
Last week we made a call for site readers to issue a simple hdparm read test. Intel actually suggested this particular test as a sanity check with new drives/ drivers in Linux. We have received over 100 submissions as of this week which is excellent! We are going to leave the form open for submissions for another week. In the meantime – here is a preview of some of the data collected. Please do keep submissions coming!
An interim glimpse into the data thus far
Of our over 100 submissions, we had over 35 forum members submit with their handles. We are not going to release the dataset with forum handles, but just to give one an idea of who is submitting results thus far (as a percentage of total submissions):
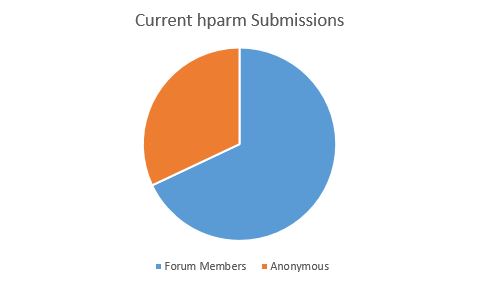
There are several folks running the command on multiple drives which is great to see.
We also saw some clear trends emerge in terms of manufacturers:
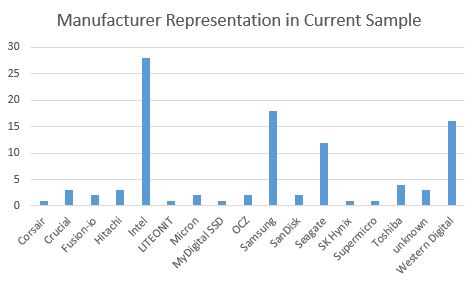
Intel and Samsung lead the pack mostly from SSD entries. Seagate and Western Digital from the hard drive side. Browsing Newegg or Amazon one may think that there are dozens of relevant contenders. After one rolls up Crucial/ Micron, SanDisk/ Fusion-io/ Western Digital and the like, the world of drive manufactures is quite small in the enterprise space. Or at least, in terms of the drives that get widely deployed.
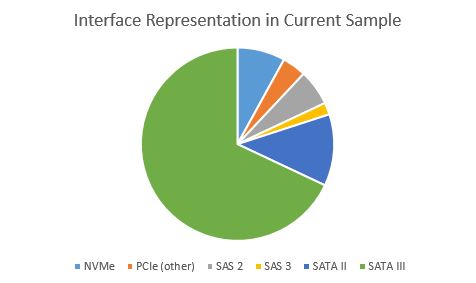
In terms of interfaces, there is little surprise that SATA III is the most popular in our dataset. It is inexpensive and enabled on virtually any system.
While this 90 second benchmark exercise is far from precise, we can see some clear trends emerging when we look at the SSD data. The NVMe drives are ~4x the speed of non-NVMe drives in the small sample.
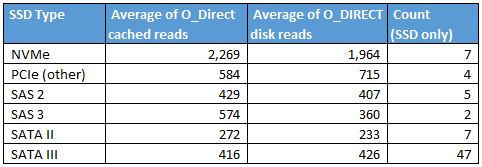
As we drill down into SATA III SSD performance, we can see a few trends emerge.
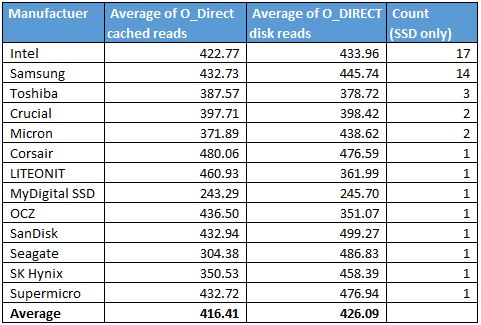
There is good reason the SanDisk count is not greater. We will see that in The Impact a case where we found an issue with two SanDisk CloudSpeed Ascend drives.
The Impact
Generally I assume SATA III drives “just work” when installing them into a server. Especially if they are seen as block devices by the OS. While testing a few drives I had on hand, I did find two SanDisk CloudSpeed Ascend drives performing well below expectations:
$ sudo hdparm -tT --direct /dev/sdi
/dev/sdi:
Timing O_DIRECT cached reads: 262 MB in 2.01 seconds = 130.58 MB/sec
Timing O_DIRECT disk reads: 536 MB in 3.00 seconds = 178.65 MB/sec
$ sudo hdparm -tT --direct /dev/sdh
/dev/sdh:
Timing O_DIRECT cached reads: 244 MB in 2.01 seconds = 121.41 MB/sec
Timing O_DIRECT disk reads: 236 MB in 3.01 seconds = 78.31 MB/sec
lvadmin@asusrs500:/dev/disk/by-id$ sudo hdparm -tT --direct /dev/sdb
Compare this to the Intel DC S3610 800GB installed in the same chassis:
/dev/sdg:
Timing O_DIRECT cached reads: 944 MB in 2.00 seconds = 471.22 MB/sec
Timing O_DIRECT disk reads: 1458 MB in 3.00 seconds = 485.51 MB/sec
One can see those two SanDisk drives are performing well below what we would expect of a modern SATA III SSD. (And yes we triple checked that these were not spindle disks.)
How you can run the sanity check hdparm read test
hdparm is an almost ubiquitous utility for researching connected hard drives. The Intel NVMe driver (Linux) guide has a quick command to run to test both cached and non-cached disk reads. While this is by no means an extremely accurate benchmark, it does provide a bit of a sanity check.
How to run the sub- 1 minute read benchmark
- Figure out what your drive is called in /dev/ e.g. /dev/sda or /dev/nvme0n1
- Run this command (replace sdb with your device):
sudo hdparm -tT --direct /dev/sdc
Here is what it looks like testing three different drives in about 90 seconds using Ubuntu 15.04 server:
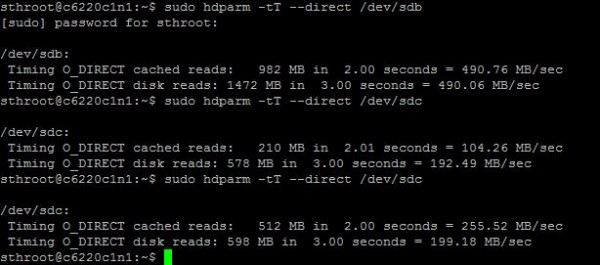
That is all there is to it. Once you run the quick benchmark please add your results to: This Office365 form we will get an aggregated set online next week.



{kind=link}
Following the link gives:
We’re sorry. We can’t open this survey.
Please contact the person who sent you this survey.
Should be fixed. If you want to post results in the forum, I can add manually.
Hi Patrick,
Should we note anywhere on the form if we’re using a SATA-2 controller with our SATA-3 drive? I have an older laptop with a newer SSD, and I didn’t want to confuse the results.
Try putting it in the model as a note.
Comments are closed.