
It is that time of the year again. No, not Christmas (unless you are an AI developer, at any rate), but rather NVIDIA’s annual GTC conference for all things NVIDIA.
As has become an annual tradition for us at STH, we are are covering the 2026 GTC keynote live, to catch all the latest and greatest in announcements from NVIDIA. And this year’s show promises to be especially lively, as NVIDIA is ramping up for the launch of their Vera Rubin platform: the Vera CPU + Rubin GPU amalgamation that will form the backbone of NVIDIA’s next generation of server hardware – and eventually client hardware as well.
Local media is reporting that the show is expected to draw 30,000 attendees this year, which would be about 5,000 (20%) more than last year. As it is, the show has already overgrown the recently expanded San Jose Convention Center, and CEO Jensen Huang’s keynote for the last few years has been held at the nearby SAP Center in order to house everyone in a single building. Not unlike NVIDIA’s AI-fueled revenue, there seems to be no slow down in the growth of developer interest in NVIDIA’s wares, either.

Unfortunately, the signal reception at the SAP Center with 15K+ techies is lacking at best – both WiFi and cellular are all but saturated, thanks in part to everyone trying to publish news from the keynote – so the best seat in the house is the seat at your house, with NVIDIA’s live stream of the keynote. Which is where I am at, while Patrick is at the SAP Center to see NVIDIA’s keynote in person.
NVIDIA GTC 2026 Keynote Preview
So what is on tap for this year’s keynote? It would be selling GTC a bit short to call it just an AI conference, but that is not too far from the truth, either. Certainly, AI is the biggest part of NVIDIA’s portfolio in terms of revenue and revenue growth, and it is no coincidence that NVIDIA now bills it as an “AI conference.” So expect everything to have an AI element to it – even if it is just figuring out how to add AI to something that already exists.
From a hardware perspective, the headline news is expected to revolve around Vera Rubin. NVIDIA already gave Vera Rubin its introduction to the world back at the company’s CES 2026 keynote, so NVIDIA has already shown many of their cards (or rather, chips) so-to-speak. But the company’s CES presentation was relatively light on technical details. But with GTC being a more technical forum, we should be getting a few more details there – though if history is any indicator, the true nuts-and-bolts technical details will go out in blog posts and the like rather than making it into the keynote itself.

Looking at NVIDIA’s broader technology portfolio, there are two particular technologies we have not seen them discuss in much detail until now. The first is the company’s Context Memory Storage Platform, a key-value cache for storing massive amounts of inference context closer to the GPUs. This platform leverages NVIDIA’s BlueField-4 DPU and Spectrum-X networking hardware. But relatively little was said about it overall during CES 2026. Now that Vera Rubin is closer to shipping, hopefully NVIDIA will have more to say here.

Finally, the wildcard on the hardware side of matters will be how NVIDIA intends to integrate recent acquisition Groq’s technology. NVIDIA closed a deal on Christmas Eve of 2025 to hire a significant amount of the company’s senior staff, acquire the company’s physical assets, and also acquiring a non-exclusive license for Groq’s Language Processing Unit (LPU) technology. The reportedly $20 billion deal is a significant expenditure for NVIDIA, so they presumably have an important use for it.

From a technical perspective, Groq’s LPUs are in several ways the inverse of NVIDIA’s big iron GPUs. The SRAM-heavy LPUs are AI inference processors that excel in low-latency decoding – which is very handy if you want a quick time to first token. But they haven’t shown the same level of total throughput, something that NVIDIA’s GPUs excel at. As recently as the company’s Q4’FY2026 earnings, Jensen Huang told investors that the company would be sharing some ideas around it at GTC, with a goal of “extend[ing] our architecture with Groq as an accelerator in very much the way that we extended NVIDIA’s architecture with Mellanox.” So just what does NVIDIA have in mind for using Groq’s tech as an accelerator, and how quickly can they add that to their rack scale platforms? It sounds like we are going to find out today.
So for the answer to all of that, and a look into the next year of AI hardware and software technologies, come join us for our live blog coverage of NVIDIA’s GTC 2026 keynote. The presentation kicks off at 11am Pacific/2pm Eastern/18:00 UTC.
Since this is being done live, please excuse typos. If you want to watch along, here is the link:
As always, we suggest opening the keynote in its own browser, tab, or app for the best viewing experience.
NVIDIA GTC 2026 Keynote Live Coverage
It’s a few minutes before kickoff, and we are locked in for the next couple of hours. Though not without a bit of difficulty, as Patrick can attest to – his bus got lost on the way to the SAP Center.

At this point we are just waiting for the GTC 2026 keynote to kick off. It never quite starts on time; filling an off-site arena always takes a while. The official schedule is for the keynote to run for 2 hours once it starts – though if history is any indicator, it is likely to run a bit over. NVIDIA packs these presentations full of announcements and partner showcases, to say the least.

(Lyrics on the current song on the broadcast stream: You’re Going to See Something Amazing Today)
It’s now 10 minutes past the hour and we’re still waiting for the keynote to kick off. Sorry for the delay, folks.
(Lyrics on the current song on the broadcast stream: I live for days like these)

It is a packed venue today, to say the least. The SAP Center holds nearly 20K people for concerts.
The music has come to a stop. Here we go!
Opening, as always, with a video. “This is how intelligence is made.”
“Tokens have opened a new frontier, turning data into knowledge”

Robotics, automotive, and biomedical are the big themes of this video so far.
“And here is where it all begins.”
And here’s CEO Jensen Huang.

