
At Hot Chips 29 (2017) Qualcomm Centriq 2400 was a hot topic. For those who have not been following since Q4 2016, Qualcomm is making its way into the mainstream server business with an ARMv8 64-bit CPU. We saw a live demo of the CPU and saw hardware in-person from Microsoft at the OCP Summit 2017. At Hot Chips 29 we received a fairly in-depth architectural overview without performance or power information.
Qualcomm Centriq 2400 Overview at Hot Chips 29
Here is the high-level SoC overview. Key aspects are that it has up to 48 cores, 6 channels of DDR4 (up to 2 DIMMs per channel), 32x PCIe Gen 3 lanes, and a bidirectional ring bus. Qualcomm did not disclose L3 cache sizes, clock speeds, power consumption and so forth. on the other hand, Qualcomm gave a fairly deep architecture overview given not disclosing those critical facts.
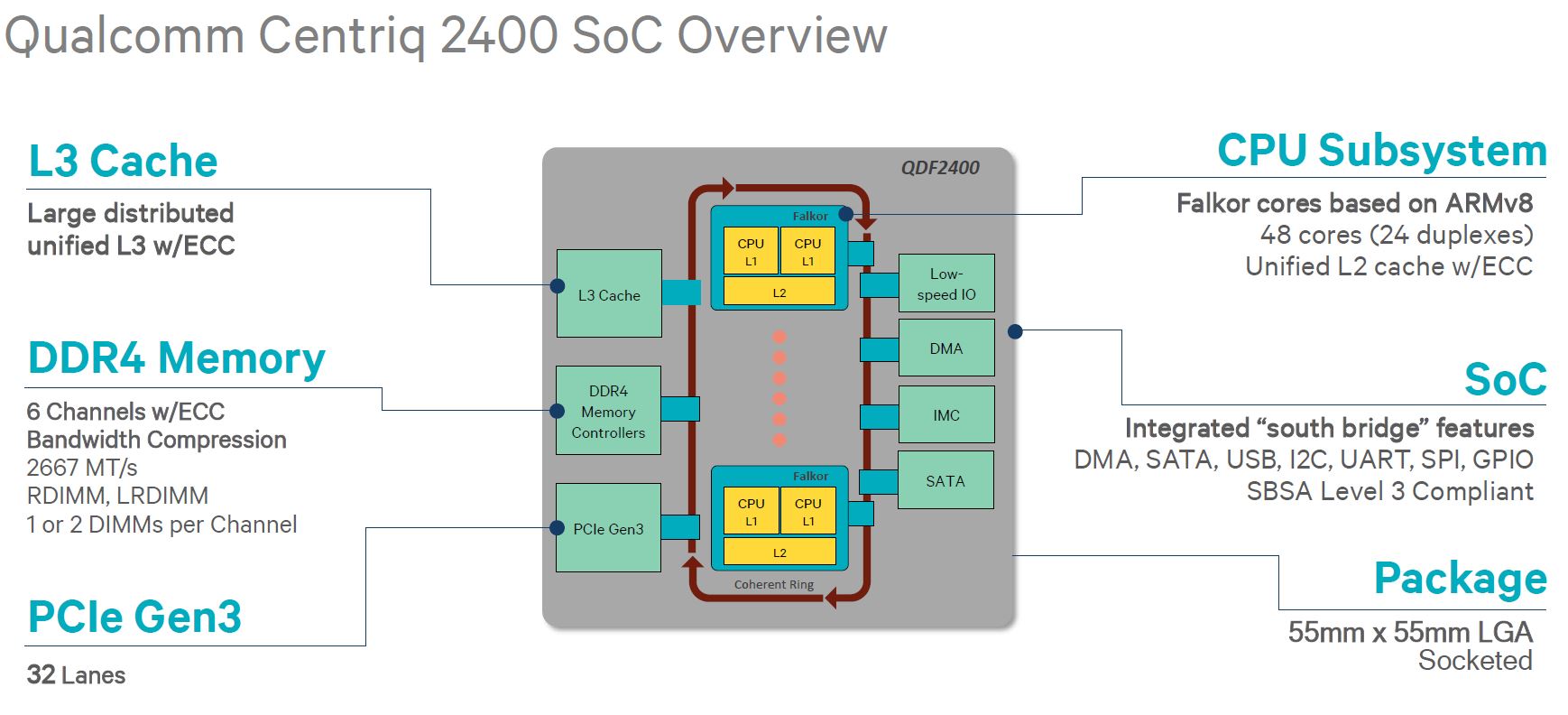
L3 QoS is software to monitor the use of L3 cache and determines how the L3 can be optimally partitioned.
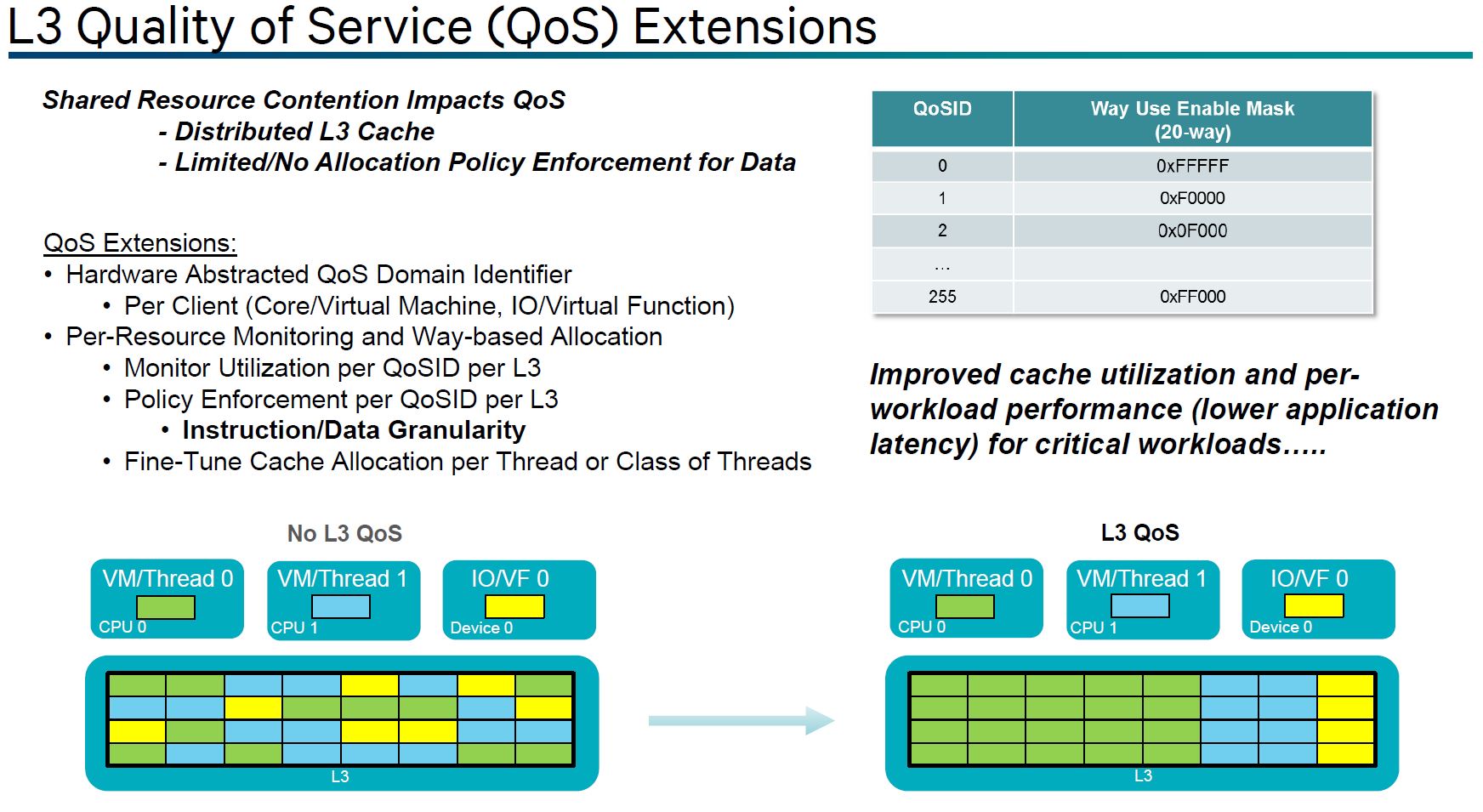
One of the more intriguing features is memory bandwidth compression. The Qualcomm Centriq 2400 memory controller can access writes/ reads that are going to/ from memory and determine if a line can be compressed.
