
One reason we use Proxmox VE at STH is that it is a Debian based Linux distribution with ZFS, Ceph and GlusterFS support along with a KVM hypervisor and LXC support. When you have a smaller number of nodes (4-12) having the flexibility to run hyper converged infrastructure atop ZFS or Ceph makes the setup very attractive. This weekend we were setting up a 23 SSD Ceph pool across seven nodes in the datacenter and have this tip: do not use the default rpd pool. The reason for this comes down to placement groups.
The “Issue”
When Proxmox VE is setup via pveceph installation, it creates a Ceph pool called “rbd” by default. This rbd pool has size 3, 1 minimum and 64 placement groups (PG) available by default. 64 PGs is a good number to start with when you have 1-2 disks. However, when the cluster starts to expand to multiple nodes and multiple disks per node, the PG count should change accordingly. We started seeing a few errors in our Ceph log while using the default rbd pool that Proxmox creates:

Next, we is what we did to fix this HEALTH_WARN; too few PGs per OSD.
Here is a quick look at the cluster we were setting this up on:

There are four Xeon D nodes and three dual Intel Xeon E5 V3 nodes. There was still some wiring cleanup to do but the entire setup including switches, monitor/ admin nodes and a pfSense based firewall was running around 800w which is excellent in terms of power consumption.
A few words on Ceph terminology
Before we continue there are a few bits of Ceph terminology that we are using:
- Pool – A logical partition within Ceph for storing objects
- Object Storage Device (OSD) – a physical storage device or logical storage unit (e.g. an iSCSI LUN)
- Size – Number of replicas that will be present in the Ceph pool
- Placement Group (PG) – aggregate of objects within a pool and influences which OSDs an object should be stored on.
There are many more Ceph terms to learn, but these are applicable for this article.
Sizing where we want to be
The general equation if one is creating one large Ceph pool is (Target PGs per OSD * Number of OSDs ) / Size and then rounding to the nearest power of 2. You can read more about this using the Ceph PG Calc and a good read on the topic can also be found in the book Learning Ceph. In our default pool we had 23 OSDs, a Size of 3 and 64 PGs so we had PGs per OSD of 8.3. As one can see from the above log entry 8 < min 30. To hit this 30 min using a power of 2 we would need 256 PGs in the pool instead of the default 64. This is because (256 * 3) / 23 = 33.4.
Increasing the number of placement groups increases the need for memory and CPU to keep the cluster going. Since our Ceph disk / OSD per node is relatively low (1-6) we were a bit less worried about the overhead than we would be in a 90 disk node. We then checked the Ceph PG Calc to see what the recommended OSD number would be. With 13.5TB or so of formatted storage, and about 0.5TB of unique data, it is unlikely that we will need to expand soon. Furthermore, we have enough capacity so that we can lose a chassis with 6 disks without much of an issue. We therefore had a target PGs per OSD of 100. Here is the result of our primary pool in the calculator.
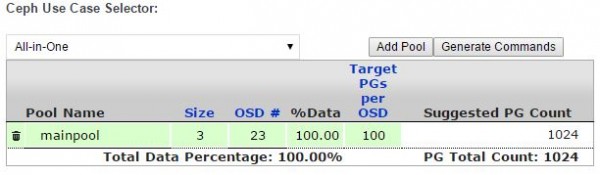
One can see a suggested PG count. It is very close to the cutoff where the suggested PG count would be 512. We decided to use 1024 PGs.
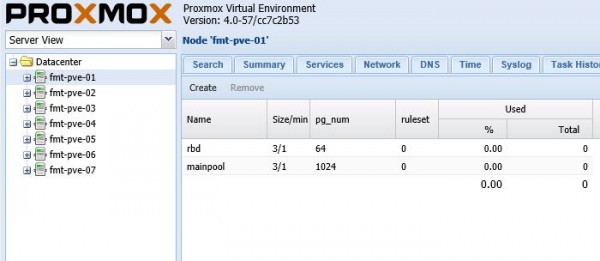
This had an almost immediate impact. We ended up with a Ceph cluster no longer throwing warnings for the number of PGs being too small.

We are still working with the cluster to figure out what is the optimal PG setting. It is worth noting that while Proxmox VE and Ceph will create a functioning pool automatically, it is likely best to save your logging SSD some writes and ensure you have a better number of PGs per pool. Since we are doing this in hyper-converged architecture, the idea of getting the system up and running with as few PGs as is sensible will help conserve RAM and CPU power for running VMs.



{kind=link}
Why didn’t you simply increase the number of PGs of the default pool? I’m not really sure what the point of this post was other than: Yes, you need to size the number of PGs to your cluster (Doh!).
Comments are closed.