“We’re going to talk about technology. We’re going to talk about platforms.”
“And most importantly, we’re going to talk about ecosystems.”
Jensen is thanking everyone who is at the show this year. His broadcast crew, the companies sponsoring the event and attending it, the speakers for the technical sessions, etc.
“It all began here.”
It is the 20th anniversary of CUDA.

There are now thousands of tools and frameworks and libraries later. “CUDA is literally integrated into every single ecosystem”
In 20 years the installed base is now hundreds of millions of GPUs across countless industries. “The flywheel is accelerating.”
NVIDIA library downloads are “growing faster than ever.”
“The useful life of NVIDIA GPUs is incredibly high” thanks to the wide variety of applications available for CUDA. Jensen cites the new 6 year old Ampere GPU architecture as an example of this.
And the installed base is so large that NVIDIA is highly incentivized to develop optimizations for their entire platform – not just the latest GPU architecture, but all of their supported architectures.

“GeForce is NVIDIA’s greatest marketing campaign.” “This is the house that GeForce made.”
NVIDIA’s first programmable pixel shader GPU was 25 years ago.
The investment in CUDA consumed the vast majority of NVIDIA’s profits at the time. In hindsight, it worked out better than anyone could have imagined.
Continuing to recap NVIDIA’s history, Jensen is up to ray tracing and tensor cores.
The next generation? Neural rendering.
And a surprise preview of DLSS 5.


Announcing DLSS 5. 3D-guided neural rendering. “Probabilistic rendering.”
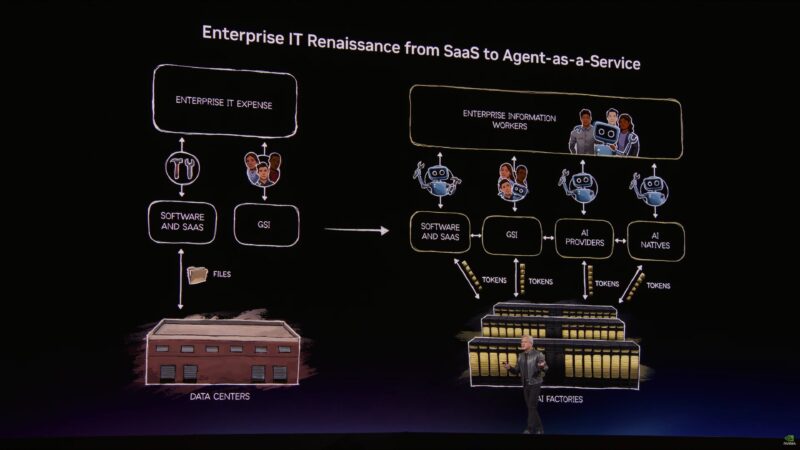
“Structured data is the foundation of trustworthy AI.”
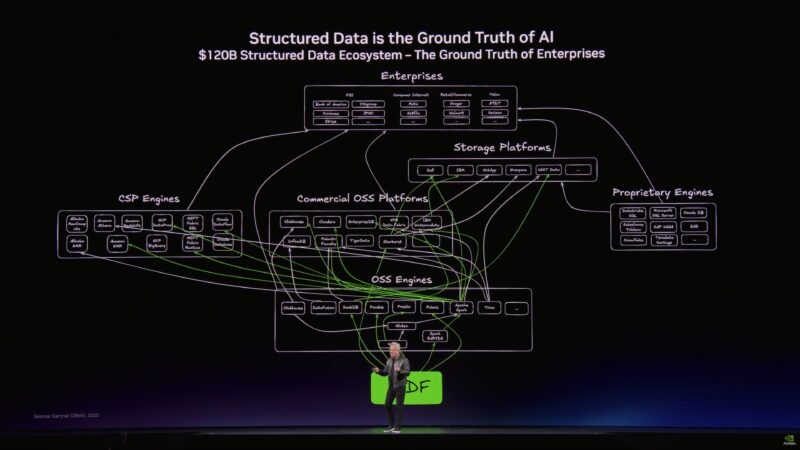
Jensen says this is his best slide of the presentation.
“This is the ground truth of enterprise computing.” Jensen wants to “accelerate the living daylights” out of it.
“Future agents are going to use structured databases as well.”
But the rest of the world is unstructured data. “Until now, this data has been completely useless to the world” due to the lack of indexing.
But AI can solve this problem. If AI can understand unstructured data, then it can index it; make it structured data.
Unstructured data is the context of AI.
Partner announcement: IBM is accelerating WatsonX with cuDF.
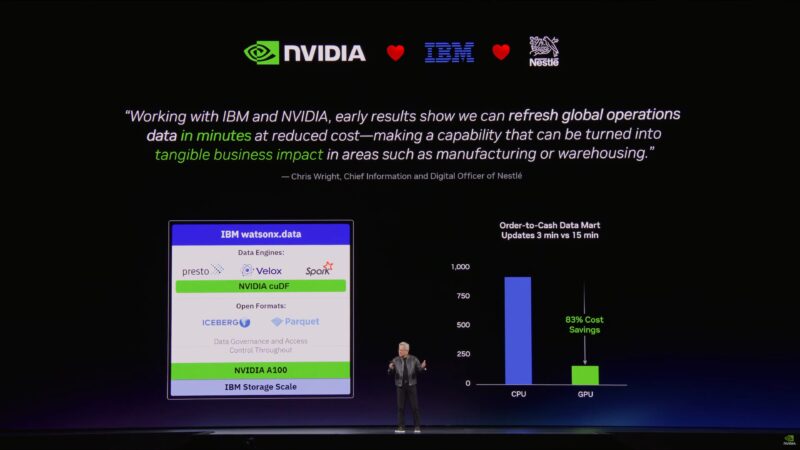
Now rolling a video from IBM.
Dell is here as well, and is working with NVIDIA on their Dell AI Data Platform.
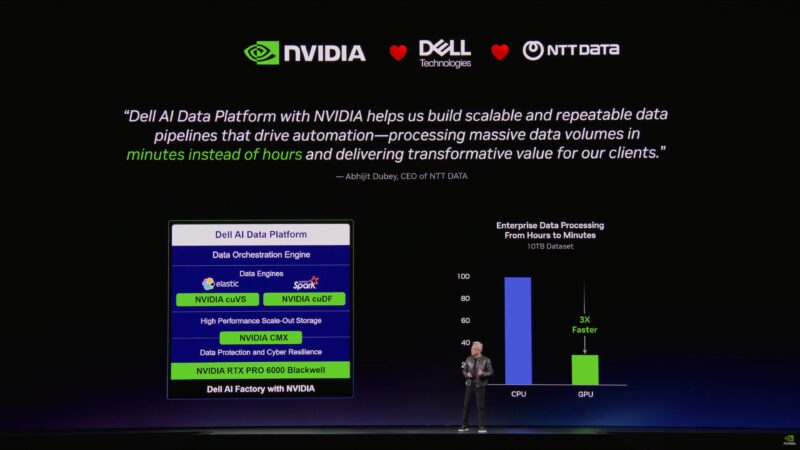
Continuing the partner plugs: NVIDIA and Google Cloud lowering the cost of computing.