The last point is around Secure Boot. In this latest generation of processors, this type of feature is table stakes. Each implementation will have some differences that a customer may prefer, but it is an item that Centriq needs.

The next section will be a deeper dive into Qualcomm Centriq 2400 architecture. We know that many of our readers care about performance, cores, RAM and sockets so we wanted to get those details up front. After the architecture section is what we saw of the hardware at OCP 2017, the competitive landscape, and our closing thoughts.
Deeper Dive into Qualcomm Centriq 2400 Architecture
At Hot Chips 29, Qualcomm gave an unexpectedly deep dive into the architecture. We had pre-read the slides twice before the talk, listened to the talk, and reread the slides after. The slides cover the vast majority of the details and we know many of our readers care more about TCO and total system performance. Therefore, we are going to present the slides with only a bit of commentary.

There are a few big ones on this slide. First, this is a design meant to deliver high IPC performance. We have seen some ARM server designs that focused on I/O and power but decided not to compete in single thread performance. Qualcomm stressed that it is a high performance per thread design (without revealing performance numbers.)
Another key aspect here is that the AArch64 only support. Qualcomm eschews legacy 32-bit execution in order to extract better efficiency. On the x86 side, there is a huge demand to run legacy 32-bit code so that trade-off is not possible. Using ARM most users will need to either start with new development projects or port existing x86 data center code anyway. Putting a stake in the ground and saying it is 2017, use 64-bit in your go-forward data center efforts makes sense in the high-performance segment.
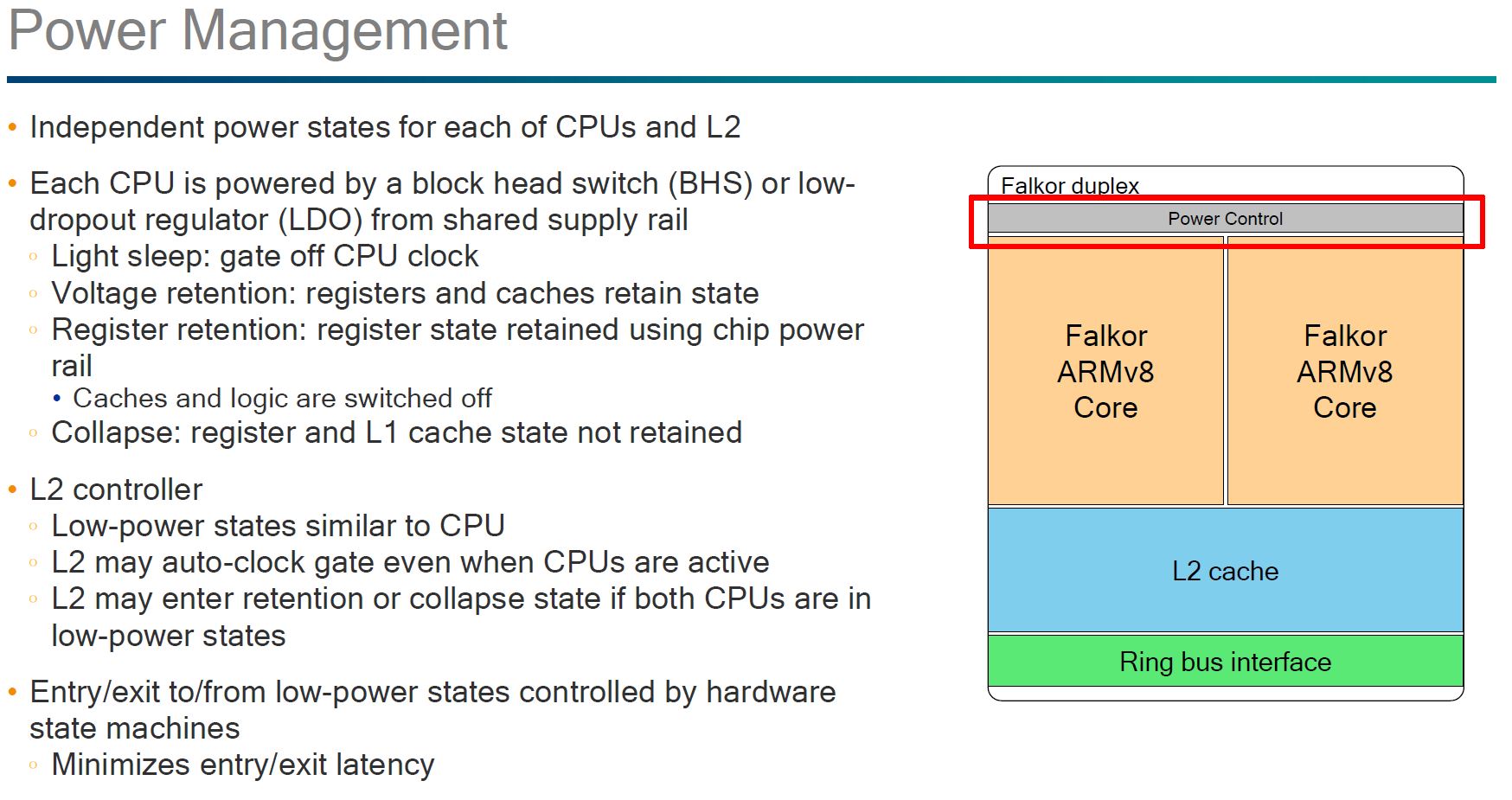
Qualcomm focused a good portion of the discussion around power management. Down to where we heard how different choices in cache and topology impact power consumption. Coming from a power rationing mobile background, one would expect Qualcomm to bring the knowledge and perspectives from low power design into their server chips. Qualcomm claims that this is going to be the first 10nm server CPU and that it has the experience to extract maximum benefit out of that process.
