
SambaNova is a hot company since it does something a bit different focusing on AI acceleration with a focus on scaling to large models and memory. SambaNova’s approach requires some fairly heavy compiler work alongside the hardware. This is being done live and SambaNova has over a slide per minute so we are just going to try doing the best to capture as much as possible.
SambaNova SN10 RDU at Hot Chips 33
First, getting into what this Cardinal SN10 RDU is. SambaNova calls its chip a Reconfigurable Dataflow Unit or (RDU.) They will get into why they call it this later. Beyond the linear algebra units, there is a big focus on routing and the on-chip memory bandwidth.

SambaNova is not just thinking in terms of a PCIe expansion card. Instead, it has systems that it sees as scaling. As an example, it has 8x RDUs in each SN10-8R using around a quarter of a rack. Each RDU has six-channel memory so that is 256GB per channel and 48 channels with 12TB total. The slide says DDR4-2667 but in Q&A the company also mentioned DDR4-3200.

The software side is extremely important the software needs to be very aware of the underlying architecture as well as the model to be able to efficiently use the RDU.
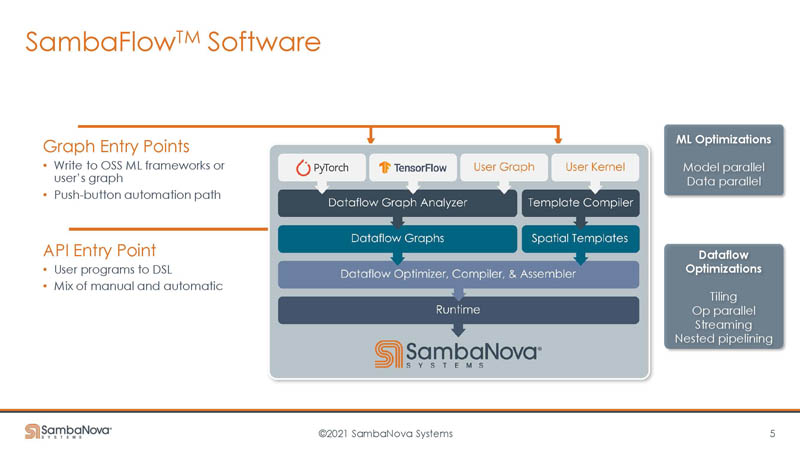
Something SambaNova’s software does is to map communication and then compile that communication to the underlying hardware.
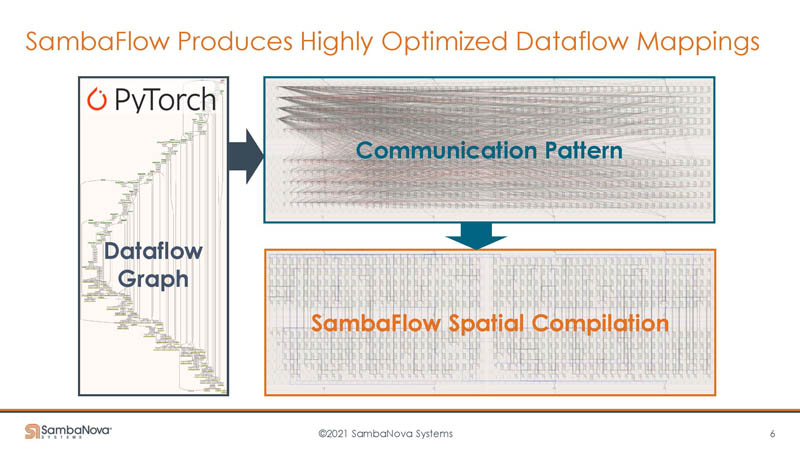
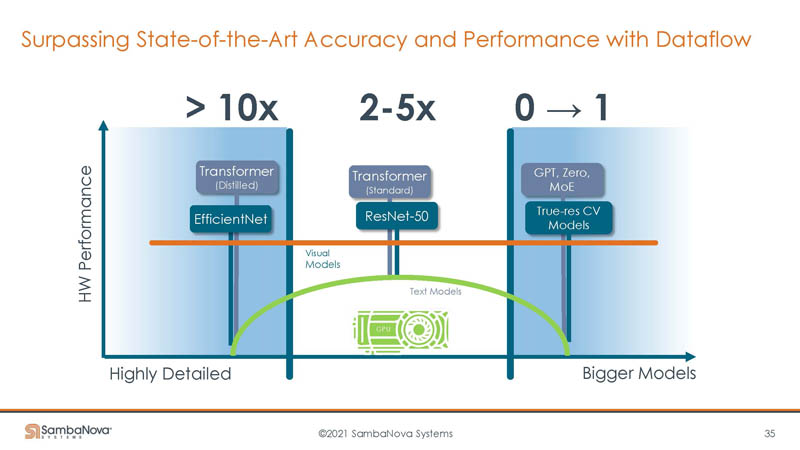
The key insight behind the company is that GPUs do very well in a specific zone of problems. Some models are unable to use the hardware efficiently. Other models are simply too big for the onboard memory. As a result, they do not work well on GPUs and therefore are often lower performance.