Now on to a favorite topic of Jensen’s: the death of Moore’s Law. Accelerating computing backed by ever increasingly optimized algorithms is the replacement for Moore’s Law. (Optimize an algorithm once, and all of NVIDIA’s GPU users benefit)
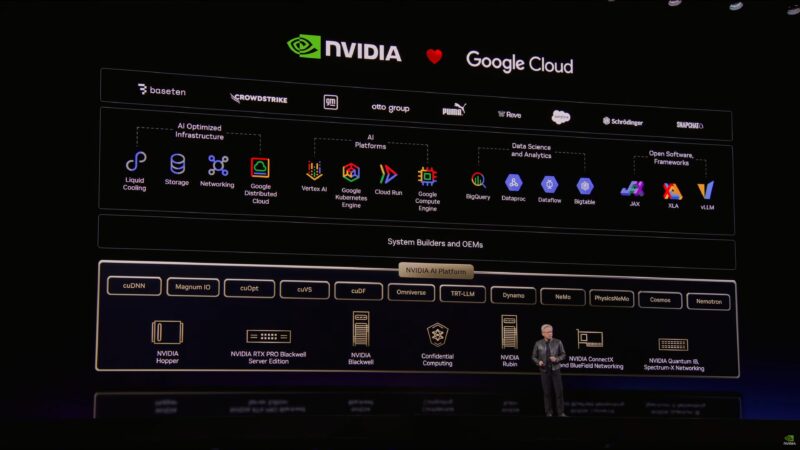
“Our relationship with cloud service providers are essentially us bringing customers to them” by accelerating those customers’ applications.
“There are a lot of customers. We are going to accelerate everybody.” “Just be patient with us.”

And NVIDIA is bringing more of their technologies to AWS this year as well.

Rattling off all the various Azure/Microsoft offerings that NVIDIA hardware accelerates these days, such as Bing Search.
Now pivoting to confidential computing. NVIDIA’s Vera Rubin generation of hardware is going to support compete confidential computing across both the GPU and the CPU (new).
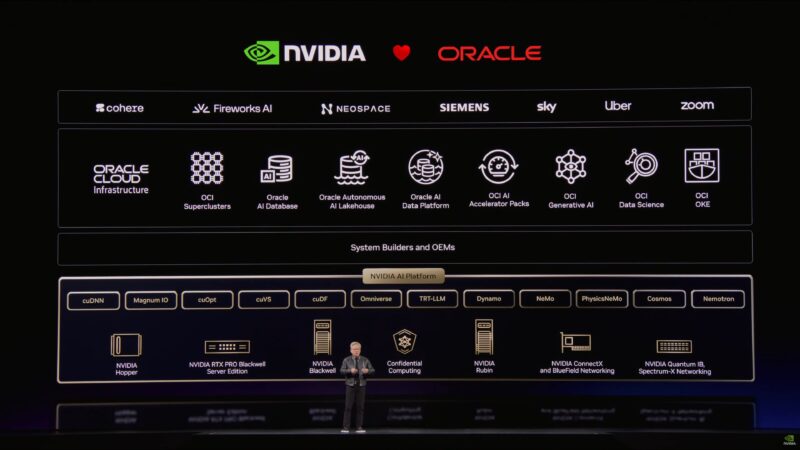
“We were Oracle’s first AI customer.”
The partner parade continues with CoreWeave.

Palantir and Dell as well.

“This is our special working relationship with the world’s cloud service providers.” “I want to thank all of you for the hard work.”
NVIDIA is vertically integrated, but wants to be a “horizontally open” company.
“The only way for us to accelerate applications going forward […] is through domain specific acceleration.”
NVIDIA has to understand the applications, domains, and algorithms in order to pull off the kind of accelerated computing ecosystem they want to build.
“We integrate with your technology so that we can bring accelerated computing to everyone in the world.”

Apparently the largest percentage of attendees at the show are from the financial services industry. (Jensen hopes they’re developers, and not traders)
Jensen is now touching upon NVIDIA’s various verticals. Automotive, industrial, healthcare, robotics, and more.
“We have 110 robots here at the show.”
Meanwhile “AI will run at the edge.”
“We are an algorithm company.” “That’s what makes it possible” for NVIDIA to tap into these industries.
NVIDIA will be announcing around 100 CUDA-X libraries at this year’s show. Jensen considers them the crown jewels of the company.
Now rolling a short video about CUDA-X.