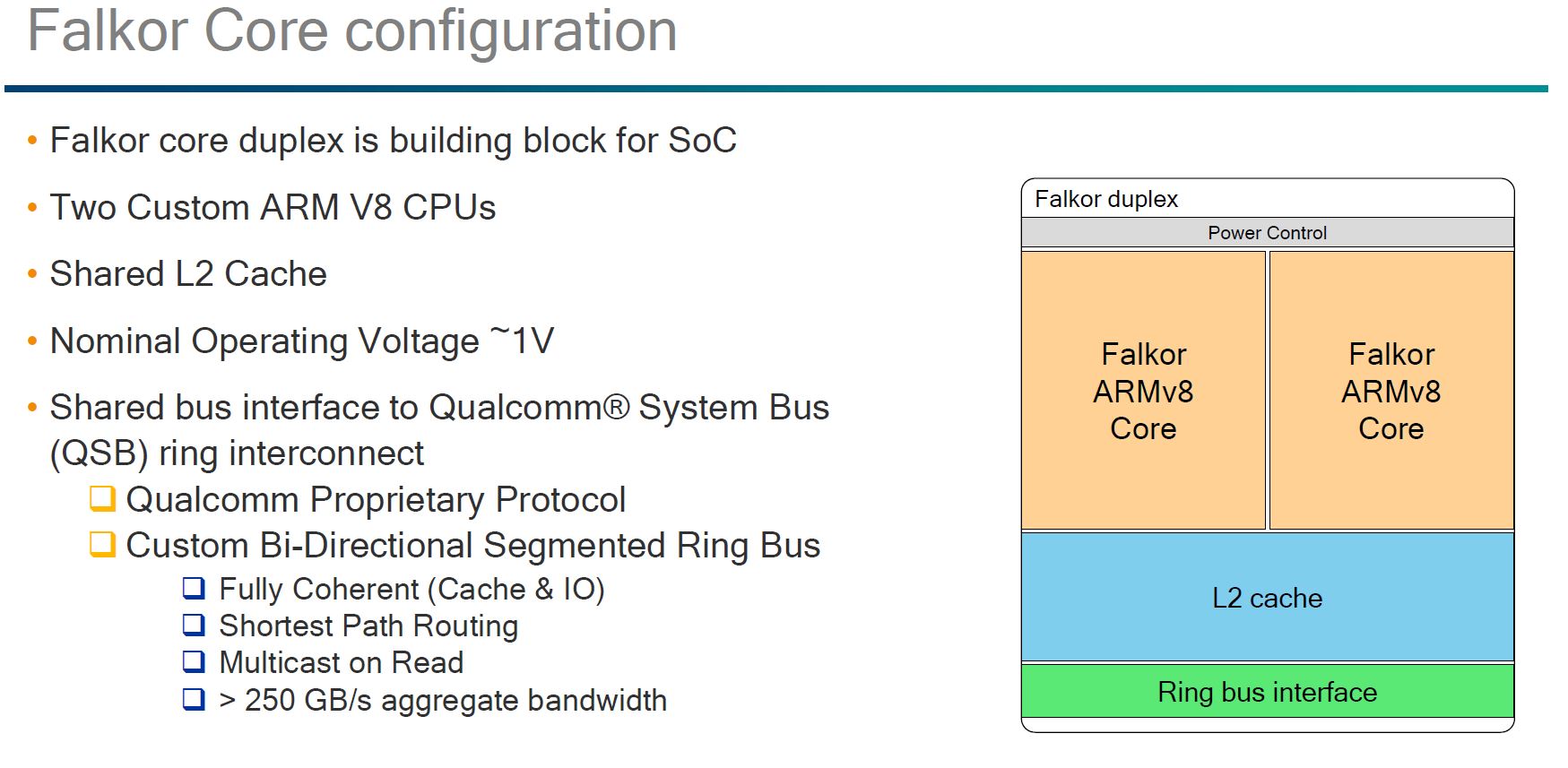
The Falkor Duplex has two Falkor ARMv8 cores a shared L2 cache and a bidirectional ring bus architecture.
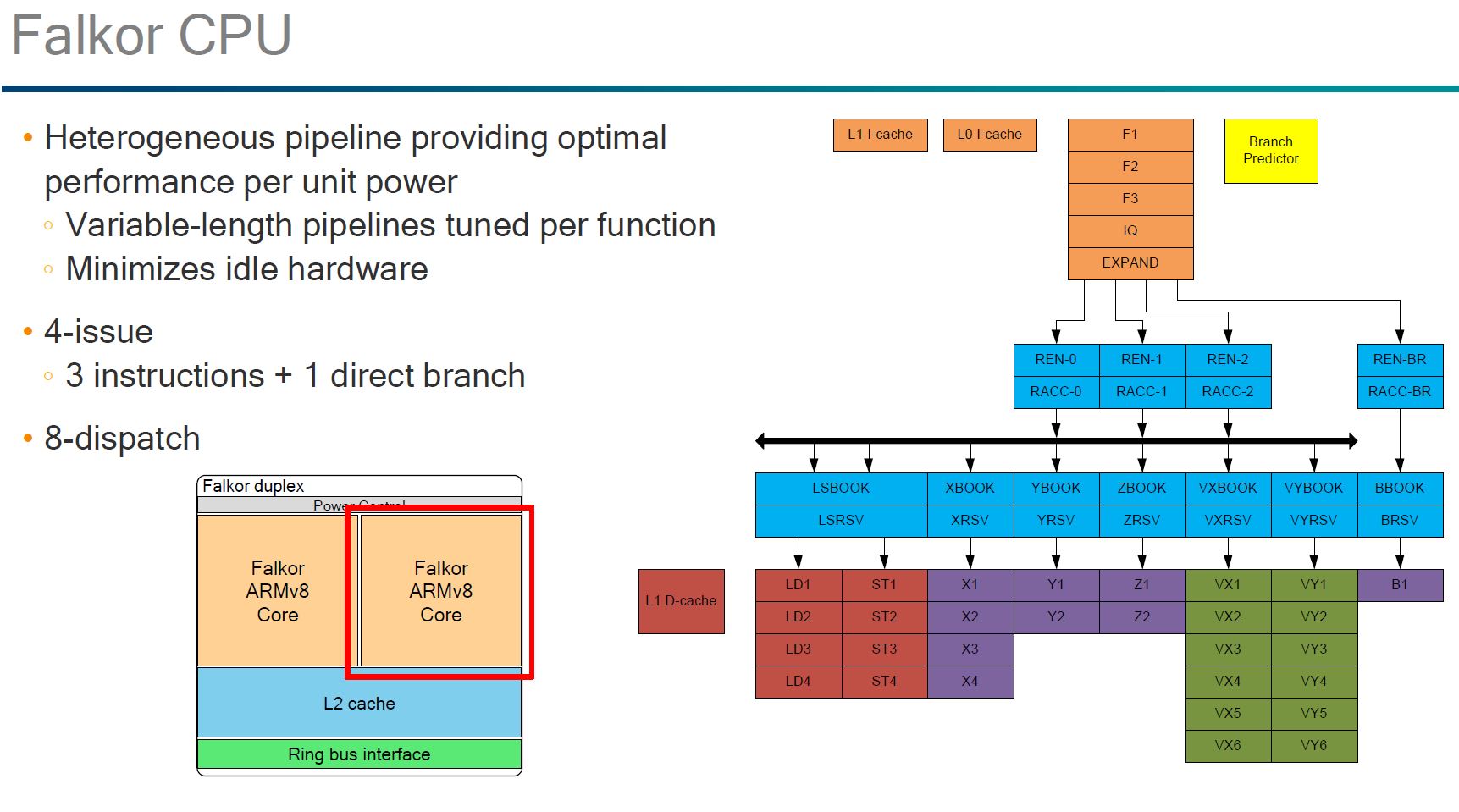
The Qualcomm Falkor pipeline overview was a bit shocking in that we were not expecting this level of detail. One of the more interesting aspects of the pipeline architecture is that it is fully heterogeneous. If you trace through the pipeline diagram, no two paths are exactly alike.
