
This is one of the more interesting announcements that we had not been expecting until pre-briefing materials came out. There is a new d-Matrix JetStream 400Gbps Ethernet card for scale-out AI inference. The goal is to provide a path to scaling out to multiple chassis using off-the-shelf networking infrastructure.
New d-Matrix JetStream 400G Ethernet Card for Data Center Scale AI Inference
First off, this is the d-Matrix JetStream. It is a PCIe network adapter designed for the company’s AI inference servers.

Apparently, many sites out there decided to parrot the press release, but did not bother to look at specs. The card utilizes QSFP-DD, which is much easier to get non-NVIDIA switches for than OSFP at this point, and also if you go non-NVIDIA and the PAM4/NRZ makes things easier on the transceiver side as well. The card also has a 150W TDP, which means it requires an Aux connector for power, which is probably not ideal. Some NVIDIA cards, like its BlueField-3 DPUs also can require aux power inputs.
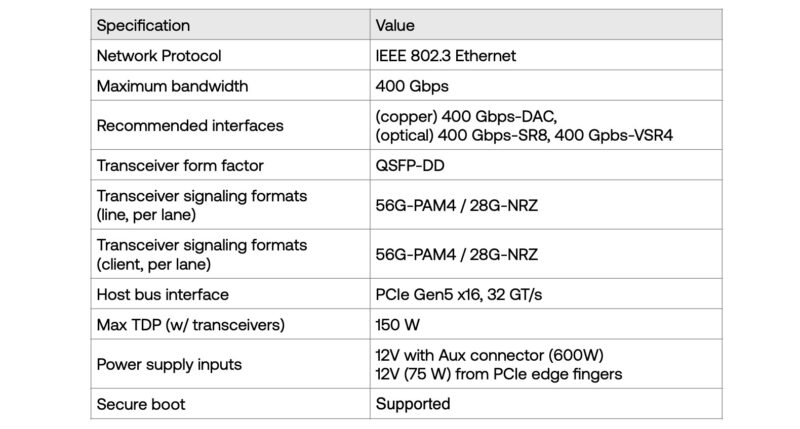
This is a PCIe Gen5 device, so it is more of a competitor to the NVIDIA ConnectX-7 than ConnectX-8 as it is a 400Gbps device.
The cards are designed for the d-Matrix Corsair AI Inference server. We recently covered d-Matrix Corsair In-Memory Computing For AI Inference at Hot Chips 2025. The company is using Supermicro’s 5U PCIe switch based GPU/AI server that we covered in our The 2025 PCIe GPU in Server Guide.

Something that is a small feature, that many may miss, is that the JetStream cards have a heatpipe on the QSFP-DD cages. In the Supermicro server, the cards are at the rear. Optics at the rear of AI servers tend to get warmer than in the front, so paying special attention to cooling the optics can be a huge benefit to reliability in AI clusters.

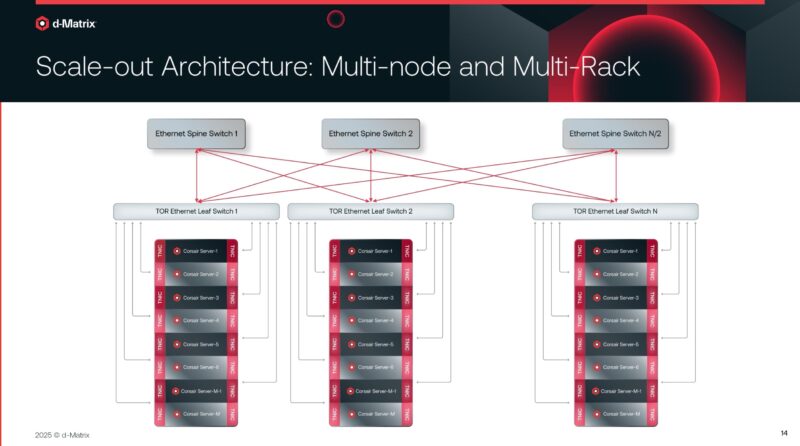
The PCIe root complex is fairly standard for Supermicro’s high-end servers with the 144-port PCIe Gen5 switches that are usually Broadcom in this class of Supermicro’s AI servers (Supermicro does have other options so we are not 100% sure.) Each switch gets four d-Matrix Corsair cards with a DMX bridge between pairs for high-bandwidth without going over PCIe. The card pairs can then traverse the PCIe switches to the other pairs. That still only gets you to eight cards in a system, so that is why the JetStream cards are there so that the AI accelerators can scale-out without having to go over PCIe.

Here is the company’s scale-out fabric topology. It is worth noting that with current generation 51.2T (102T switches are still coming to market) it is extremely common to see 64x 800G ports split using dual 400G optical modules to 128x 400G, or at least split to the AI server NICs, so the number of boxes that you can connect with a decent network radix these days if you have two 400G NICs per box is pretty awesome. That is a small point, but one that helps lower the cost of AI inference infrastructure.
The company has both its compute and memory stacked accelerator model for compute, but then also a roadmap for Scale-up Ethernet/ UALink in the future.

This is somewhat interesting that the company is releasing a NIC today, then looking to do an I/O chiplet in the future.
Final Words
There are many companies trying to make AI accelerators. Fewer are making accelerators and NICs. Even if those NICs are FPGA based. It would be interesting to know how much these cost because at 150W you would expect them to come in at a lower cost than ConnectX-7, AMD Pollara 400, Broadcom Thor and so forth to keep the system costs down. Perhaps one day we will get these in the lab.
If you want to see more about the 5U Supermicro boxes d-Matrix is using for Corsair, albeit with NVIDIA GPUs, you can see it with the NVIDIA H200 NVL and NVIDIA RTX Pro 6000 below.



{kind=link}
The product page URL seems to be missing from this article: https://www.d-matrix.ai/product/
What happened to Corsair and the 60k tokens/sec on Llama8B?