AMD EPYC 7272 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. Starting with our 2nd Generation Intel Xeon Scalable benchmarks, we are adding a number of our workload testing features to the mix as the next evolution of our platform.
At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
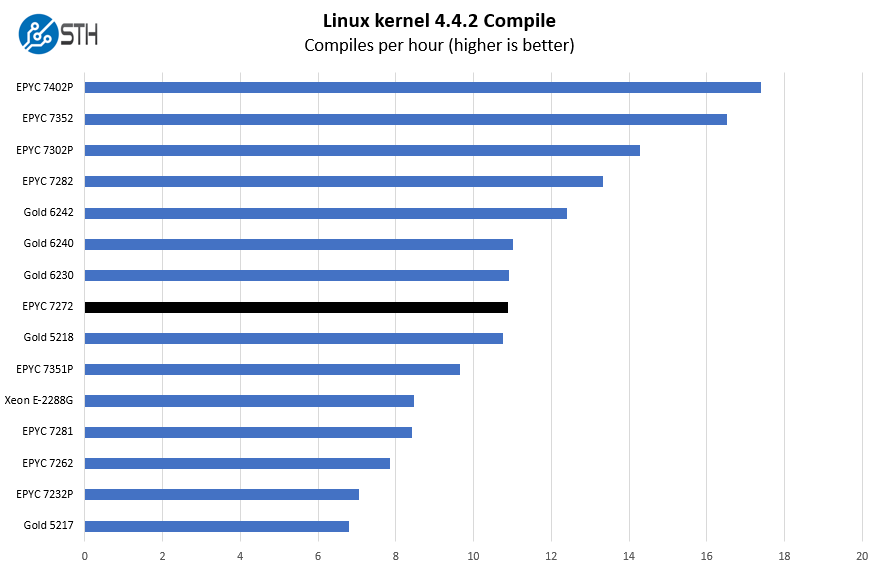
While the AMD EPYC 7272 has the same core count as the Intel Xeon Silver 4214, its performance is closer to the breakpoint between the Intel Xeon Gold 5218 and Intel Xeon Gold 6230.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
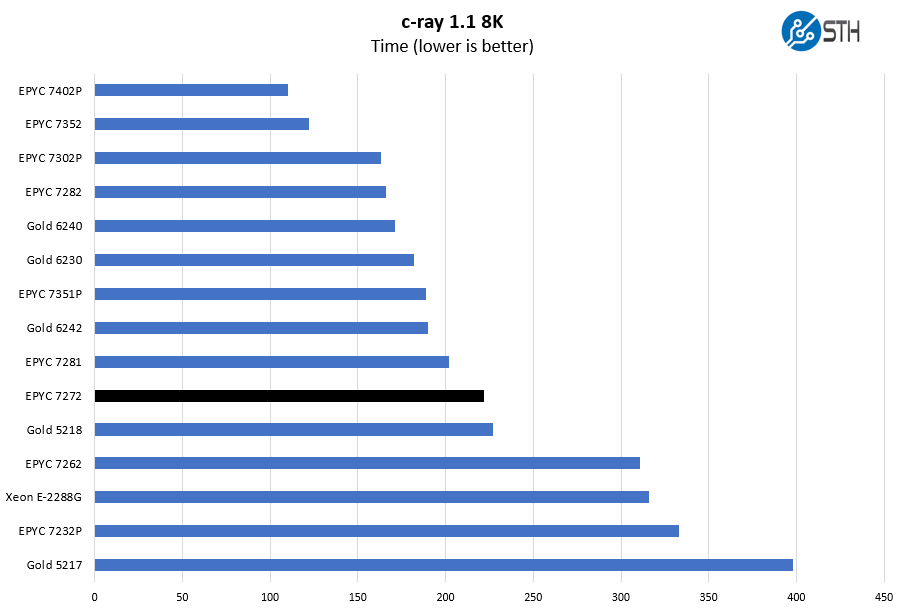
Here, the performance borders on the older 16-core AMD EPYC 7281 which is a great generational improvement.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
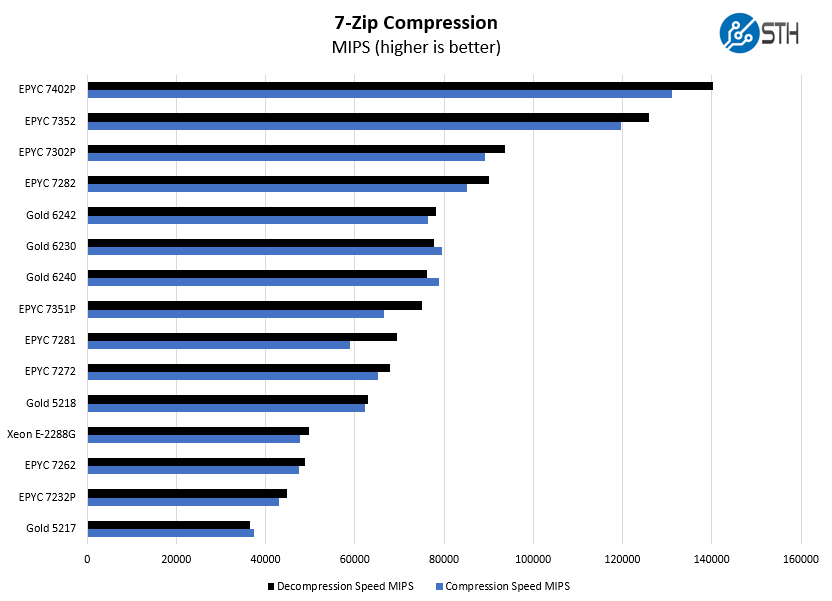