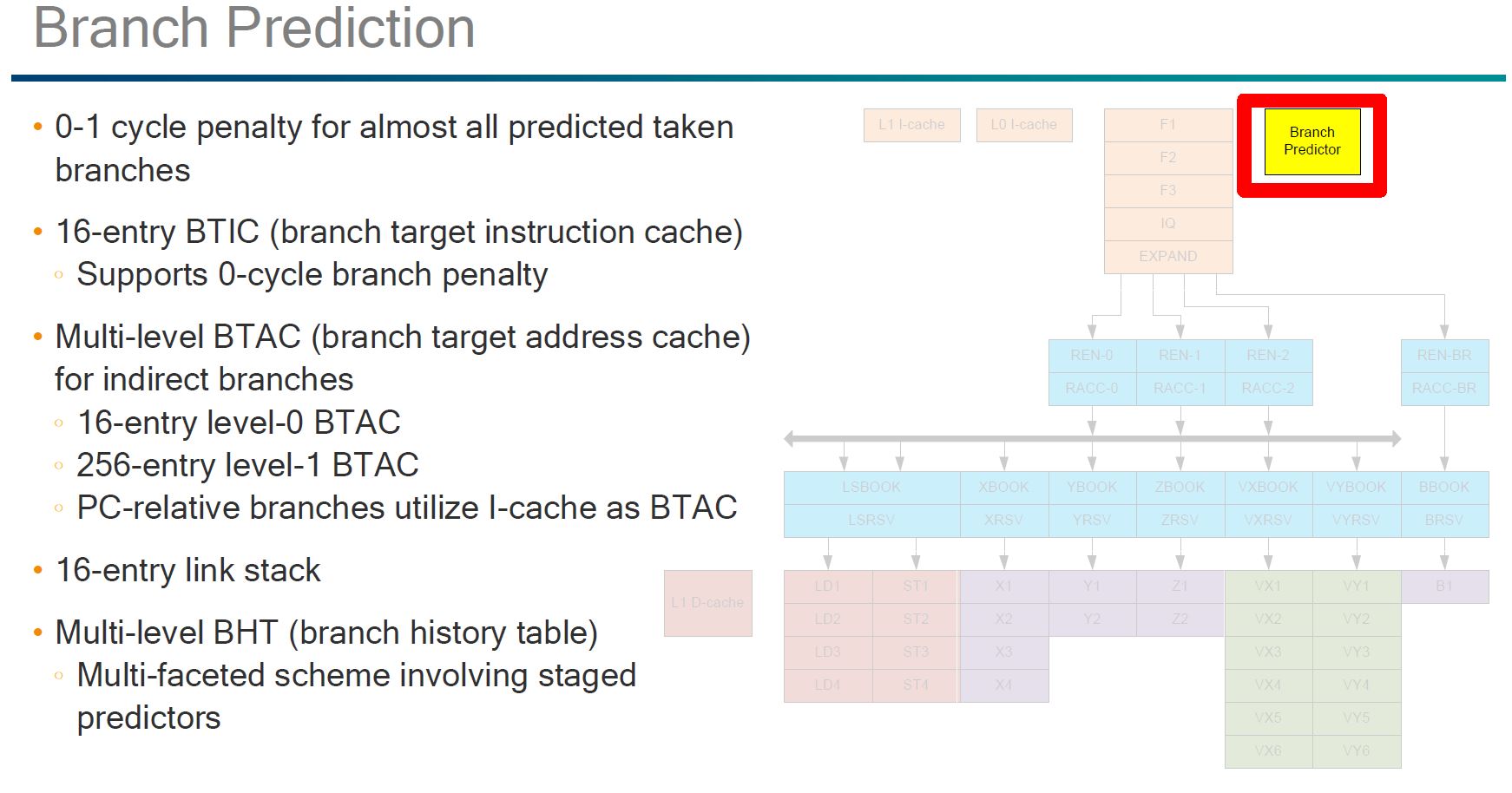
As you would expect, Qualcomm has what it claims is a strong branch predictor. We were pleasantly surprised that Qualcomm did not label this an “AI” feature like some other manufacturers.
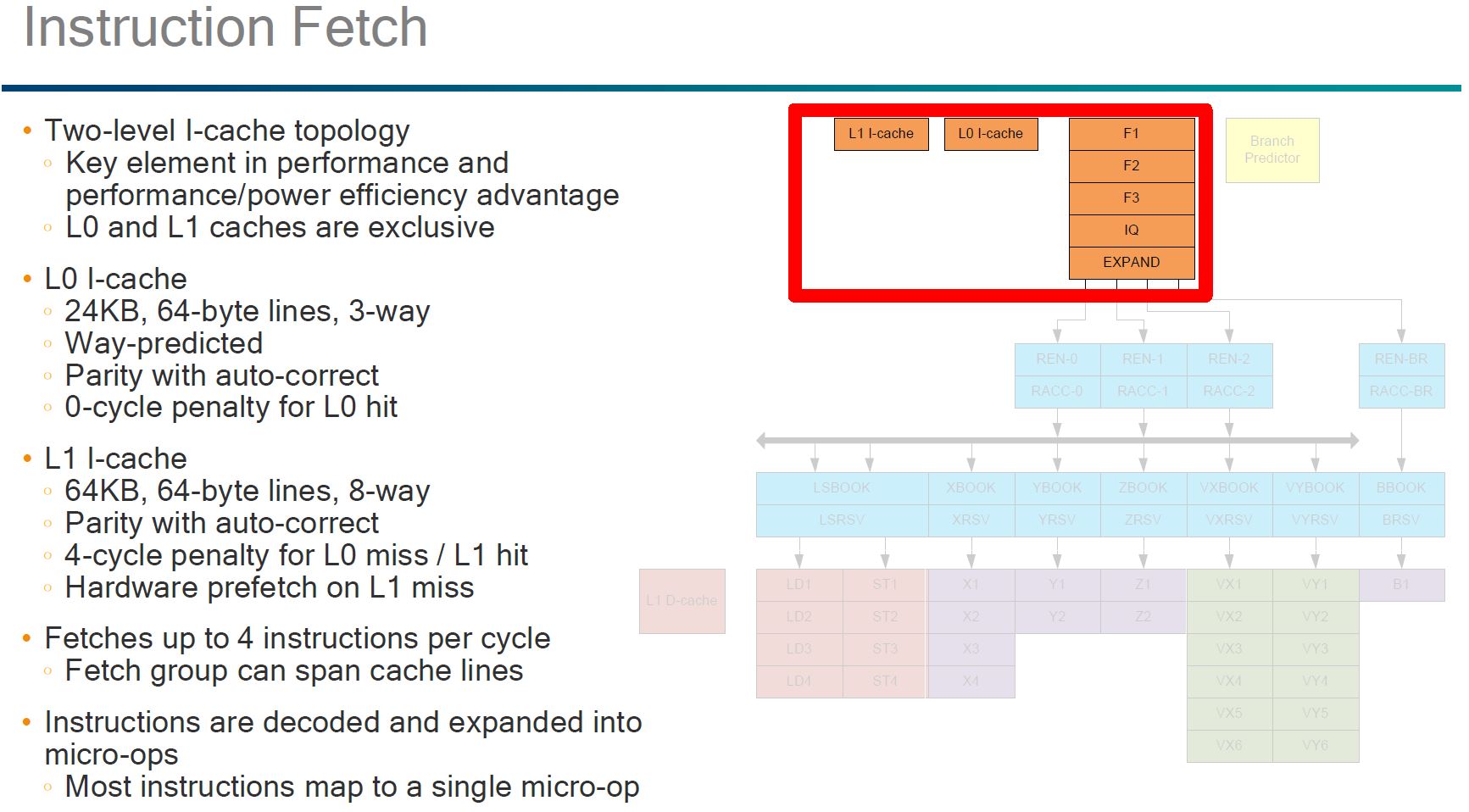
The more intriguing pieces of the Flakor cache is the fact that there is a exclusive L0 and L1 I-cache. We were told this is a trick to further reduce power consumption.
