Power Consumption Tests
For our power testing, we used AIDA64 to stress the NVIDIA RTX 6000 Ada, then HWiNFO to monitor power use and temperatures.
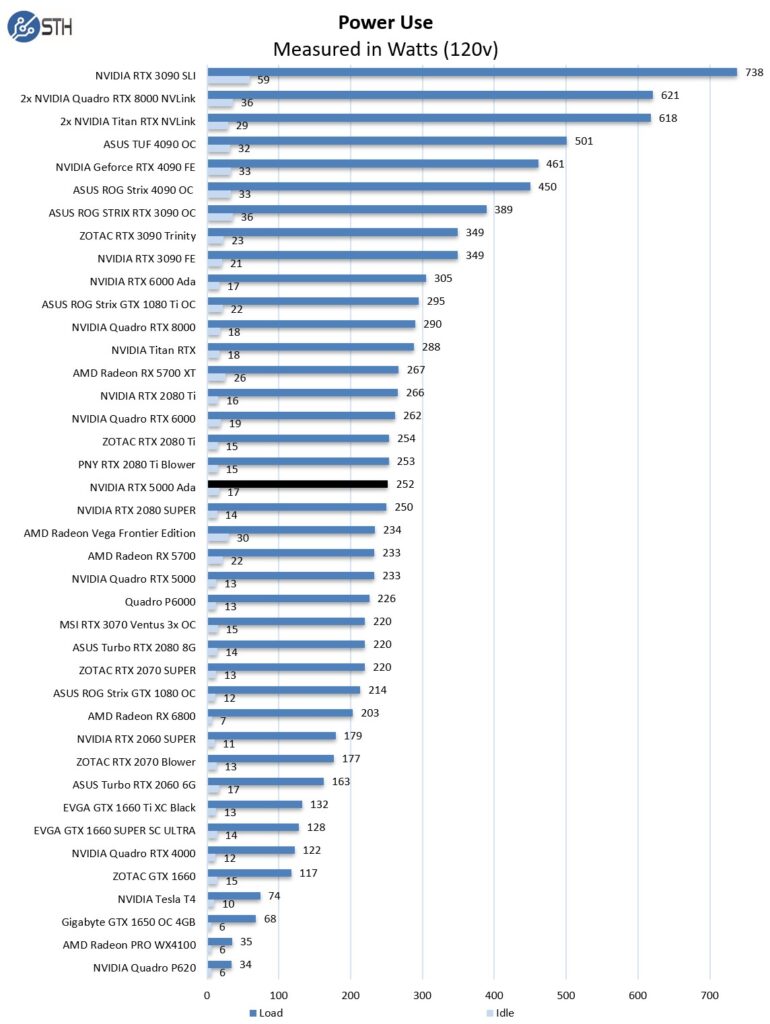
We use the AIDA64 Stress test for our tests, which allows us to stress all aspects of the system. We selected just the GPU for this test and let it run for about 15 minutes. While idle, the RTX 5000 Ada pulls about 17 watts and loads up to about 252 watts. These are good numbers.
The power efficiency, however, is awesome. This card is often providing 80-100% of the performance of the NVIDIA RTX 4090 cards, but using only 60% of the power. For some, that will mean simply being able to add more cards to a system.
Cooling Performance
A key reason that we started this series was to answer the cooling question. Blower-style coolers have different capabilities than some of the large dual and triple fan gaming cards. With newer, warmer GPUs, we see fewer blower-style coolers. This is certainly a change over this project’s lifetime.