“At their foundation are algorithms. And they are beautiful.”

And now a long sequence of clips showing the many different major companies using NVIDIA’s libraries, and how they’re using the tech for simulation purposes. “Everything was completely simulated.”
And that’s CUDA-X.
Now Jensen is speaking a bit about the many, many small and new companies at the show. The “AI Natives.”

According to Jensen, the investments into the AI Natives has skyrocketed over the past year.
This is the first time in history that each of these companies needs compute.
“We are now at the beginning of a new platform shift.”
3 things happened in the last two years to kick this off: ChatGPT, reasoning AI (e.g. o1), and agentic models (e.g. Claude Code).
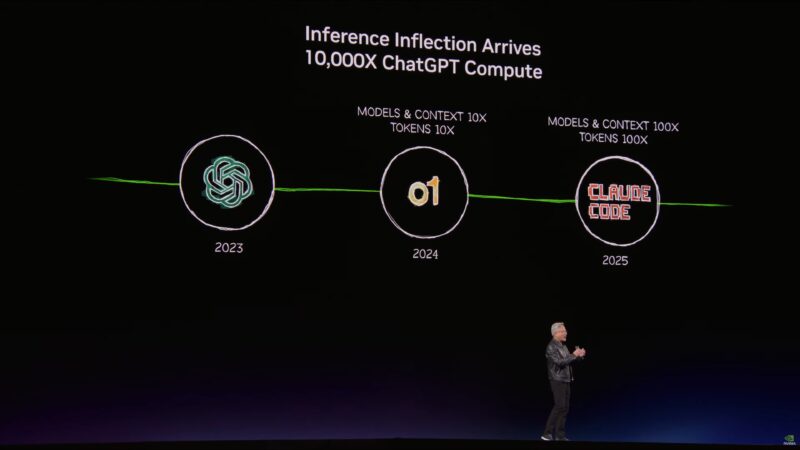
Reasoning has helped AI reach the ground truth. But the number of tokens consumed and produced has exploded.
All of which is driving incredible demand for NVIDIA’s hardware.
“The inflection point of inference has arrived.”
Every time AI thinks or does, it has to use inference.
Jensen believes they’re at the point of a positive feedback loop. More hardware leads to more AI leads to more breakthroughs.
“Right now, where I stand, a few short months after GTC DC [..] I see through 2027 at least 1 trillion dollars” of computing demand.
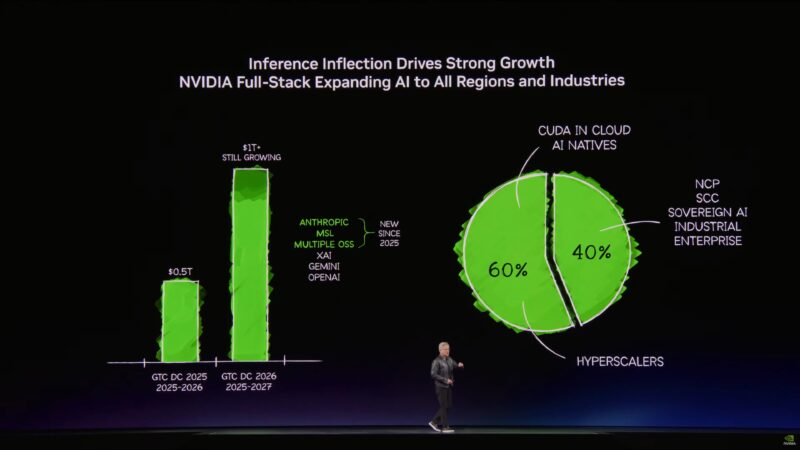
Apparently the subject of inference inflection will be what Jensen talks about for the rest of the keynote.
Jensen is making the argument that companies can build infrastructure around NVIDIA’s hardware in complete confidence. NVIDIA has the scale and the support to be that reliable foundation.
60% of NVIDIA’s business is the top 5 hyperscalers. The other 40% is just everywhere else. Industrial, robotics, sovereign AI.
“The span of AI is its resilience.”
Jensen says that NVIDIA’s job is to advance the technology.
Now recapping the introduction of Grace Blackwell and the NVL72 rack systems. According to Jensen it was a big bet, and he’s thanking NVIDIA’s partners for all of their work in bringing it to market.
“Inference is the ultimate hard. It’s also the ultimate important because it drives your revenues.”
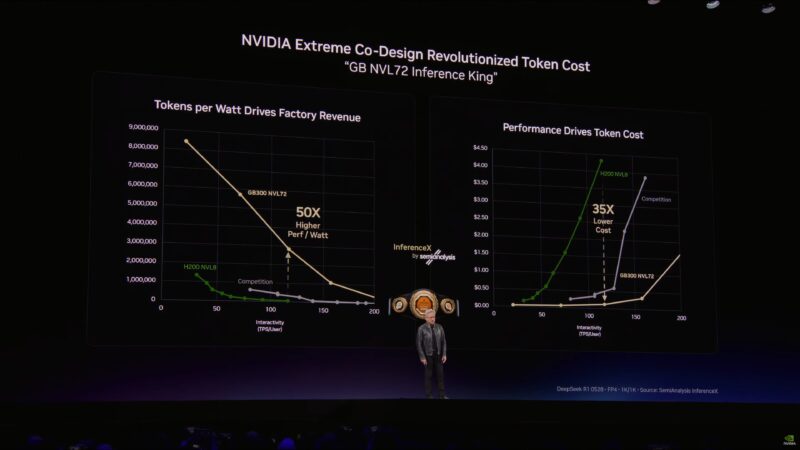
Power is the constraining factor these days. Datacenters are measured in gigawatts. Datacenter operators want to get as much performance as they can out of that fixed power budget.
“The faster you can inference, the larger the models.” The X axis in this chart is effectively how smart an AI is.
NVIDIA is beating Moore’s Law. GB300 NVL72 is offering 50 times as many tokens per Watt.
Cost per token? Not quite as impressive; it’s only “35x” (~3%) of the cost of Hopper.
“NVIDIA’s token cost is world class”

