
CES may still informally be the Consumer Electronics Show. But that does not mean everyone got the memo – or at least, cares to pay attention to it. Case in point is NVIDIA, who in the first major chipmaker press conference of the day opted for nothing less than to announce the launch of Rubin, the company’s next-generation AI platform.
Revealing that all of the necessary chips are back from the fab and that systems are being brought up in NVIDIA’s labs, NVIDIA is wasting no time in bringing the hardware to market – and even less time in announcing this. The next stop on NVIDIA’s meticulous hardware roadmap, the Rubin GPU and its associated chips are designed to take NVIDIA’s performance and efficiency to the next level, improving per-GPU AI inference performance by 5x, AI training performance by 3.5x, and then feeding those new GPUs with more compute, memory, and networking resources than ever before. In short, Rubin is NVIDIA’s effort to outdo themselves – and to prove that they can do it while keeping their lead over the competition.
Over the last several years NVIDIA has outlined an extensive roadmap for the further development and evolution of their core CPU, GPU, and networking architectures. It is a roadmap that leaves little room for surprises, but at NVIDIA’s scale the company can no longer afford to surprise its customers. So instead, NVIDIA has pivoted to being clear on what to expect, when to expect it, and then ensuring the company hits those deadlines.
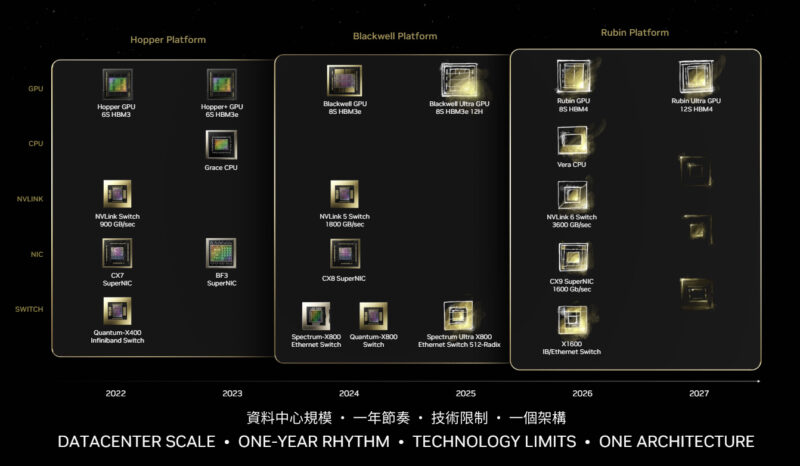
Rubin’s launch at CES, in that respect, is an “everything remains on schedule” announcement from NVIDIA. To be sure, the hardware is not shipping yet, and the ramp-up for production wo not even start until the second half of the year. But with working chips in hand, ecosystem partners already putting in their efforts, and more than a bit of bravado, NVIDIA has decided to kick off their 2026 by launching their next-generation platform.
And while NVIDIA is launching Rubin today, this was not a technical presentation from NVIDIA – though a separate technical blog is being published today. Instead, today’s press conference was a high-level look at what NVIDIA has been up to, outlining the chips behind the Rubin platform and the devices they will be going in, all while disclosing few key specifications for their next generation of hardware.
Rubin Platform: CPU + GPU + DPU + NIC + NVLink + Ethernet Switching
As NVIDIA has been outlining for the past year or so, Rubin is both a GPU architecture and a larger platform. And though NVIDIA remains first and foremost a GPU company, with the Blackwell platform and even more with the Rubin platform, they would really like to sell you the whole system – and indeed a whole SuperPOD, if they can. As a result, the significance for NVIDIA on the development and launch of the Rubin platform is not that they developed one high-end chip – it is that they developed six.
Rubin GPU
The star of the show is, of course, the Rubin GPU. NVIDIA’s next-generation GPU architecture and the lead implementation of it, the Rubin GPU (part number to be confirmed) is intended to leapfrog NVIDIA’s Blackwell and Blackwell Ultra (GB200) GPUs. NVIDIA is still holding the full details of how they will accomplish this close to their chest, but the big driver for the AI market is an updated transformer engine with support for compression – what NVIDIA refers to as one of their six “technology miracles.”