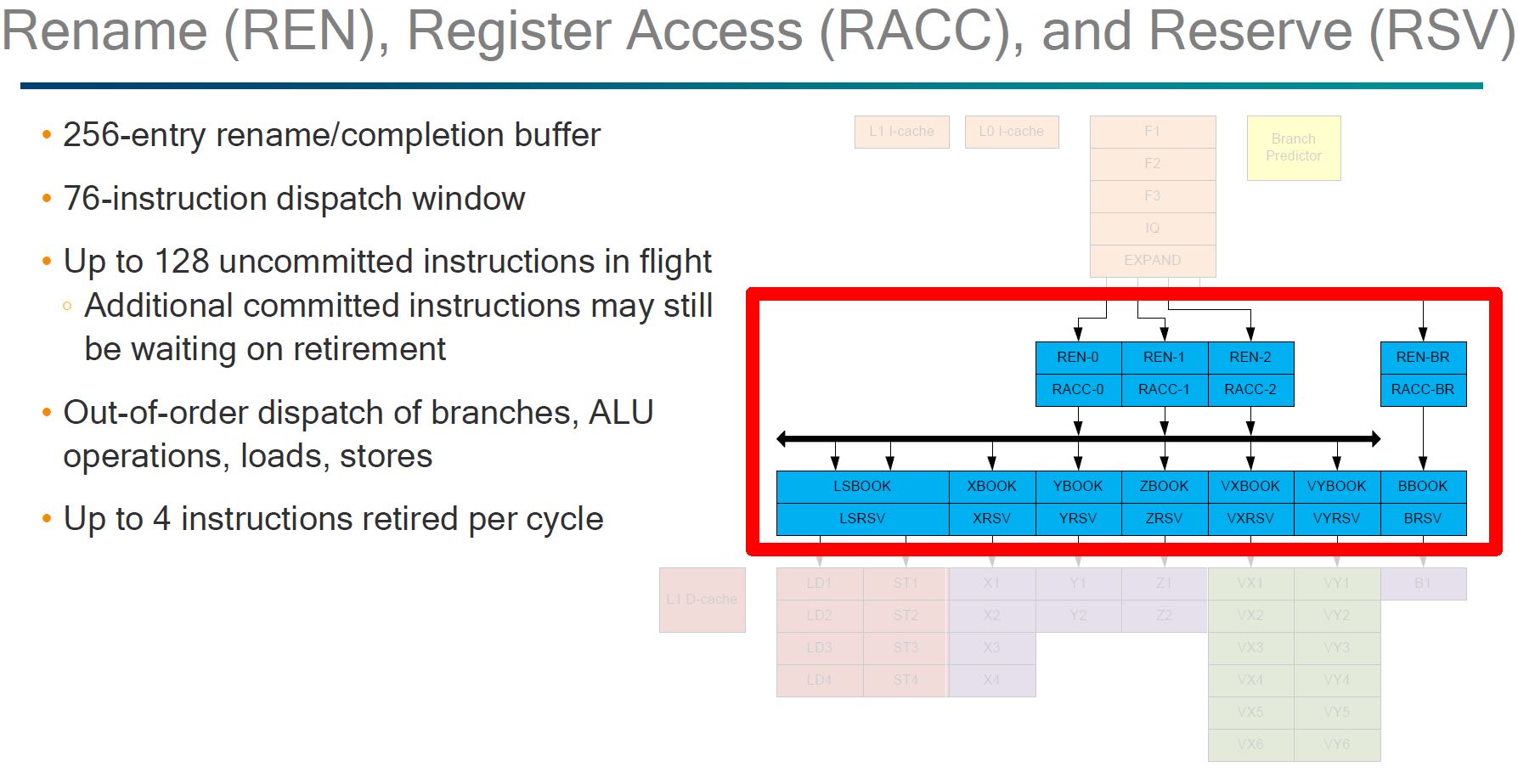
Here, the part that we wanted to see was the out of order execution. Some architectures, e.g. the Cavium ThunderX (1) have been in-order designs.