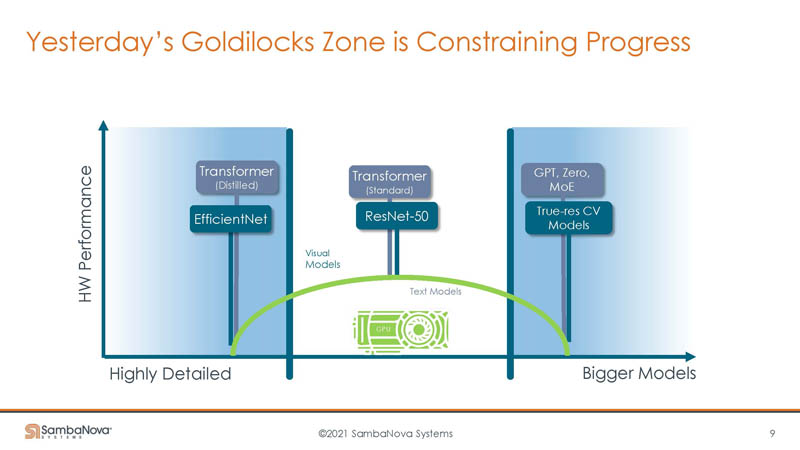
SambaNova’s data flow has many compute and memory units to exploit parallelism. It also has the ability to exploit data locality.
Here is the chip architecture.

Here is the tile deep dive. We can see the tile is made up mostly of three key components, switches, pattern compute units, and pattern memory units. We are going to see an example later that should make SambaNova’s RDU make more sense if you are struggling later.
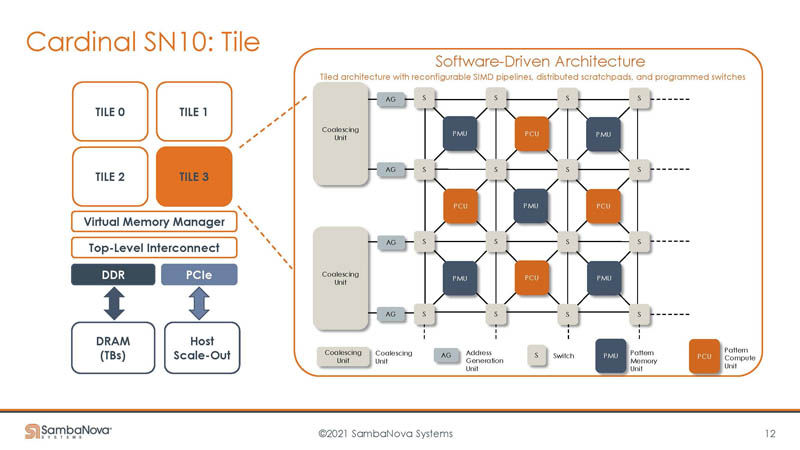
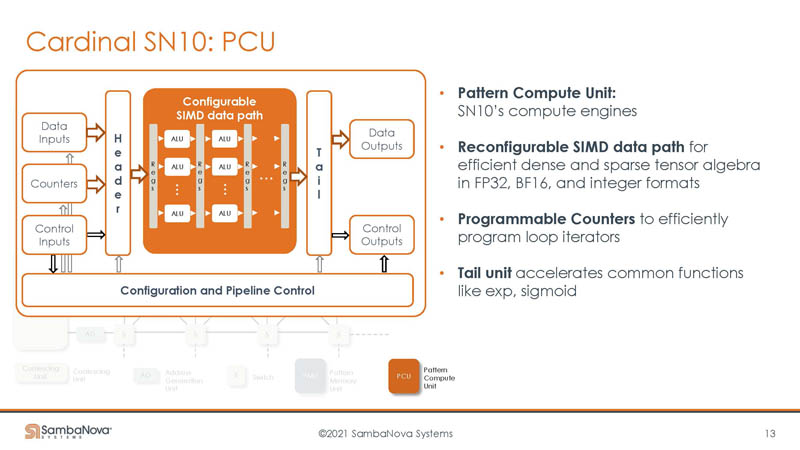
The Pattern Compute Unit are the compute engines with the SIMD paths.