“Inference service providers” are growing incredibly fast.
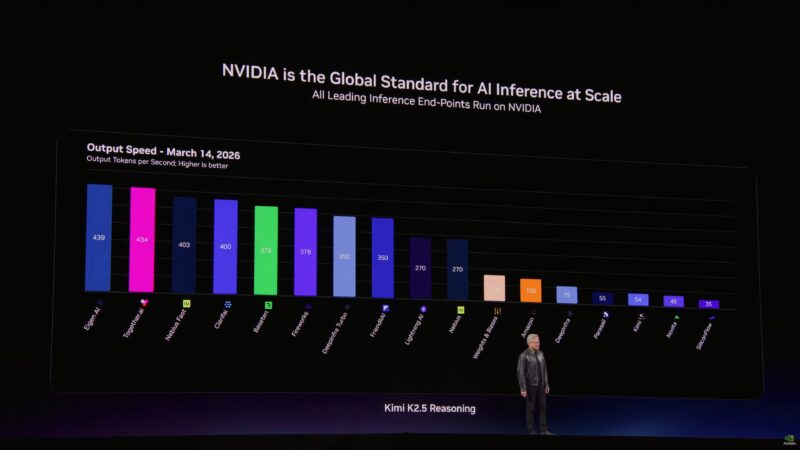
Jensen is outlining the benefits of NVIDIA’s style of extreme co-design.
(We are now solidly in to the token factory analogy with Jensen)
Now rolling a video about NVIDIA’s DGX offerings DGX-1 to present. “How we got here.”

Most recently, Blackwell introduced NV72, the largest scale-up configuration of an NVIDIA GPU system so far.
And now Vera Rubin. Vera Rubin NVL72.

And now NVIDIA is quickly going through all of their rackscale systems. Besides the GPU NVL72 systems, there are Vera CPU racks, STX servers, networking, and more. 7 chips, 5 rackscale systems. 40,000,000x compute in just 10 years.
Jensen is lamenting that he can’t just hold up a single chip anymore. Now it’s about entire systems; optimized as one giant system.

Inference is going to be pounding memory and storage incredibly hard. And AI won’t tolerate slow computers.
Powering so much of that is Vera, NVIDIA’s newest CPU.
Vera Rubin is liquid cooled. “All of the cables are gone.”

Cooled by 45 degree hot water.

And NVIDIA has a Groq hardware node.

NVIDIA is going to be selling Vera CPUs standalone. Including a standalone rack, as evidenced by the node in the middle.


256 liquid cooled nodes in one rack.
“Do you guys want to see Rubin Ultra?”

Rubin Ultra doesn’t slide in horizontally like a normal rack. It goes in to NVIDIA’s new Kyber racks to allow for 144 GPUs in a single rack.


Compute in the front, NVLink in the back. One giant computer, installed vertically.
“This is probably the single most important chart for the future of AI factories”