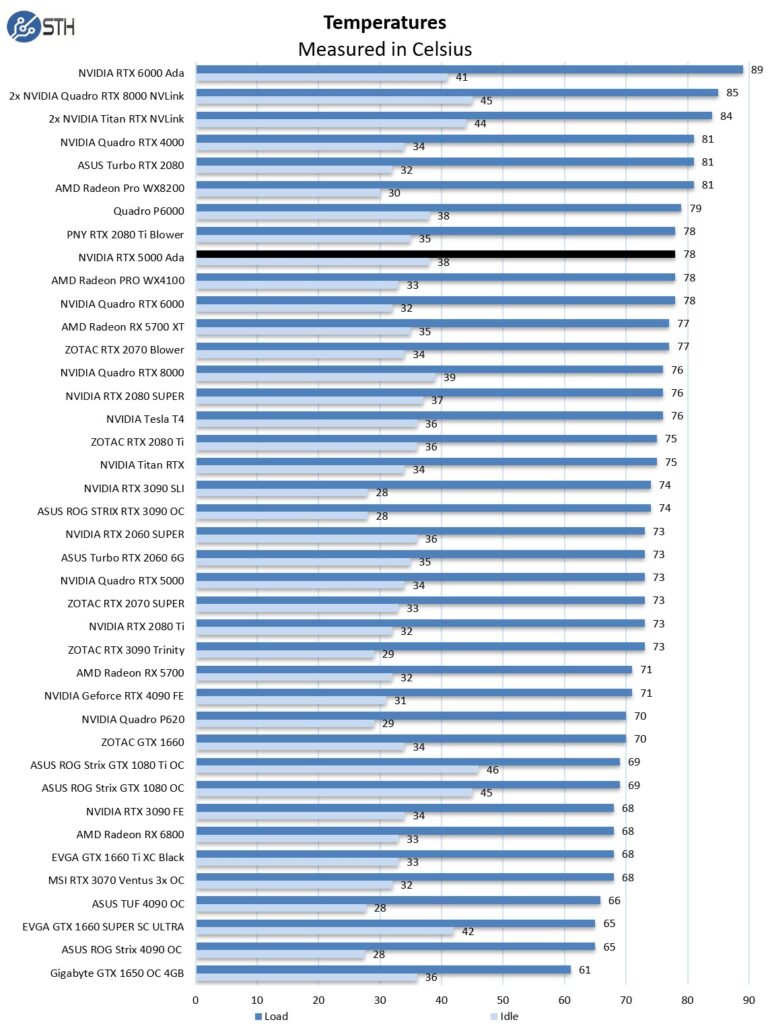
The RTX 5000 Ada runs warm, but not quite as hot as the RTX 6000 Ada got in our test system. Still, the big benefit for many will be the ability to have lower overall system power consumption. This is especially true as the newest Xeon and Threadripper processors can use well over 400-500W limiting the amount of power available for GPUs.
Final Words
Having used both consumer and workstation cards, the power consumption difference is becoming stark. The strange part is the area that the RTX 5000 Ada occupies. The RTX 6000 Ada commands a premium price over the GeForce RTX 4090, even though it is not always faster. A big part of that is because of its 48GB of ECC memory doubling the RTX 4090. The RTX 5000 Ada has a 33% increased memory footprint, but it is also running at around half the power of the RTX 4090’s. Some folks will question whether 8GB is worth the massive price tag jump. The more GPUs I use, the more I appreciate the lower TDPs of the RTX 5000 Ada and RTX 6000 Ada.

We are going to have a new test suite in 2024 that is going to streamline a bunch of the benchmarks we run and increase the amount of data science workloads. We will also be simplifying the presentation to more relevant data sets to help folks get through the data faster. We will include the RTX 5000 Ada results as we roll that out in the new year.

The NVIDIA RTX 5000 Ada is still a $5000 street price card that is very fast, and relatively efficient. At 250W, it seems almost mundane compared to some of the 700W+ GPUs we are now testing on the AI side. Still, during the review process something kept creeping in. If money was very tight, it feels like the RTX 4090 is a good budget card. If software licence and other costs are very high and outweigh the hardware costs, then the RTX 6000 Ada feels like the go-to choice. One day, NVIDIA is going to have to segment a bit more based on onboard memory capacity, maybe giving the RTX 5000 Ada level a bump in capacity to put some more distance between it and the consumer line. Still, there are many folks who will simply have the budget for the RTX 5000 Ada and will get this card precisely because it is NVIDIA’s best GPU in the price range. It is perhaps a strange way to think about it, but it seems like that is a decent market for NVIDIA. One thing is for sure though, the RTX 5000 Ada worked well for us during testing.