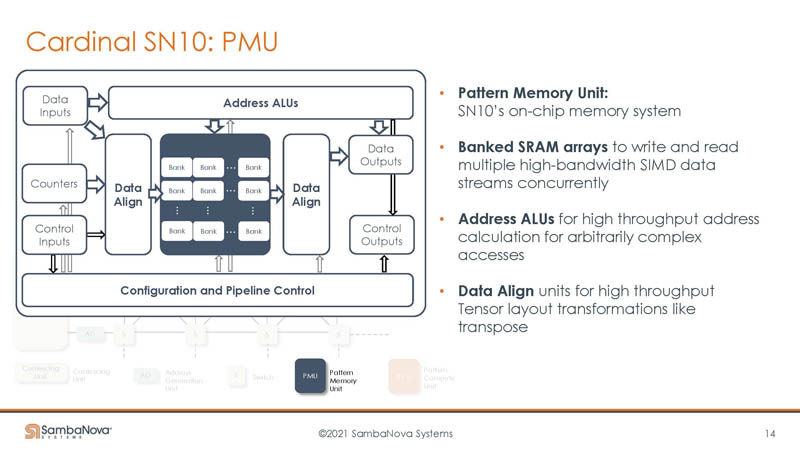
The other big unit is the Pattern Memory Unit. This is the on-chip memory system with banked SRAM arrays.
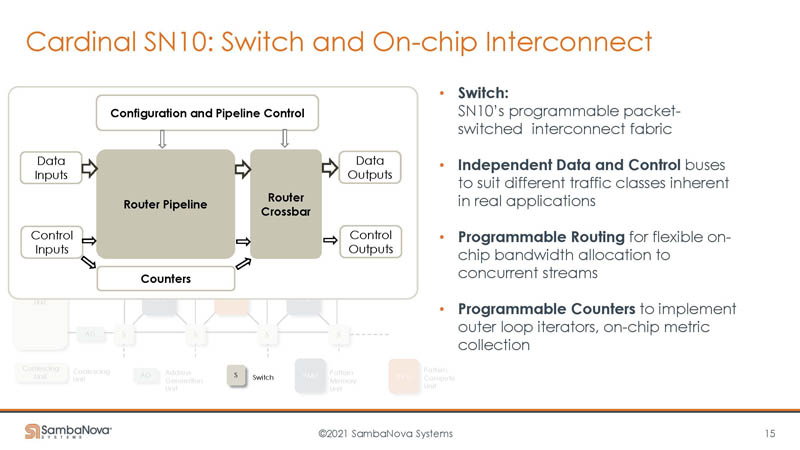
The switch has a router pipeline and router crossbar. This is the component that helps direct data to and from the PCUs and PMUs.