Token input and output lengths are growing. “Tokens are the new commodity”
Jensen is talking about different tiers of service. Free, High, Premium, Ultra. All organized by token speeds – the faster the token speed, the higher the tier.
The future is the “ultra” tier.
Now showing how the performance curves have increased over successive generations.
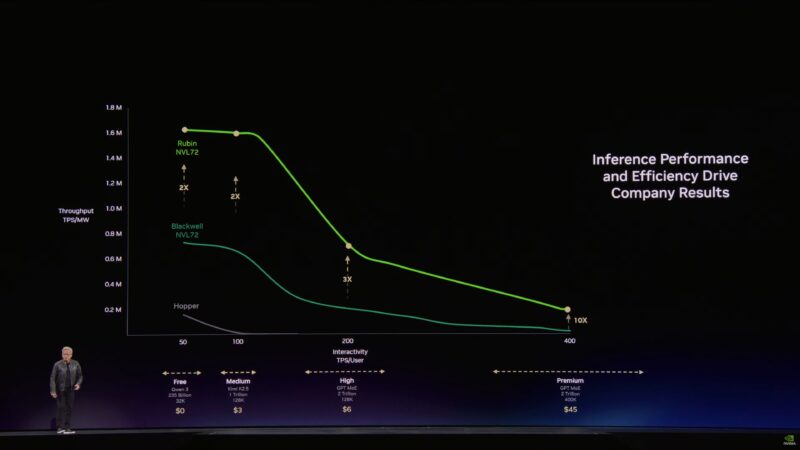
NVIDIA has increased performance across every tier. But the biggest gains have been at the highest (most profitable) tiers.
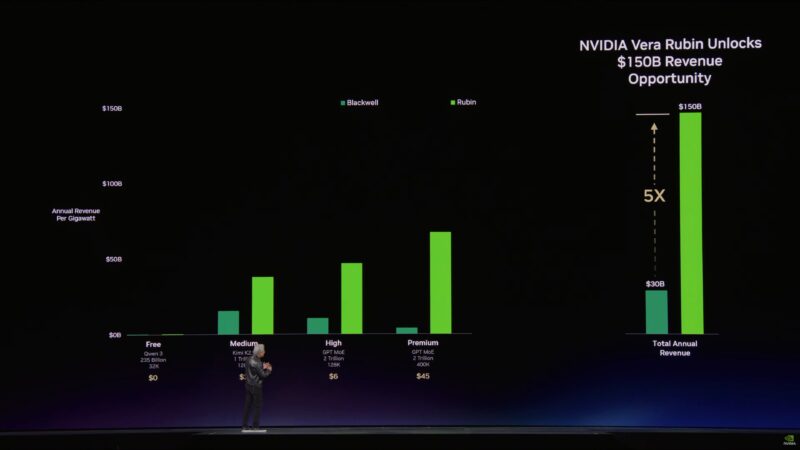
So Vera Rubin allows for generating 5x the revenue.
“We want even more.”
“Optimizing for high throughput and optimizing for low latency are enemies of each other.”
Now with Groq:
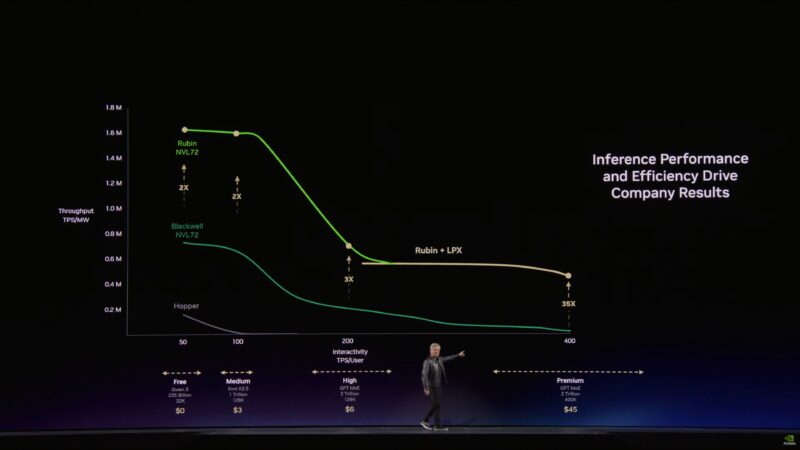
NVIDIA says the addition of Groq’s hardware allows them to deliver 35x more performance at extremely high token per second rates. It comes in where NVL72 runs out of bandwidth.
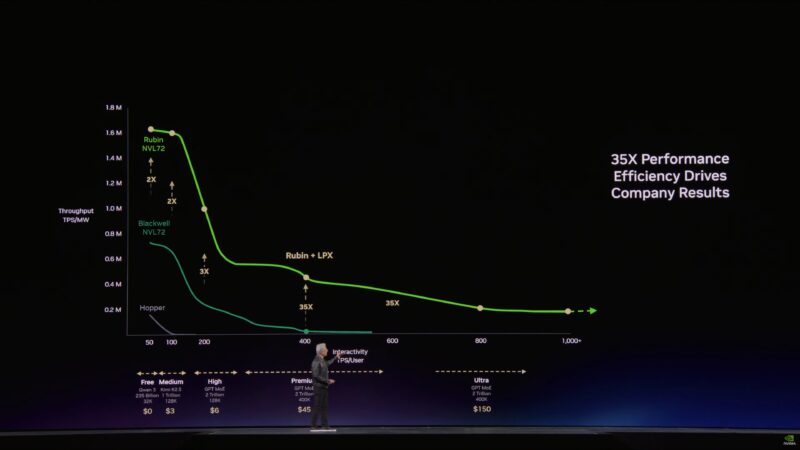
Paraphrasing: if your workload is just high throughput, stick to Vera Rubin. But if you need more interactivity, add Groq to part of your datacenter.

Groq’s LPUs are deterministic. Everything is scheduled in software. There is no dynamic scheduling.
The one workload that LPUs excel at is exactly where NVIDIA needs the help. NVIDIA’s GPUs excel at the kind of throughput that Groq’s LPUs didn’t.
So NVIDIA is going to combine the two; using Groq as an accelerator for Rubin.
NVIDIA is going to add a lot of Groq chips in order to get enough total memory.
“Disaggregated inference” prefill is done on Vera Rubin, while decode is done on the LPU.
NVIDIA runs Dynamo on top of all of this to organize and orchestrate it.
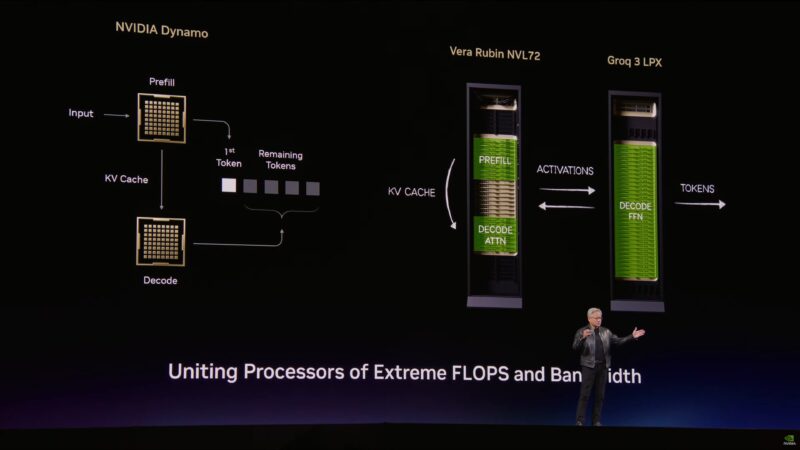
Samsung makes the Groq LP3 chip. NVIDIA expects to ship it in H2 of this year, likely Q3.

Meanwhile the sampling of Vera Rubin is going very well. Azure already has their first rack setup.
“We are in full production”

And “100%” of the storage industry is joining NVIDIA on the BlueField-4 STX KV cache.