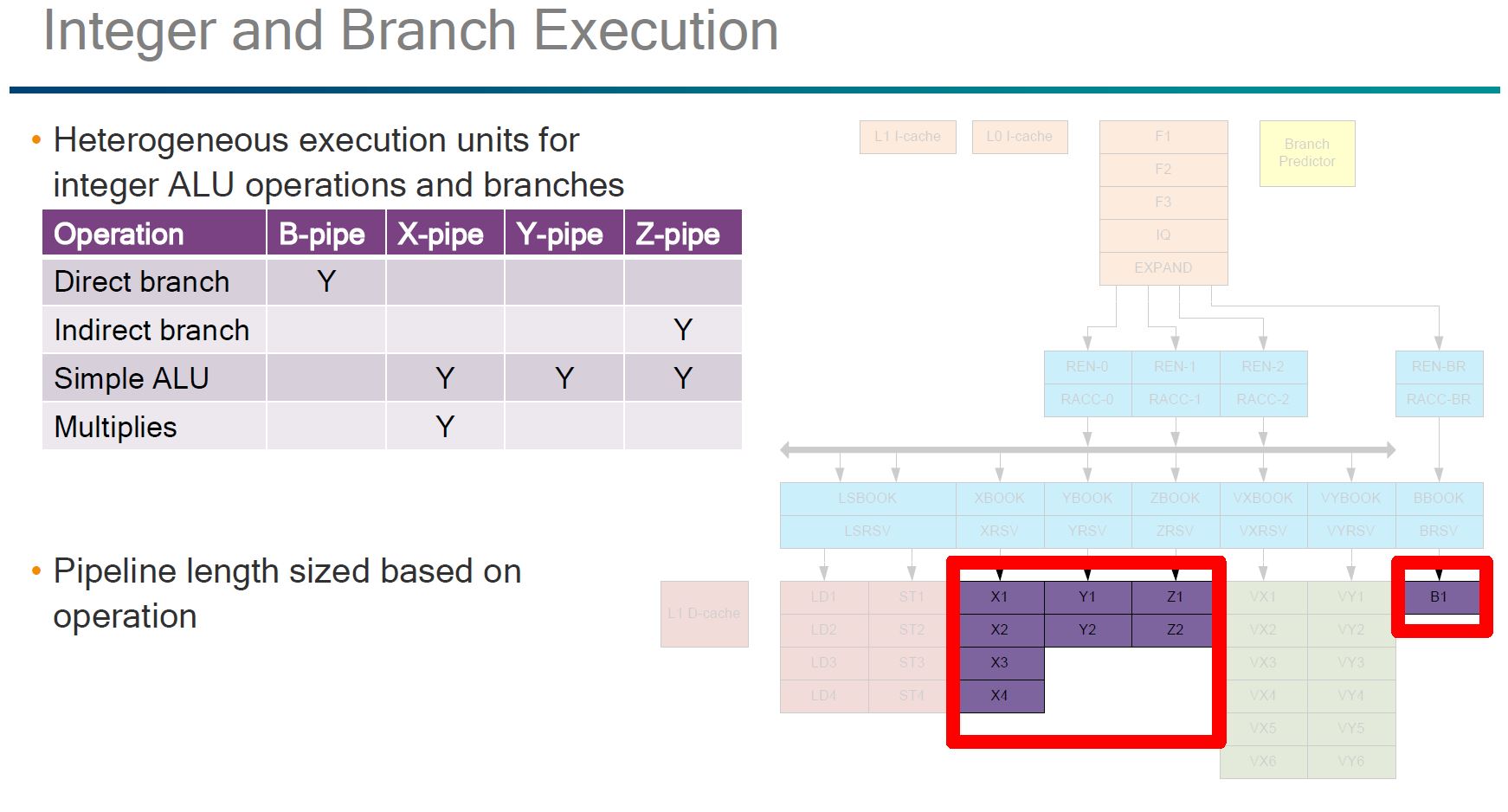
On the integer and branch execution, one can clearly see the heterogeneous execution pipeline.
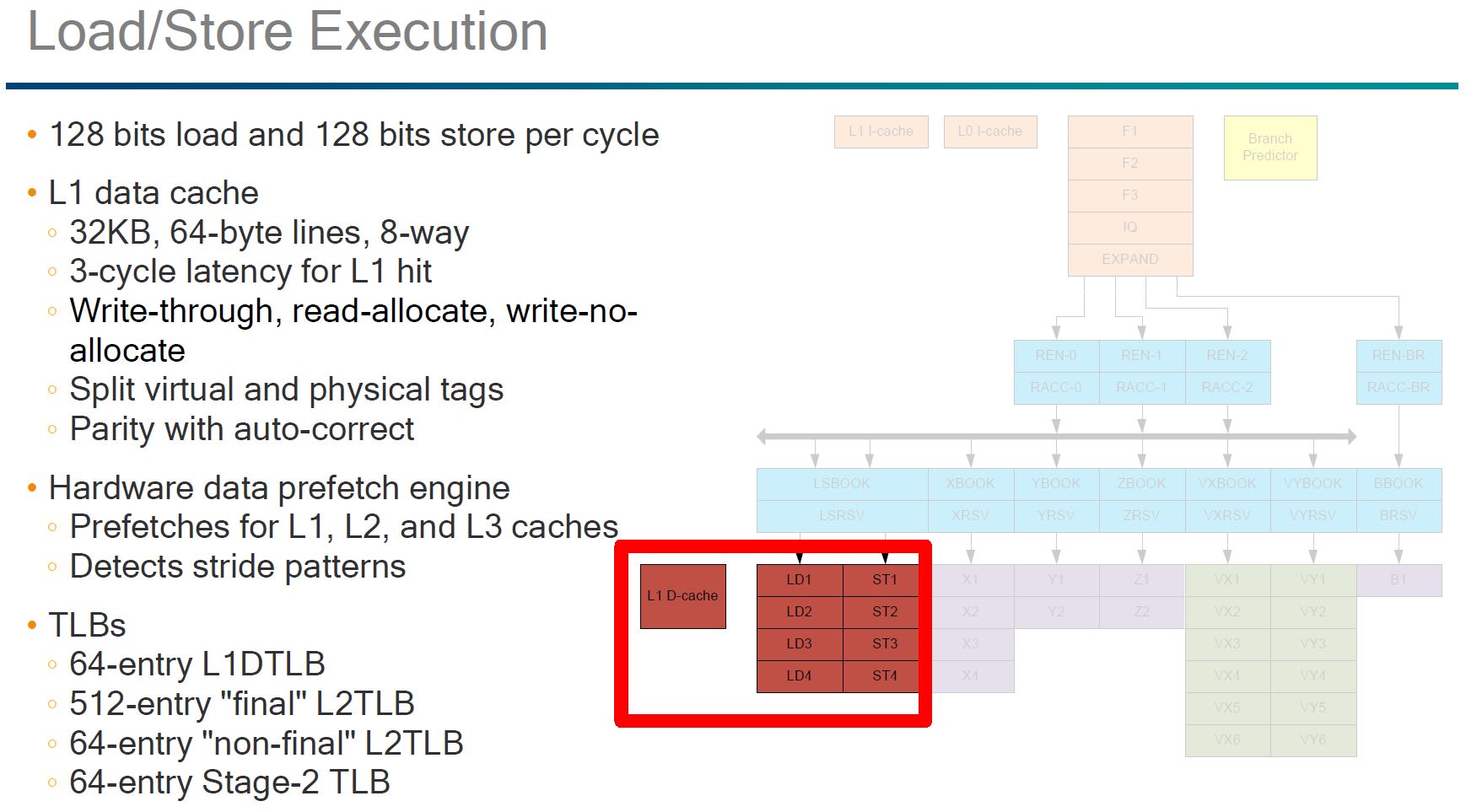
We double checked the presentation we received and the green segment VX/ VY was not covered.