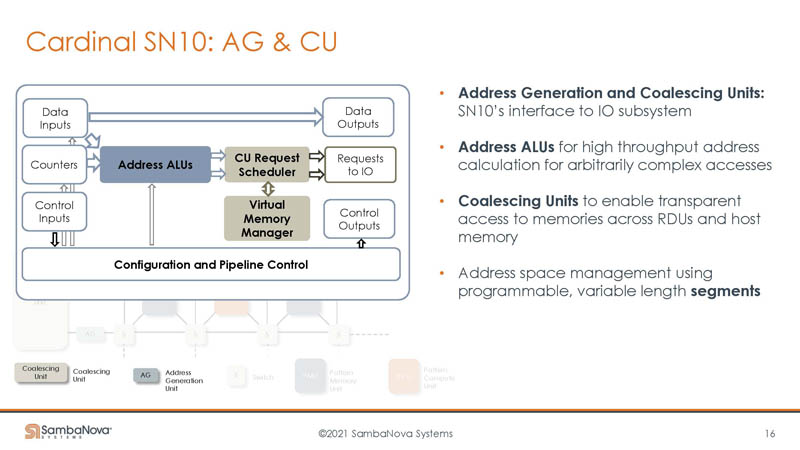
There are also address generation and coalescing units.
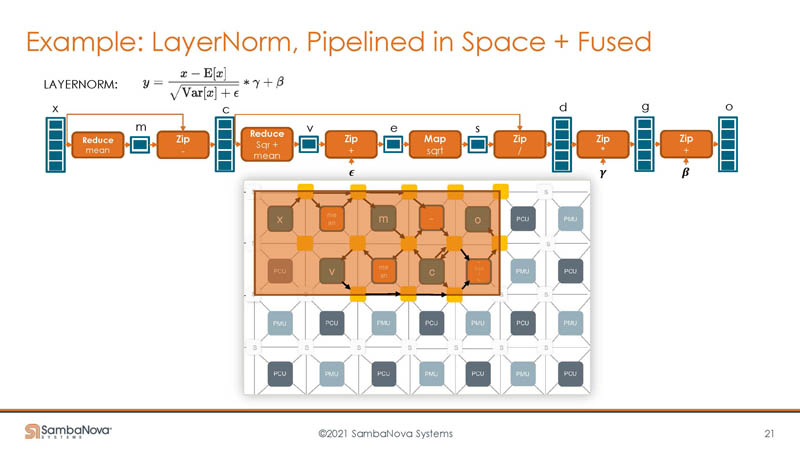
Here is a part of the example using LayerNorm. One can see the different steps where computations are happening alongside data changes on the top. Instead of just doing these sequentially, the switches can be used to create a pipeline on the RDU where data can move directly to the adjacent step.
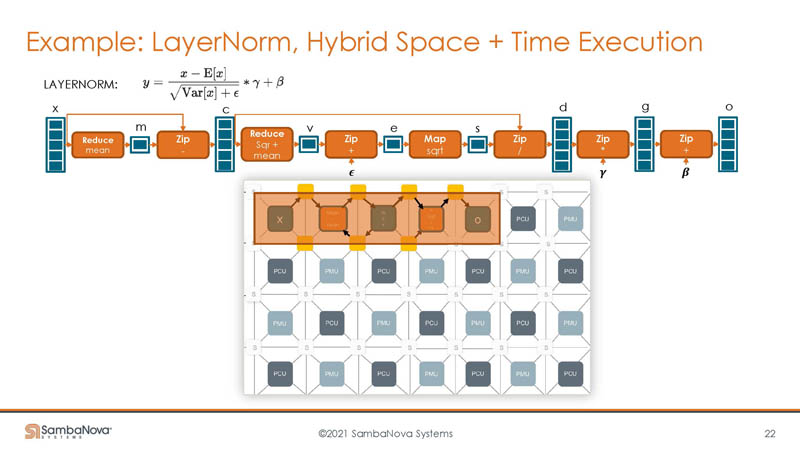
Then taking into account time and space, data can be focused on a smaller number of PMUs, PCUs, and switches. This adds the time component of when data needs to be where. The net impact is that fewer chip resources are used for a computation and thus more can be done on the chip. Combine this with the high-speed fabric and lots of memory off-chip in DDR4 and the solution can handle larger problem sizes.
Here is another example of the dataflow architecture with a bit more granularity.