And this is the Vera Rubin system.
Jensen says that NVIDIA is set to deliver a 350x increase in token generation performance.

Is NVIDIA going to scale up with copper or optical? They’re going to do both.
Oberon and Kyber will sit side-by-side.
NVIDIA is also working on developing a new chip, LP35, a new LPU with NVFP4 capabilities.
After the current generation is Feynman in 2028. New GPU, new LPU (LP40) that Jensen says will be a big step up. A new CPU, Rosa (Rosalin?), NVLink 8. Kyber will have copper and CPO scale-up.
It sounds like NVIDIA is hedging their bets on scale-up networking. NVIDIA needs a lot more capacity for both.
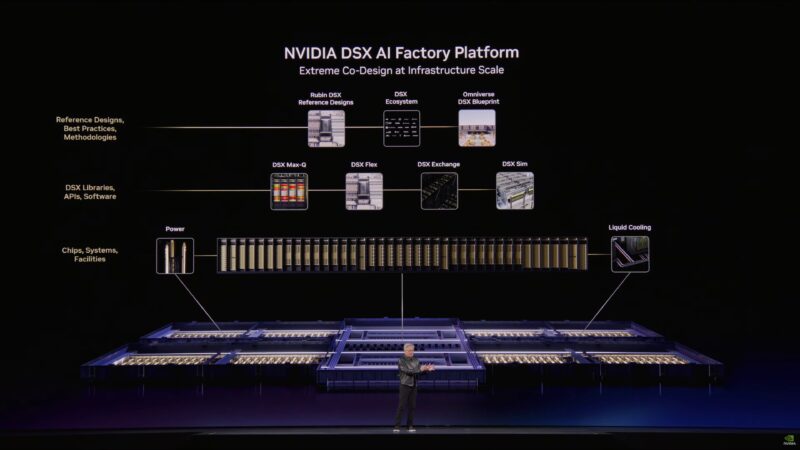
And to help clients build these kind of large-scale rack systems? NVIDIA has created a blueprint, the DS AI Factory Platform, to simulate this and show clients how to build, adjust, and operate these systems.
Now rolling a short video about DSX.
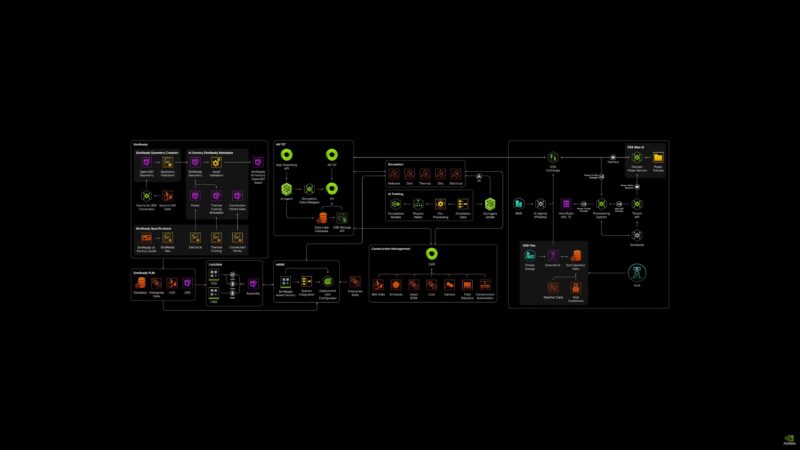

It is essentially a holistic view of a data center. Monitor the power inputs, monitor the workloads being run. Run everything at the highest efficiency level possible (Max-Q).
And that is DSX, NVIDIA’s new AI Factory Platform.
NVIDIA has ambitions for space, as well.

NVIDIA is developing a Vera Rubin space module, the Space-1, that can be deployed in space assets.
Switching gears again to OpenClaw.
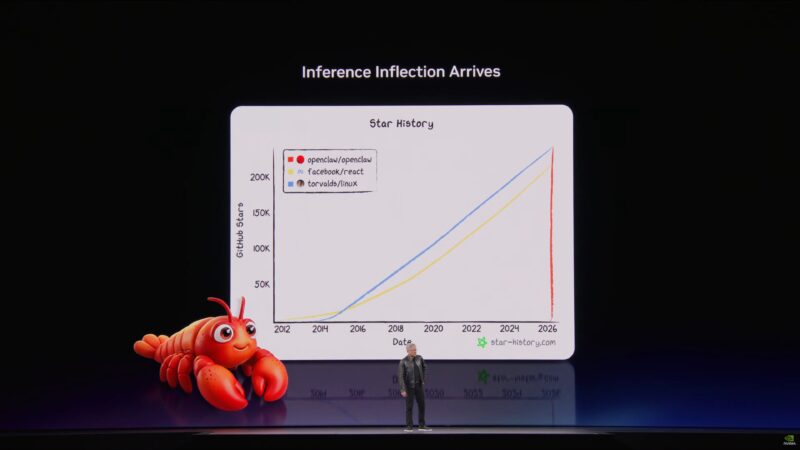
OpenClaw exploded practically overnight. Jensen considers it already one of the most important open source developments of the last 30 years. And NVIDIA wants to be there to support it.