All told, the big Rubin GPU has been touted as offering 50 PFLOPS of compute for inference using NVIDIA’s NVFP4 format, which is five-times the inference performance of the Blackwell GPU. And while its training gains are not quite as immense, NVIDIA is now touting 35 PFLOPS of compute for training using the same NVFP4 format, which would put it three-and-a-half times ahead of Blackwell.
Like its predecessor, Rubin is a dual die chip, with two Rubin GPU dies on a single package. Fabbed on TSMC’s 3nm process, the two dies are “reticle sized”. Those dies, in turn, are paired with up to 288GB of HBM4 memory, the same capacity available today with Blackwell Ultra. But compared to the HBM3e memory used on Blackwell, Vera’s HBM4 will afford a total of 22 TB/second of memory bandwidth, a surprising 2.8x more than what Blackwell can offer.
In regards to transistor counts, the Rubin GPU measures in at 336 billion transistors, 1.6x that of Blackwell. Just how much power the chip will consume remains to be seen, however, as NVIDIA has yet to disclose the power consumption for the GPU. But they are claiming that it will offer eight-times the performance-per-watt of Blackwell when it comes to inference, which can be juxtaposed to the claimed 5x increase in performance.
NVLink Switch
The Rubin GPU will in turn once again rely on NVLInk to reach out to its neighbors to form larger scale-up clusters of GPUs. NVLink 6 doubles the available bandwidth from NVLink 5, with each GPU now offering 3.6 TB/second of NVLink bandwidth. And with it, NVIDIA has developed a new NVLink Switch chip (chip #2).

As you would expect for a doubled transfer rate, NVIDIA has needed to move to 400Gbps SerDes for NVLink 6. And with the NVLink 6 Switch chip offering full all-to-all bandwidth to each GPU hooked up to it, that gives the switch chip a total of 28.8 GB/second of bandwidth. That much networking traffic in a tight space also generates quite a lot of heat, and as a result the NVLink 6 Switch chip must be liquid cooled.
Vera CPU
Orchestrating all of this will be Vera, NVIDIA’s new high-end ARM-based CPU (chip #3), and the first part of the titular Vera Rubin duo. Each Vera CPU has been confirmed to be comprised of 88 CPU cores, codenamed Olympus, which is an NVIDIA-custom design that implements the Arm v9.2-A architecture. Internal architectural details are limited at the moment, but NVIDIA has confirmed that it is an SMT-capable design – allowing for 176 threads – via NVIDIA’s spatial multi-threading technology. At a high level, NVIDIA is touting that Vera will offer twice the data processing performance and twice the compression performance of Grace.

Vera will be attached to up to 1.5TB of LPDDR5X memory (3x that of Grace) using SOCAMM modules, which NVIDIA developed in conjunction with Micron. The move to modular memory is designed to resolve one of the few drawbacks of Grace-based GB200, namely its use of unchangeable soldered-down memory. All told, a Vera CPU will have access to 1.2 TB/second of memory bandwidth, a bit over 2x the bandwidth of Grace.
A typical DGX node will feature one Vera CPU that is paired with two Rubin GPUs, and connected to those GPUs via NVLink-C2C, the latest generation slated to offer 1.8 TB/second of bandwidth.
Vera will also be the final piece of the puzzle for NVIDIA to offer rack-scale confidential computing. While Blackwell could already handle encrypted workloads, Grace could not, limiting the size of the confidential domain to just the GPU. But with Vera now fully in sync with NVIDIA’s confidential computing technologies on Rubin, it will be possible to have the entire rack encrypted.
ConnectX-9 NIC & BlueField 4 DPU
Providing more traditional Ethernet connectivity to the Rubin platform will fall on the latest generation of NVIDIA’s ConnectX NIC and associated BlueField DPU technology.

The ConnectX-9 NIC (chip #4) will offer 1.6 Tb/second of networking bandwidth by utilizing 200G PAM4 SerDes. And in larger, multi-rack configurations, it will provide the basis for scale-out networking for larger clusters.