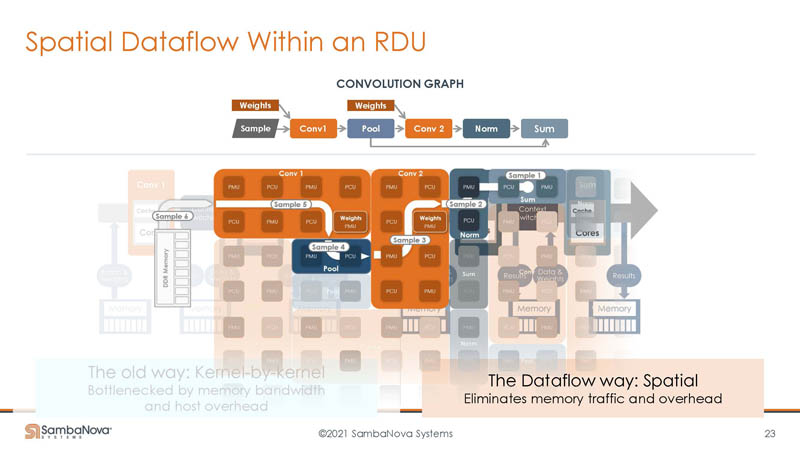
By doing this work, as a dataflow, models do not need to be hand-optimized kernel by kernel.
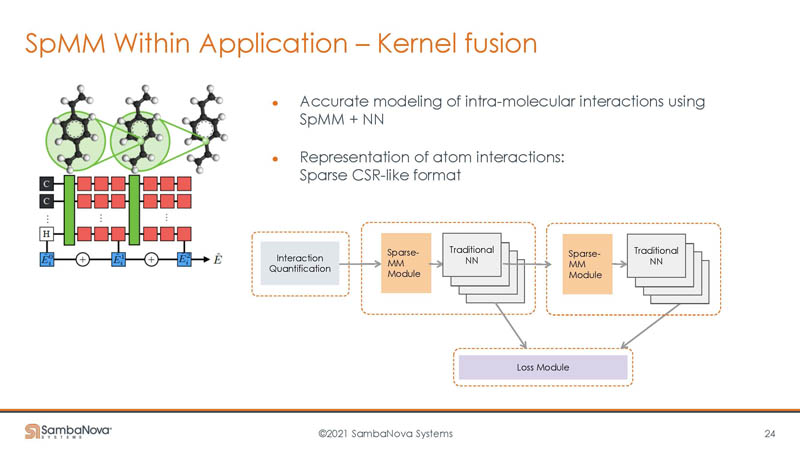
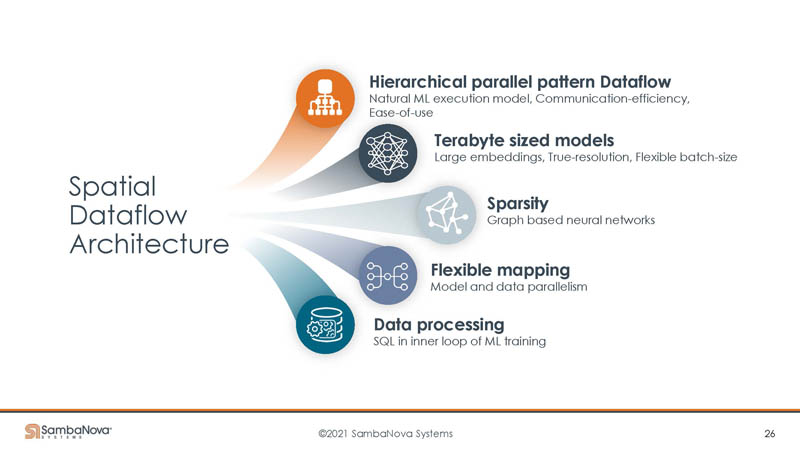
Here are some of the features of SambaNova’s solution.
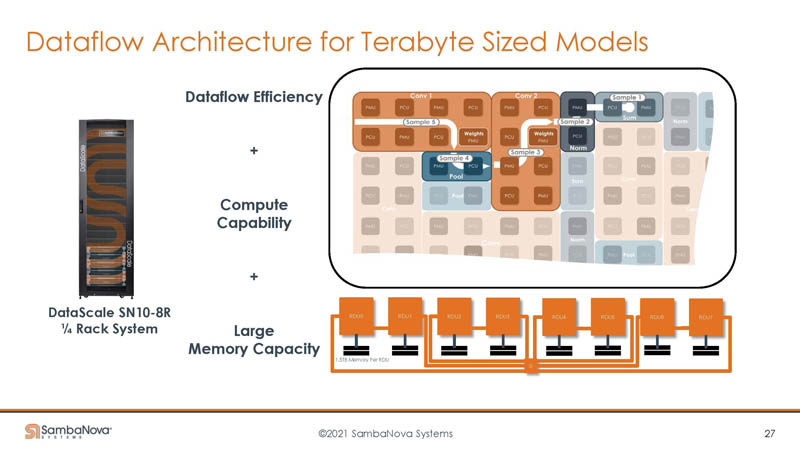
With the quarter rack system, we get 12TB of memory. As a result, this gives plenty of capacity to keep the chips fed.