On the compression side, we can see that there is a large gap between this processor and the AMD EPYC 7232P. The “P” series part is a single-socket only SKU with 8 cores and is only $175 less costly based on list pricing. In contrast, an EPYC 7272 can run in two-socket systems as well. Unless that $175 is more important than a large performance uplift, we suggest that this is a better value than the lower-end part.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. With GROMACS we have been working hard to support AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
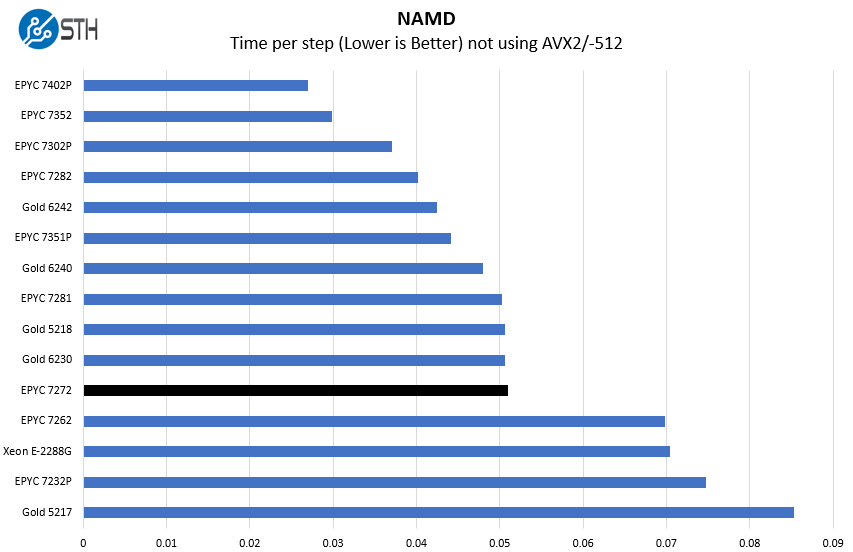
Here we can see a great performance, almost rivaling many higher-end parts that have prices measured in multiples of the EPYC 7272 list price.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
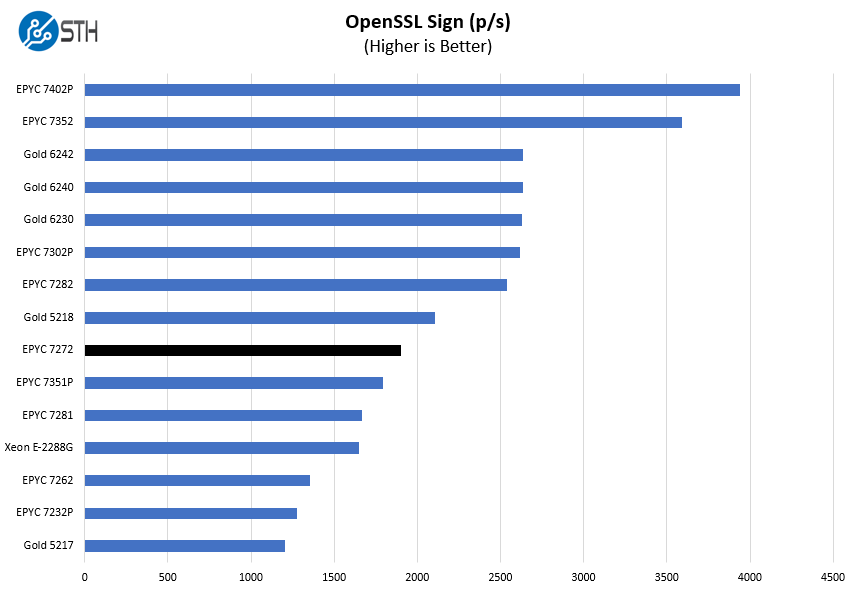
Here are the verify results:
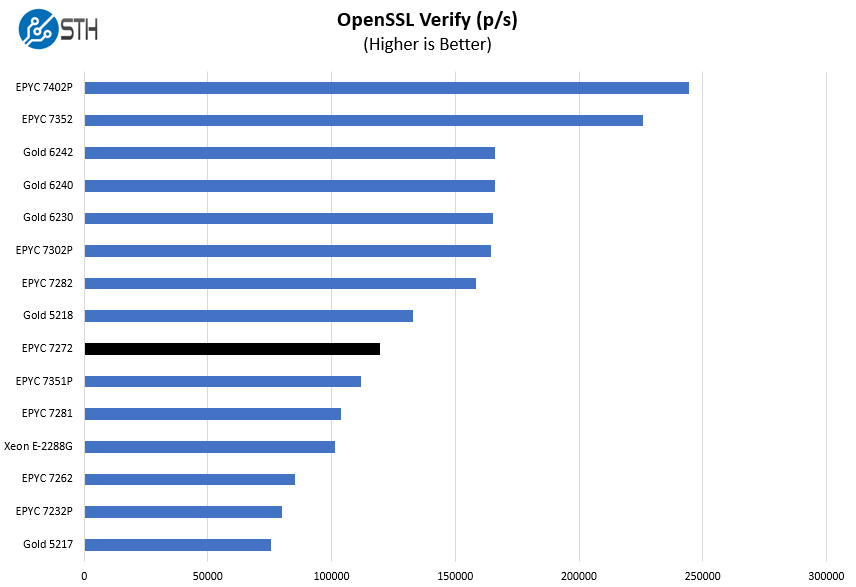
On the OpenSSL side, we can see performance besting some of the previous-generation 16 core parts even at a lower TDP. That is a strong showing.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