Its partner in crime (prevention) is the BlueField 4 DPU (chip #5). The latest BlueField is a mix of old and new, combining a 64 core Grace CPU with its own ConnectX-9 NIC. NVIDIA is touting BlueField 4 as offering twice the bandwidth, three-times the memory bandwidth, and six-times the compute performance as BlueField 3.
Spectrum-6 Ethernet Switching & Co-packaged Optics
Finally, tying all the rest of the Rubin platform hardware together will be NVIDIA’s latest Spectrum Ethernet switch, the Spectrum-6 (chip #6). This will be the heart of NVIDIA’s Spectrum-X switches, which for the first time for the company will implement co-packaged optics to rein in on power consumption.
Separate from NVIDIA’s various GPU boxes, the two key products for Ethernet switching will be SN6800 and SN6810 switches. A beast in any sense of the word, the SN6800 will offer 512 ports of 800G Ethernet or 2048 ports at 200G, for an aggregate bandwidth of 409.6 Tb/second. Meanwhile the smaller SN6810 will feature 128 ports of 800G or 512 ports of 200G – one quarter that of the SN6800, and at 102.4 Tb/sec aggregate bandwidth, one quarter of the throughput as well.

With co-packaged optics as the significant technical innovation here, NVIDIA is hoping to crack the formula for both reducing power consumption and improving the reliability of these large, high-performance switches. In short, by using a shared laser source and silicon photonics to modulate those lasers, the Spectrum-X switches will be able to provide high-speed optical networking with fewer fragile parts and without the high power cost of traditional optical networking.

NVIDIA certainly has high hopes for the switches, and is touting some very impressive numbers to go with them. According to the company, Spectrum-X switches with co-packaged optics will be able to offer 5x the power efficiency and 10x the reliability of an equivalent traditional networking switch.
The Hardware: Vera Rubin NVL72 and HGX Rubin NVL8
All of these new chips, in turn, will be going into various NVIDIA systems. Ahead of Rubin’s full commercial availability, NVIDIA is re-affirming that they will be offering two types of Rubin systems. For those going all-in on the NVIDIA ecosystem, there is an updated version of NVIDIA’s rack-scale NVL72 system. Meanwhile for those who need to keep a toe in the world of x86, NVIDIA will be offering a next-generation 8-way HGX carrier design, the HGX Rubin NVL8.
Like its predecessor, Grace Blackwell NVL72, a single Vera Rubin NVL72 rack (previously known as NVL144) will be comprised of 72 Vera Rubin GPUs (144 GPU dies) as well as 36 Vera CPUs. As this is a purely scale-up solution, all of the GPUs are connected to each other via NVLInk switches. The sum-total of all of this hardware is a whopping 220 trillion transistors, and undoubtedly an obscene amount of power, as well.

With regards to performance figures, virtually all the high-level numbers show the same level of improvement as a single Rubin GPU. So a Rubin NVL72 rack offers 5x the inference performance, 3.5x the training performance, etc. Or to put that in numbers, 3.6 EFLOPS of compute for inference and 2.5 EFLOPS of compute for training. Backing that performance will be a sum total of 54TB of LPDDR5X (2.5x that of GB200 NVL72), 20.7TB of HBM4 memory (1.5x that of GB200 NVL72), and a cumulative 1.6PB/second of HBM4 bandwidth (2.8x that of GB200 NVL72).
Outside of the intricate chips that comprise an NVL72 rack, NVIDIA has also apparently gone back to the drawing board to simplify the design of the rack itself – with the Blackwell generation having generated plenty of murmurs of issues. The big shift here is that NVIDIA has moved to a fully cable free modular tray design, which massively cuts down on the amount of time needed to stand up an NVL72 rack. According to NVIDIA, the assembly of a single rack has gone from 100 minutes on Blackwell to just 6 minutes on Rubin. And by removing so many cables altogether, NVIDIA is expecting this to improve reliability as well, as the cables themselves were potential failure points.
Coupled with some further improvements to NVIDIA’s NVLink technology and their second-generation RAS engine, NVIDIA is promising that Vera Rubin NVL72 can achieve zero downtime for health checks and network maintenance.
One More Tool: NVIDIA Inference Context Memory Storage Platform
Going beyond a single NVL72 rack means moving to scale-out computing, and with that NVIDIA increasingly relies on its networking technologies to help get the job done. Besides the aforementioned ConnectX-9 NICs, BlueField DPUs, and Spectrum-X switches, NVIDIA is also adding one more tool to their toolbox: a key value (KV) caching system called the NVIDIA Inference Context Memory Storage Platform.