If you are thinking that an approach like this requires really solid compiler work, it does. This approach is leaning on the software side heavily to map dataflows as part of its process.
SambaNova is trying to show multiple deployment examples.
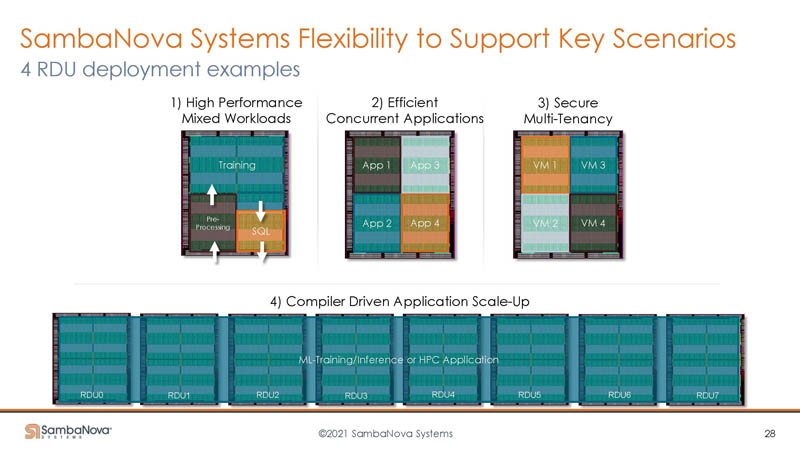
Perhaps the one it is most focused on is scale-out to a data center scale solution.

One benefit is that with scaling out and lots of memory, SambaNova says it can scale out to train large 1 trillion parameter language models without needing to split them up behind the scenes as one would need to do with (more) GPU-based systems.
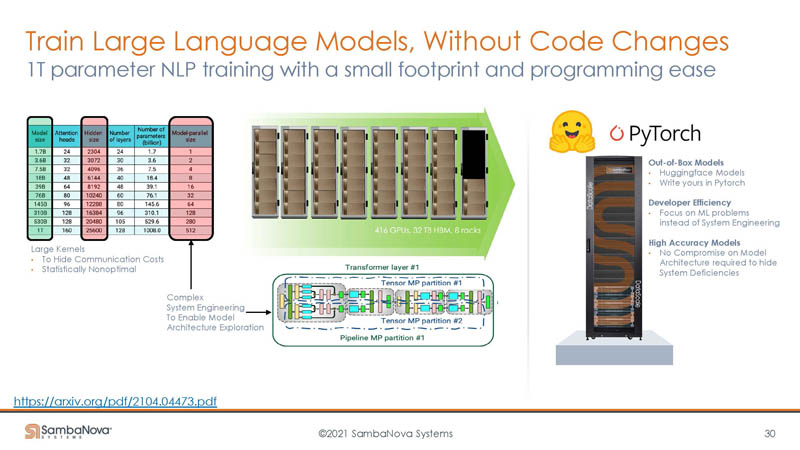
Other benefits are being able to train on full 4K and even 50K x 50K images without having to go through today’s generation of low-resolution downsamples.