NVIDIA NemoClaw for OpenClaw.
OpenClaw has become the embodiment of Jensen’s case for agentic AI.
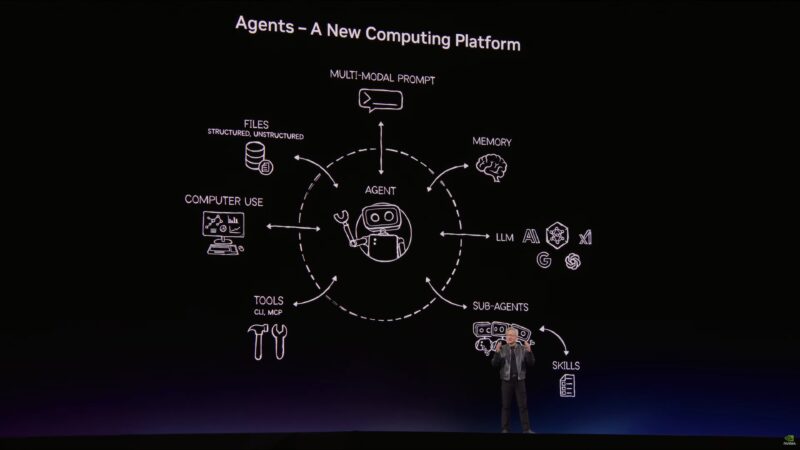
OpenClaw can invoke agents for specific tasks. But it also has I/O – the ability to read and write out in to the world.
Jensen likes to think of OpenClaw as an operating system for personal agents.
“Every company in the world needs to have an […] agentic system strategy.”
NVIDIA has been working with OpenClaw’s developer to make OpenClaw secure for enterprise use.
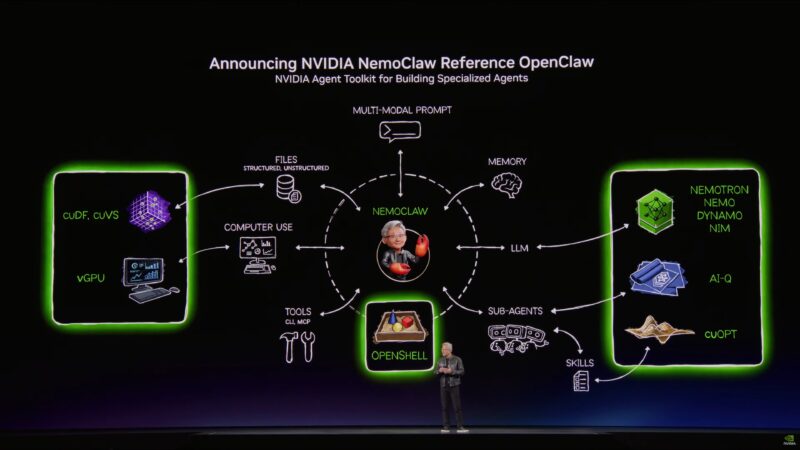
OpenClaw is now enterprise-ready.
Now rolling a video about NVIDIA and open models.

“Our models are valuable to you […] because we’re not going give up working on them.”


Jensen is announcing a new Nemotron coalition. Companies that will be partnering with NVIDIA on Nemotron 4.

Working together to advance open frontier models. LangChain, Perplexity, Mistral AI, Thinking Machines, and others.
Meanwhile numerous companies are partnering with NVIDIA to integrate Nemotron into their software and services.
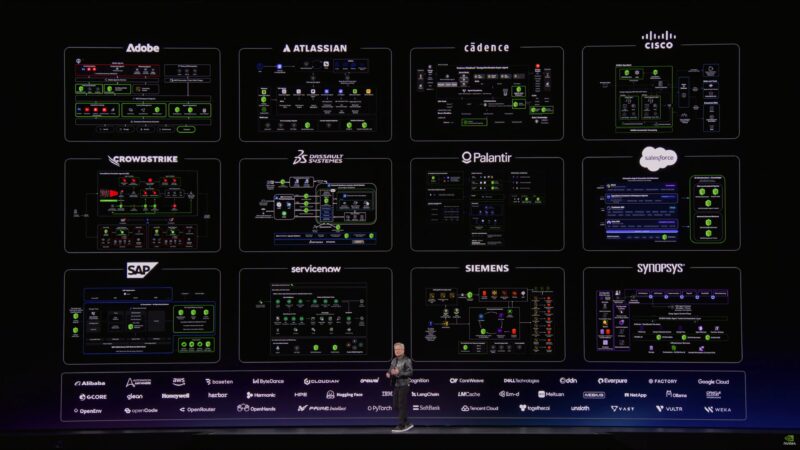
“This is going to become a multi-trillion dollar industry.”
Jensen envisions every engineer needing an annual token budget to spend on compute. “How many tokens comes along with my job.” Tokens will make engineers more productive.
“Every single software company of the future will be agentic.”
“The OpenClaw event cannot be unstated. This is as big of a deal as HTML.”
Now switching gears to robotics – physical AI.

NVIDIA has been pushing hard on robotics, and continues to do so. Dozens of robots are at the show. NVIDIA has a slew of software and libraries for the task.
Today NVIDIA is announcing four new partners for its Robotaxi-ready platform. BYD, Hyndai, Toyota, and I missed the 4th.

Now rolling a video on robotics.
The first global rollout of AI: autonomous vehicles.

“This is the age of physical AI and robotics.”


Now for Jensen’s seemingly annual Disney robotics demo: Olaf.

Temperatures in San Jose are in the mid-to-upper 80s today. The irony of a snowman robot for a demo is not lost.
Now rolling another video to close things out.

(Recapping a 2 hour keynote with a song. Well, this is certainly different)

And that’s a wrap. Thank you for joining us for our keynote coverage. We’ll have deeper dives into the various hardware announcements throughout the week.



{kind=link}
They didn’t mention/show the Rubin CPX. Is it cancelled after buying Grow for some reason?
@Ziple
I’ll have more on this in our full Groq LPX article. But for the moment, when asked about CPX, NVIDIA’s official response is that they’re fully focused on integrating Groq LPUs into the Rubin platform. So make of that what you will.