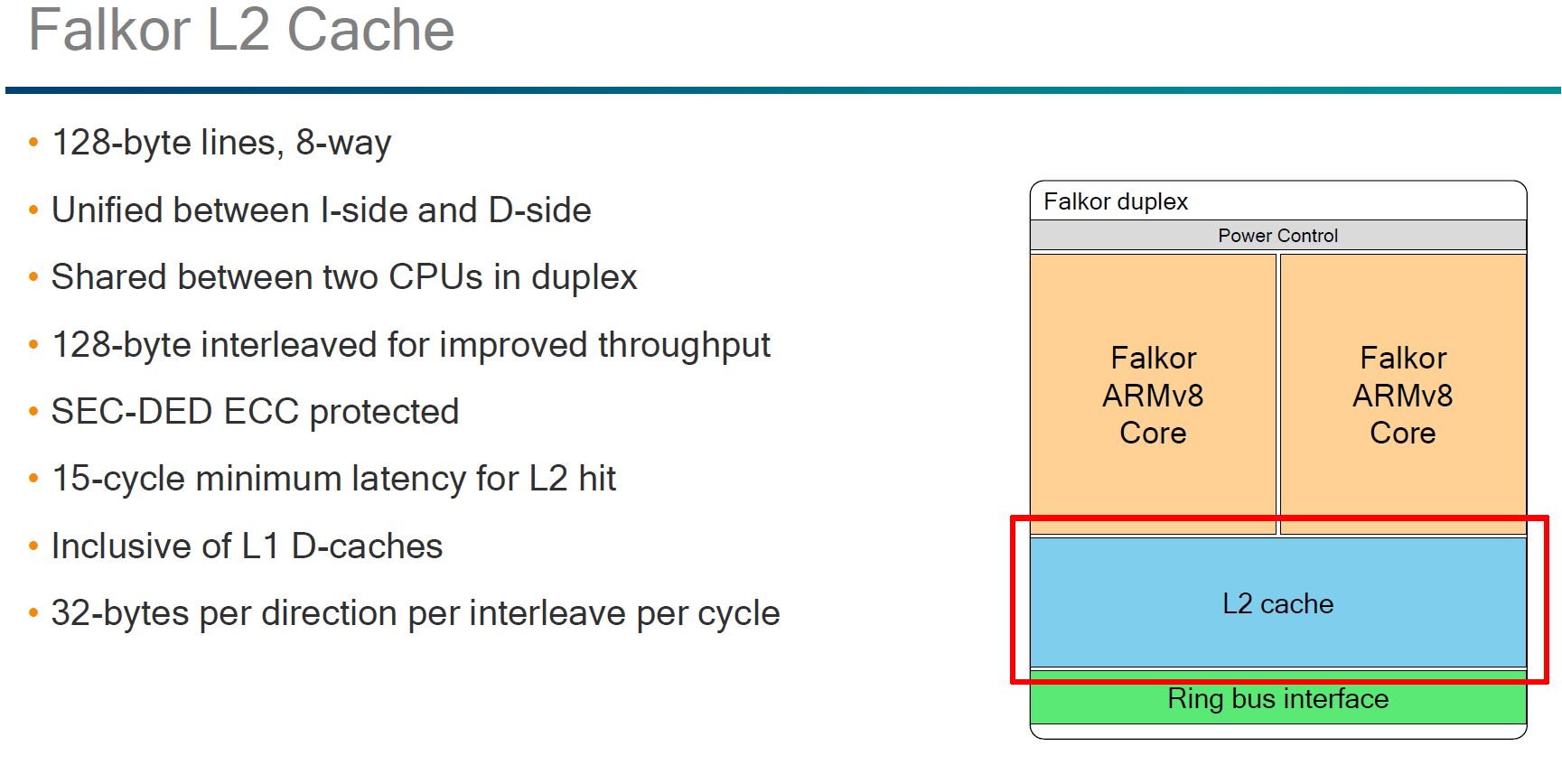
Here you can see that the L2 cache is shared between two Falkor cores. A slide earlier discussed the distributed L3 cache and Qualcomm’s advancements in that area.
Overall, for an initial entry in the market we are excited. Although we are still well before general availability, we did get to see the chips in person and in action a few months ago at OCP.
Qualcomm Centriq 2400 from OCP
The last time we saw Qualcomm Centriq 2400 was at OCP Summit 2017. We were able to see one of the Microsoft OCP sleds in-person. Here it is:
During the OCP Summit, Microsoft showed off an internal only Windows Server version running on ARMv8:
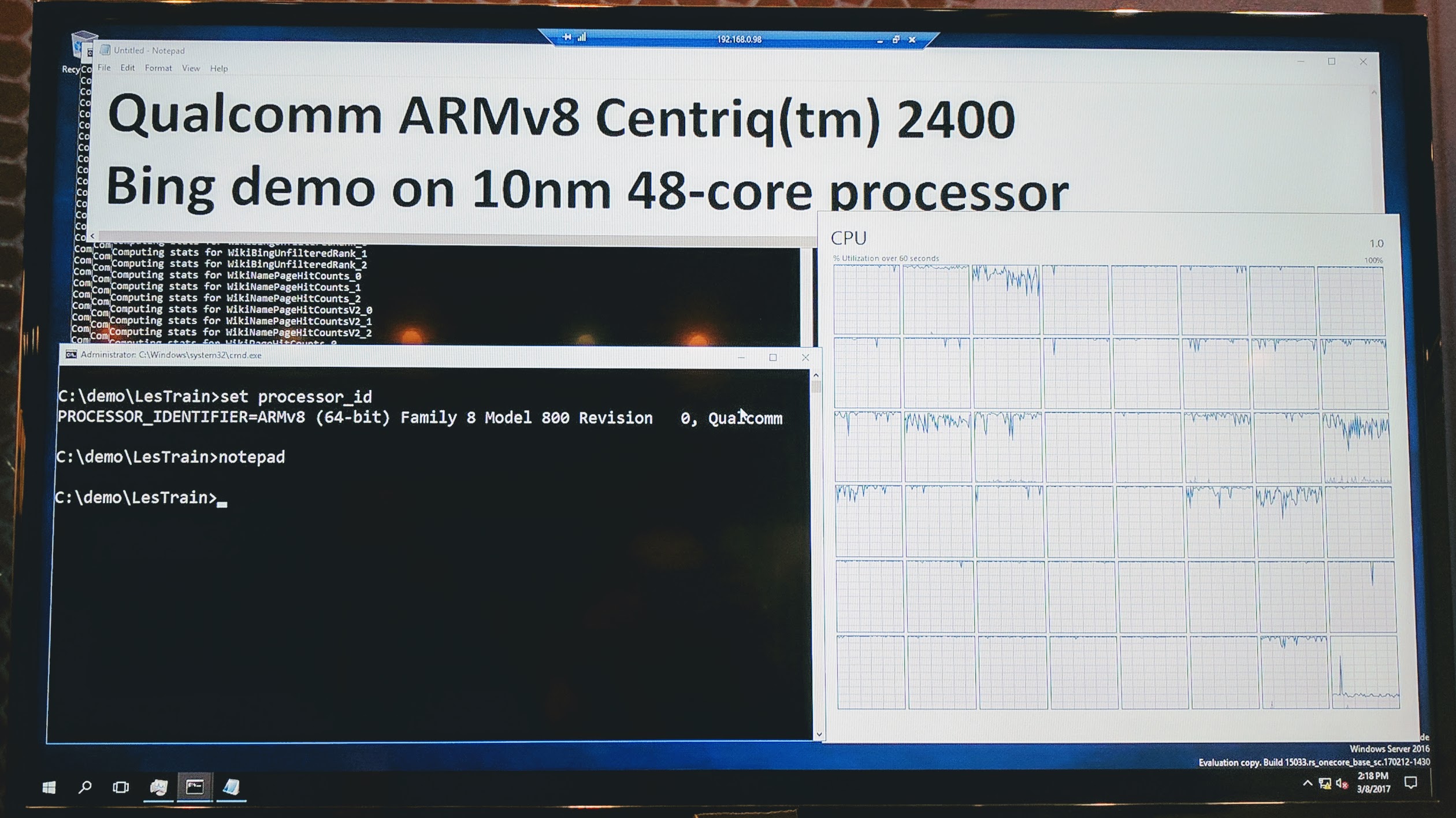
You can check out that piece for more information.