A quick thank you again to PNY for allowing us to borrow this card.



{kind=link}
I thought gaming GPUs didn’t use blowers because of an enforced market segmentation by Nvidia to prevent those GPUs from being used in the data center.
Yes. The dual slot blower is officially banned from nvidia for top-end cards. However we still have vendors making them and offering it as “cheap alternatives to dc cards”. This is something Nvidia does not want OEMs to make, but unable to ban OEM from making because the potential market is just so high.
The article doesn’t mention it, but I see these have been crippled when it comes to dual precision compute, just like the previous generations.
Ada, Ampere, Turing – no DP capable cards (or at least not severely cut down to 1/64 of SP performance).
Volta (GV100) is the last DP compute card released, and that’s becoming a bit outdated.
Once upon a time, these Quadros (or whatever they are named today) were engineer’s cards. You had to have a high-end one to accelerate engineering simulations (FE, CFD and similar). I guess AI stole the show, and nobody is going to cater to that small market anymore.
What’s the proper way to build a DP crunching workstation nowadays, anyway?
A key reason not discussed in the review for why some users will almost have to use this card vs a much cheaper and faster 4090 is the ECC Memory this card has. For some applications and uses, that is required, also for liability reasons.
Apart from all that, I prefer blower cards if available; unfortunately, current generation consumer cards in that design are almost impossible to find.
Actually you can enable ECC on 4090 the same way on RTX workstation cards. These cards both lose a portion of the total VRAM capacity if ECC is enabled, 4090 just has half of the total capacity.
@TurboFEM: That’s because both NVIDIA and AMD have abandoned FP64 in mainstream architectures as its market share is not worth the cost of silicon to implement it at full speed. Gaming doesn’t need it, and neither does AI/ML.
On NVIDIA side the H100 can perform one FP64 operation every 2 cycles, while the Ada can do it every only every 4 cycles. AMD has implemented native FP64 since CDNA 2, and further improved it in CDNA 3.
So basically for FP64 you need to go for the highest end compute accelerators.
@eastcoast_pete: There’s also driver support and qualifications that are critical for certain uses. Using mainstream cards and mainstream drivers is out of the question for them.
@Gnattu: NVIDIA specifically forbids using mainstream cards in commercial compute (via CUDA and driver EULAs), and actively goes after companies who, for example, rent them as public clouds. While you can try to use them internally, your legal department won’t be happy if they ever find out.
I’m glad to see that others have already mentioned blower GPUs didn’t fall out of favor with consumers, Nvidia enforced that consumer AIBs couldn’t use blowers to ensure that the cheaper RTX3090/4090 wouldn’t be used in workstations instead of their astronomically priced workstation GPUs. I see it’s very popular right now by blogs of all types to gloss over Nvidia’s hostile behavior towards consumers but it’s a damn shame.
Thanks John. That is good info as I am weighing upgrading from A6000 cards.
Running large language models is becoming increasingly common. Suggest having a benchmark for that in the future. For example running the 8x7b mixtral model is common these days.
@Kyle Actually I know some companies get caught. The nvidia geforce driver has its own telemetry so Nvidia knows what you are doing if you don’t cut this connection. The result? Companies now start to disable public Internet access for these nodes and you have to distribute work through a gateway so that the telemetry never reaches Nvidia. I know it is prohibited by Nvidia, but the amount of money we are talking about here is unlikely to be limited by an EULA.
@Gnattu: Oh sure you can work around this issue for internal use. The problem is when you try to sell it to the public as a cloud offering, for example. You can’t really hide the fact you’re using a consumer GPU then – your clients will be able to tell. The issue is whether those clients will care.
EULAs in general are a murky topic, but most “serious” companies will not even try to get into the grey zones.
Comments are closed.