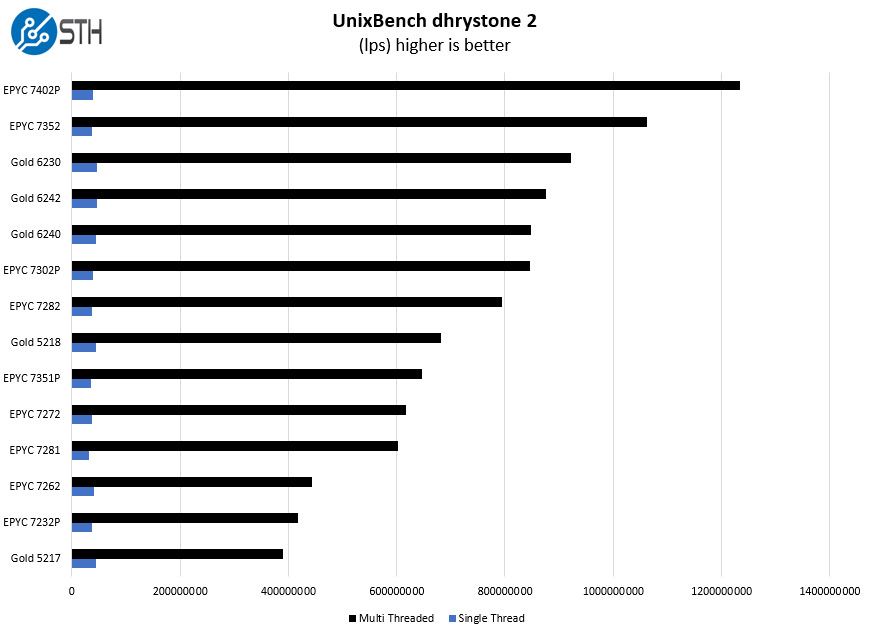
Here are the whetstone results:
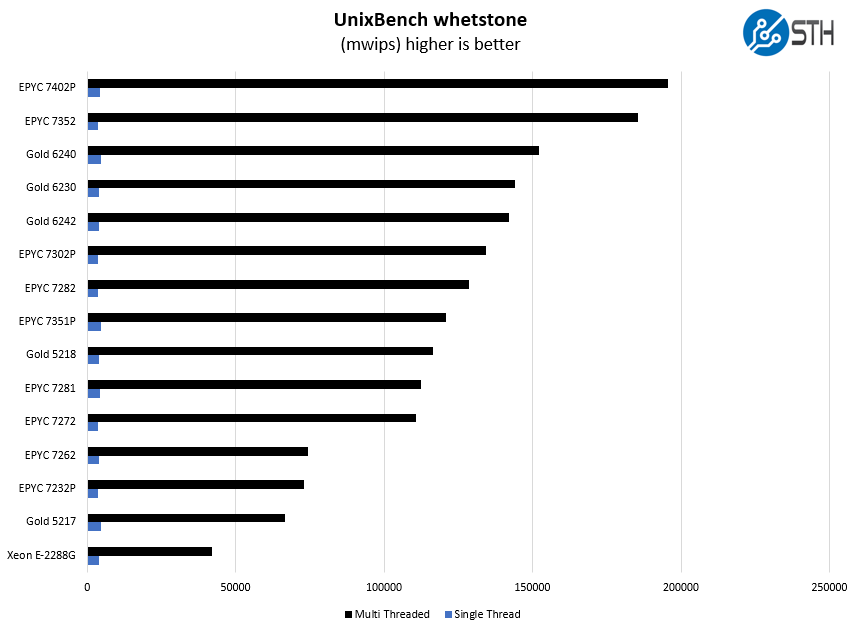
Here we see 12-core results in the same range as previous-generation 16-core results. AMD saw a noticeable IPC increase in this generation, however, the bigger impact is moving from four NUMA nodes even in these smaller core count chips to one. This greatly decreases complexity for the parts.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
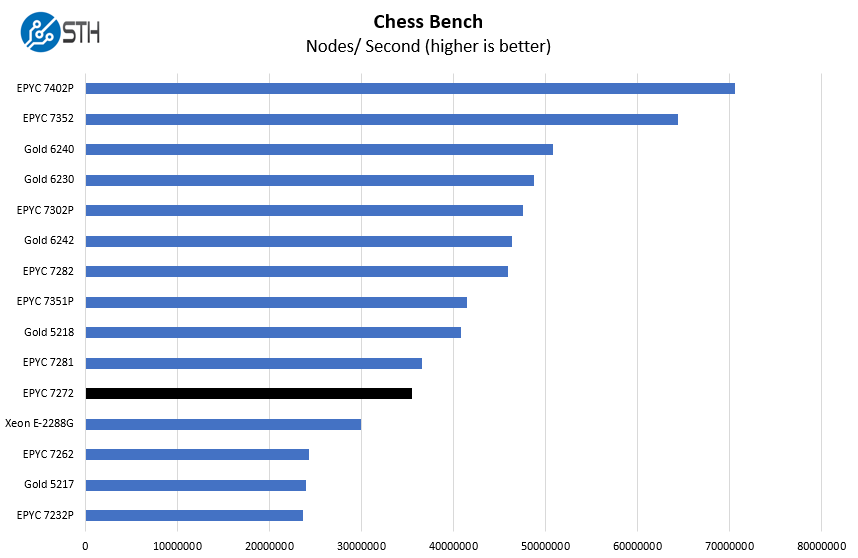
We wanted to quickly point out here that even in very good cases for the Intel Xeon E-2288G, the EPYC 7272 still comes out on top. The Xeon E-2288G is about $85 less expensive and has higher per-core performance, but the EPYC 7272 can be a better fit in some applications.
Next, we are going to look at the AMD EPYC 7272 market positioning before moving to our final words.


{kind=link}
Seem like the 7282 is a way better deal than the 7272. 4 more cores, same TDP, relatively cheaper (7272 – $$693.76 on NewEgg, 7282 – $715.99 on NewEgg).
Will C – Our 1P 7282 testing is complete. That should be the next EPYC “Rome” piece in the pipeline.
Patrick, thanks for the hard work. Looking forward to it.
You need to add some thread limited benchmark to your test suite. Far from all workloads scale well over two digit number of threads. On the other hand, single core performance is not very useful either for server applications. I would say a 4 thread benchmark would give us very useful information.
Many of us are asking the question if EPYC will beat Intel for applications bottlenecked to a handful cores single thread throughput.
If none of your benchmarks show that EPYC 7762, which is the high frequency optimized 155W part, beats the 120W EPYC 7272 for anything, there is something wrong with the benchmark suite.
Comments are closed.