Competitive Landscape
Qualcomm has the advantage of having far reaching relationships with various vendors. Also, the fact that we saw a major customer running hardware earlier this year is a good sign. At the same time, Centriq 2400 will be competing in the mainstream market with products like the AMD EPYC 7000 series, Intel Xeon Scalable Processor Family, and the Cavium ThunderX2 (now Broadcom Vulcan based.)
All three of its competitors run in either dual socket or single socket modes. Offerings from AMD and Intel are x86 compatible and will run years of software out-of-the-box without emulation. As we noted with the original ThunderX (1) switching to 64-bit ARM is not a pain-free experience.
Whereas we evaluated ThunderX in a world where the only other viable option was Intel, times have changed. First, the ARM infrastructure on the server side is light years better than what it was in Q1/ Q2 2016. Second, AMD has a viable x86 alternative allowing companies who want an alternative supplier to source without major software changes. Cavium itself has had a major change. By bringing in the Broadcom Vulcan program Cavium has gone from a lower performance ARMv8 core with lots of networking in 2016 to a high performance (read HPC focused) ARM design in 2017. AMD, Cavium, and Intel are also shipping their next-gen platforms several months before Qualcomm.
Qualcomm has two more legitimate competitors in the market aside from Intel, even before getting to lower visibility players such as APM X-Gene 3. We do think that Qualcomm’s brand recognition, partner ecosystem, executive team and ability to execute in the ARM ecosystem will help it find success in the data center.
Final Words
Qualcomm Centriq 2400 is going to make waves. Key to gaining market adoption is going to be getting the product out quickly. It is also going to have to find specific niches that it can play in. Hearing from customers of ThunderX (1) and AMD EPYC shows that there is a pent up ABI (Anything But Intel) market demand. While large customers and appliance manufacturers will support ARM in addition to x86, many enterprise vendors will restrict purchasing based on “what can I live migrate VMware VMs to/ from.”
The bottom line here is that the Qualcomm Centriq 2400 looks promising. The fact that large hyper-scale customers like Microsoft are publicly showing it off is a great sign. Now all that is left is launching this generation and getting a clear roadmap out with future generations so customers can plan purchases accordingly. We cannot wait to see more from Qualcomm.


{kind=link}
At least you’re honest intellectually on the market for these. Can STH test if they work as Ceph nodes? We’ll be deploying a ~400 node cluster in late Q1 2018 that we’re planning for now.
We’ll also need to know what networking is available on them and what OS and nic support is available for RDMA transfers.
What’s the roadmap? Is Microsoft the only server supplier? I don’t want to introduce a first gen platform that there’s no good roadmap for. STH needs to publish this information too.
I thought it was shipping already, but only to select clients. One very nice thing for Qualcomm is that they are already on 10nm which should be on par with Intel’s 14nm+. Maybe they will beat Intel to 7nm now that Intel has lost its process manufacturing lead to the foundries.
I just hope that Qualcomm could follow the business model of AMD and Intel and try to make their processors and supporting boards available to the mainstream market so that they could be purchased by mere mortals like me. If Qualcomm wants to see their platform well supported by free software projects, they need to make sure all the smaller shops and developers from every corner of the world can get their hands on this kind of hardware. Unfortunately, Qualcomm has no experience in distributing their products like AMD and Intel do.
@Hosting Ace + @Marcelo B – Running ‘MS Windows’ on ARM will probably go the way of “Windows RT”; if they plan on making the same mistakes (IE: is it the whole shebang or a stripped down Windows Server version).
Most of the Linuxes (and Android, which does have Server Software) run great on ARM.
With Windows the Source Code needs to be available or there needs to be an ARM executable, otherwise you can forget running that Program (unless it’s both critical and can be ran slowly, then it can be emulated).
For Linux (I can speak from experience with Debian) it’s virtually painless. Five steps: Download the Linux ARM Kernel, install a Toolchain, download new Compiler, recompile new Compiler Toolchain and Kernel, reboot. Everything just works.
Hoping ‘Windows Software’ will work out is hopeful indeed, but if you’re only going to run one Program, a Database or Server, then success is hugely improved – but you could do that under Linux or with a more powerful CPU.
This (a Server with an ARM CPU) is perfect for saving electricity or to serve critical Webpage or DB Queries that are seldom requested.
If you have a Budget for electricity and can pay 2-3x for the Server you’ll rapidly be rewarded with a fast CPU (x86) that runs millions of different Programs (fast) and save time tweaking and fiddling just to run slowly and efficiently.
For a Cellphone or the Mars Rover it makes a lot of sense.
If it was a good idea for more earthly endeavours then Facebook and Google wouldn’t be buying up all the supplies of Volta and POWER9.
BUT, that said I do hope ARM and MIPS Server do well and find their future. Problem is that x86 is so entrenched and even Fujitsu Sparc Servers can be had for under $2K (bare bones) and outperform x86 – needless to say Sparc runs Scale Up and Out Databases and Servers quite well.
@Rob what you say describes the ARM processors of yesterday. The Centriq and Thunder X2 are designed to be high performance processors, so no longer the typical very low power but slow single threaded perf ARM core.
@Marcelo B – That post was for two people.
I’ll just touch on one point you made throughout, maybe it was your only point.
“I thought it was shipping already, but only to select clients. … I just hope that Qualcomm could follow the business model of AMD and Intel and try to make their processors and supporting boards available to the mainstream market so that they could be purchased by mere mortals like me.”.
Then in your reply, after the “thanks” part you said: “@Rob what you say describes the ARM processors of yesterday …”.
Ya.
Wait, then look here: https://developer.qualcomm.com/hardware/additional-snapdragon .
Since the Centriq 2400 ARM chip has independent power states for each of the two CPU’s would be neat to see the “South Bridge” SoC PCH (peripheral controller hub) and memory controller be made into asynchronous, multiplexed controllers for simultaneous dual root capability. Then use the dual CPU chip in a dual root device creating two compartmentalized OS platforms operating in isolated memory space and drive partitions with one (OS1) specialized for common tasks such as productive software and another (OS2) to interface with perhaps a PLC or Vx like RT environment or interface.
SUSE Linux Enterprise Server 12 Service Pack 3 will fully support the Qualcomm Centriq 2400.
SLES 12 SP3 will be available September 7.
SLES 12 SP3 is the second SUSE Linux release providing commercial support for ARM including systems from Qualcomm, Cavium, HiSilicon, and others.
We also have a a Ceph based SUSE Enterprise Storage that has supported ARM since early in 2017.
Rob, where you can find Fujitsu SPARC server which is available for $2k? I can imaging $20k is their kind of starting price…Thanks!
Comments are closed.