight out single threaded. Those may be able to benefit from this as a single core could directly access two memory channels instead of just one.
Have a look at Der8auer on youtube:
EPYC 7601 Overclocked – Over 6000 Cinebench R15 and extensive RAM Tests.
EPYC overclocked to 4+ GHz and a CB R15 MT score of around 6100 point, not overclocked scores 4068 point. Pretty impressive. Memory test is included.
@Patrick — I don’t know if its an ad swap or something else, but I’ve twice typed in the longish forthcoming comment becuase my browser window refreshed and wiped this textbox before I could post it. Once on Linux/chrome, the other on Android/Chrome. Truly annoying, and probably not your fault, but I’m sure we’d all appreciate it if there’s anything you can do about it.
@Robert, @Don, @Patrick:
Take a look at D8rBauer’s recent videos on YouTube. He attempts to predict performance of the upcoming 32-core ThreadRipper SKU by examining an overclocked 32-core Epyc SKU from which 4 of the memory channels have been depopulated. He tests each possible memory configuration — fully-populating the channe;s of diagonally-opposed dies, fully-populating edge-adjacent dies, and populating 1 channel of each die (both the “inside” or “near” channel, and “outside”)
Interestingly, he found that fully-populating diagonally-opposed dies (as ThreadRipper is configured) gave optimal combined throughput / latency. It performed better in his tests than the populating a single channel per die, or fully-populating edge-adjacent dies. Also interestingly, while he found that the full 8 channels of Epyc showed well in synthetic benches, being limited to 4 channels did not have a significant affect on Cinebench with 32 cores churning — certainly other real-world workloads are memory-bound and will show differently, but I wonder if any of those show up in the prosumer market that ThreadRipper targets.
My guess as to why fully-populating diagonally-opposed dies works best is that it comes down to the physical length of the infinity-fabric connections the unpopulated dies would need to traverse to reach the 4 memory channels. In the diagonally-opposed configuration, the unpopulated dies only have to travers the shorter connections to reach either edge-adjacent neighbor where all memory is located, instead of having to go through the longer, diagonal connection half the time, as would be the case if two edge-adjacent dies were fully-populated. On why the diagonolly opposed configuration seems to work better than giving each die 1 channel, I would guess there must be some efficiency penalty for the memory controllers not being able to interleave channel accesses.
I’ve wondered aloud whether they might map the memory channels differently ever since they announced the 32-core ThreadRipper, going with the 1-channel-per-die configuration instead, so these results have been interesting to read over, but they seem to suggest that things will stay as they are.
@Patrick:
It seems that you find the single-channel-per-die configuration to be better? Does that still stand in view of D8rBauer’s findings? Do you have any idea why each of your findings may differ? Maybe PCIe traffic?
Does ECC still work when some channels are not populated?
“This picture is going to change quite a bit with AMD EPYC Rome generation.” Care to enlighted us? :)
@Alex
he is probably referring to the fact that the next gen will probably have 48 cores or even 64 cores which will lead to bigger memory demands to keep all those cores fed
@Bruno
There are rumors AMD might adopt a silicon interposer for Rome. This could potentially eliminate the NUMA issues Naples suffers from. Perhaps Patrick has some advanced knowledge of this?
Where would I ever get “advanced knowledge” from Alex?
@Guillaume Coutu
Dell EMC has made a study of memory performance with different numbers of memory sockets filled on Skylake platform:
http://en.community.dell.com/techcenter/high-performance-computing/b/general_hpc/archive/2018/01/31/skylake-memory-study
Patrick, perhaps the same source that informed you Rome had 64 cores. The question remains what will “change quite a bit with AMD EPYC Rome generation” with respect to its memory population performance?
i would like to see the same test with epyc rome, which almost 1 year ago released.
Comments are closed.