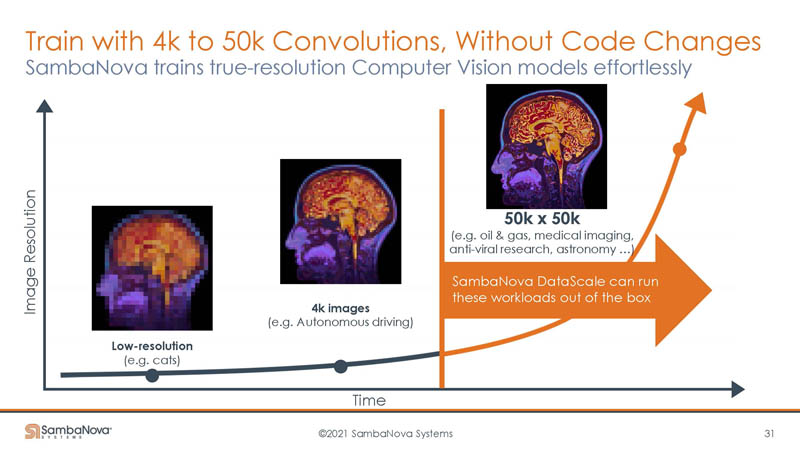
GPU-based systems may downsample a larger image (potentially on the CPU) to create tiles that fit in a GPU’s memory resources. With SambaNova, the additional memory means analytics happen with the full image without downsampling/ tiling.
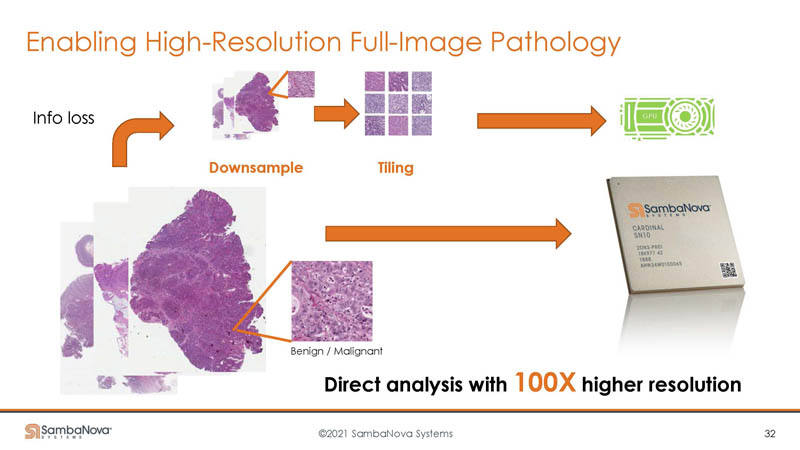
SambaNova says that is part of the reason it is able to also be accurate. As one can see, its inputs are higher resolution than on the GPU side.
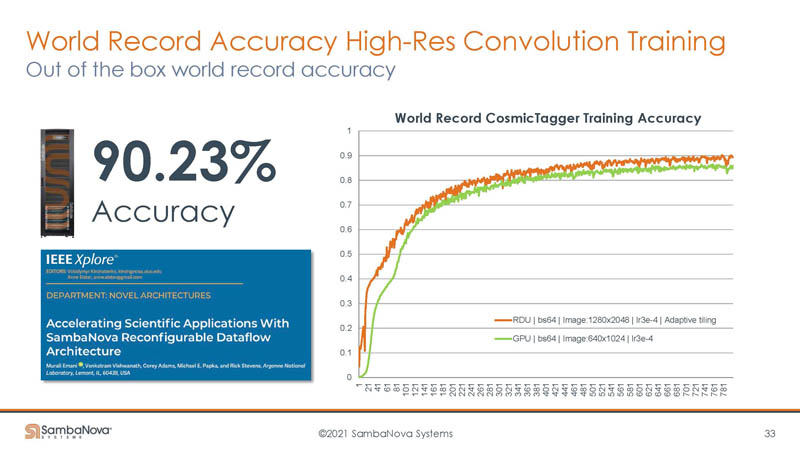
The company also says its RDUs can be used on other large problems beyond AI.

Summarizing it went back to the Goldilocks slide and said that its solution can handle not just current GPU-optimized models faster, but also those that sit outside of that Goldilocks zone.
This was certainly a lot to take in.
Final Words
SambaNova, along with Cerebras were given special mentions by Dimitri Kusnezov, Deputy Under Secretary for AI and Technology, Department of Energy during his Hot Chips 33 keynote just before this section. That seems to indicate that the DoE sees some promise in its partnership with the two companies. This was the first time that SambaNova really went into is architecture at this depth publicly from what we have seen, so it was great to see what the hype is about.



{kind=link}