A further use case for NVIDIA’s networking hardware, NVIDIA’s context memory storage platform is intended to serve as a KV cache for inferencing. As with other KV cache ideas (e.g. Enfabrica), the basic idea is to insert another tier of storage specifically to store key value pairs used in inference. Because the amount of context data generated by modern models is so significant – especially multistep models – there is too much context data to be stored at the node level. That leaves system operators with the option to either toss the data and recompute it later, or store it in some fashion. A KV cache does just this, allowing for context data to be saved and (relatively) quickly retrieved for further use rather than recomputed.

Essentially, NVIDIA is pitching this as POD-scale optimization technology to work around current bottlenecks in inference performance. At a high level, they are promising as much as a 5x improvement in inference performance and 5x better power efficiency – a significant improvement indeed.
As for the hardware used, this would leverage NVIDIA’s networking products, but it would not be an NVIDIA box ala the DGX boxes or a Spectrum-X switch. Instead, NVIDIA would provide the parts and let their partners pick up the rest, assembling context memory storage nodes out of SSDs for storage and BlueField/ConnectX hardware to link back to the respective AI nodes.
Even though it is not an NVIDIA product per-se, NVIDIA is going all-in with their context memory storage technology. Not only is NVIDIA developing the necessary network hardware, but they have added the necessary software functionality to the CUDA stack as well, exposing it in Dynamo, DOCA, and other frameworks. It is only fitting then that they will be using it themselves for their biggest tier of systems, the SuperPOD.
DGX SuperPODs: Now for Rubin
With a new GPU architecture and new NVL72 racks, NVIDIA’s hardware stack is completed by the grand amalgamation of all of that hardware, the DGX SuperPOD. As with the Blackwell generation, the SuperPOD is intended to both serve as a blueprint/proof-of-concept for scale-out GPU systems, but also a commercial product for NVIDIA to sell to customers.
NVIDIA will be offering two SuperPOD configurations to potential customers. The first, based around their Vera Rubin NVL72 racks, incorporates 8 of those racks, NVIDIA’s Specturm-X Ethernet and Quantum-X800 InfiniBand networking switches, BlueFlield 4 DPUs, and storage nodes for context memory storage. This is intended to be Vera Rubin at its highest level.

By the numbers, a single DGX SuperPOD with DGX Vera Rubin NVL72 will incorporate 8 NVL72 racks, for a total of 576 GPUs, 288 CPUs, and some 600TB of memory. In terms of total throughput, NVIDIA is touting an enormous 28.8 EFLOPS of compute performance at NVFP4 precision, and with enough NVLInk bandwidth that model partitioning within a rack will no longer be necessary.
Alternatively, for x86 users NVIDIA will also be offering SuperPODs built around DGX Rubin NVL8 nodes. This is a less dense option overall, with 64 NVL8 nodes being combined into a single SuperPOD to offer 512 GPUs. Otherwise this is a similar scale-out design, heavily leveraging NVIDIA’s hardware to scale DGX Rubin NVL8 beyond a single rack of nodes.
Rubin Platform: Available in Second Half Of 2026
Wrapping things up, while NVIDIA is still in the bring-up phase for their hardware, the company’s partners are already hard at work preparing their own services, as well as jockeying for position of who will be first to offer Rubin-based services. According to NVIDIA, AWS, Google Cloud, Microsoft, and OCI will all be among the first public clouds to deploy Vera Rubin instances in 2026.
Ultimately, NVIDIA is expecting to deliver production hardware to partners in time for them to offer products and services in the second half of 2026. NVIDIA also expects to begin offering DGX systems in the same timeframe.



{kind=link}