
To say that machine learning is a big deal in the chipmaking space is understating things. The gold rush of our times, presentations related to machine learning and the hardware driving it are a major presence at this year’s Hot Chips show. And indeed, in terms of content, machine learning is the single biggest subject track at Hot Chips, with 2 full sessions (3 hours) dedicated to half a dozen presentations from some of the biggest names in the ML and AI space.
Leading things off for the first session this afternoon is Marvell. The chipmaker and IP firm has their hand in a whole lot of high-performance ML chips in one fashion or another, often via their memory controller designs. Fittingly, the company is at this year’s show to talk about why memory is almost the only thing that matters for the data center – and how Marvell’s technologies can allow customers to get ahead of the curve in both memory bandwidth and memory capacity.
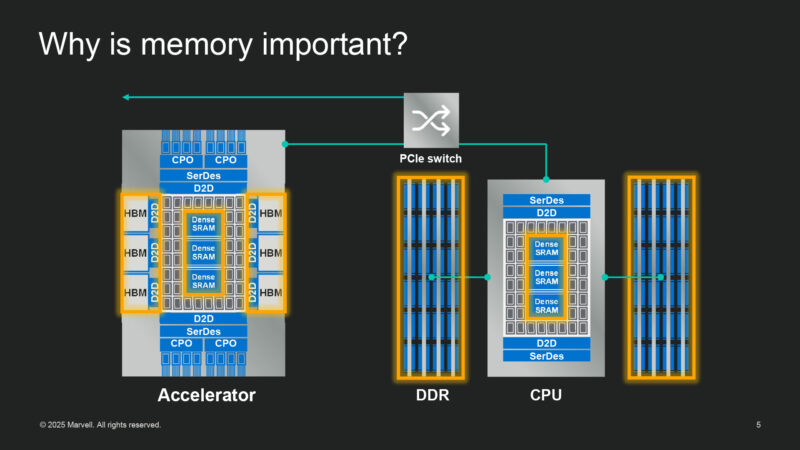
Why is memory important? It’s the key to everything.
Today’s processors are using SRAM to supply an immense amount of bandwidth. This goes for both the CPU and accelerator. So optimizing the use of memory is incredibly important.
There are multiple memory technologies: SRAM, HBM, DDR, and they all have a place in the data center.
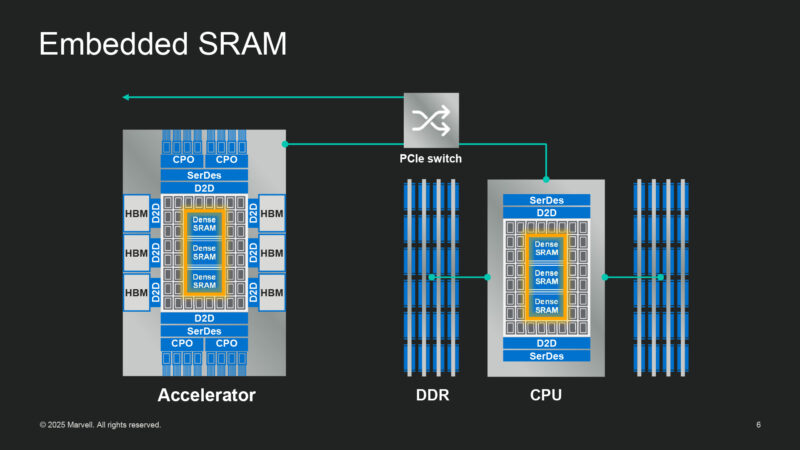
Starting off with embedded SRAM. SRAM cells are not scaling up in density very quickly anymore.
So Marvell is looking to get around that and do what they can to push things along.
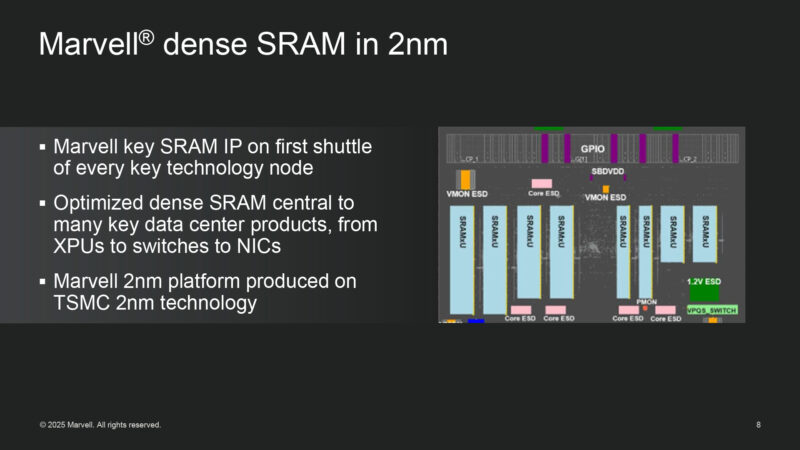
Marvell puts their custom dense SRAM IP in all of their leading chips. And they will be building SRAM on TSMC’s 2nm node.
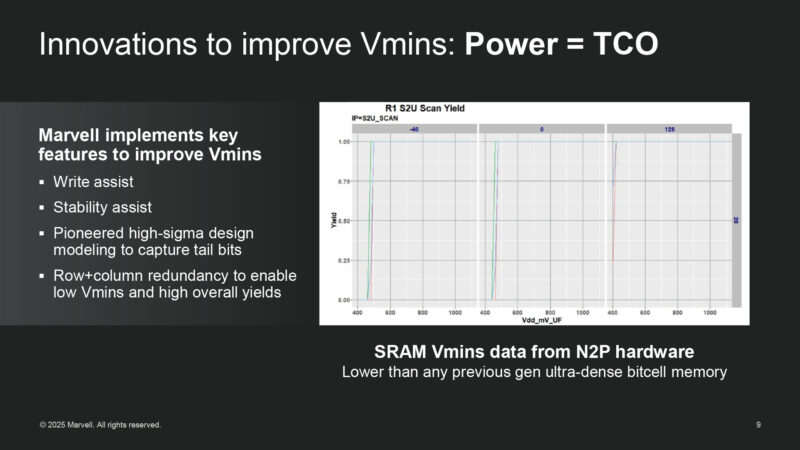
And here’s the 2nm performance data. They’ve achieved groundbreaking Vmins on 2nm. All of which saves power, and looking at the bigger picture, TCO.
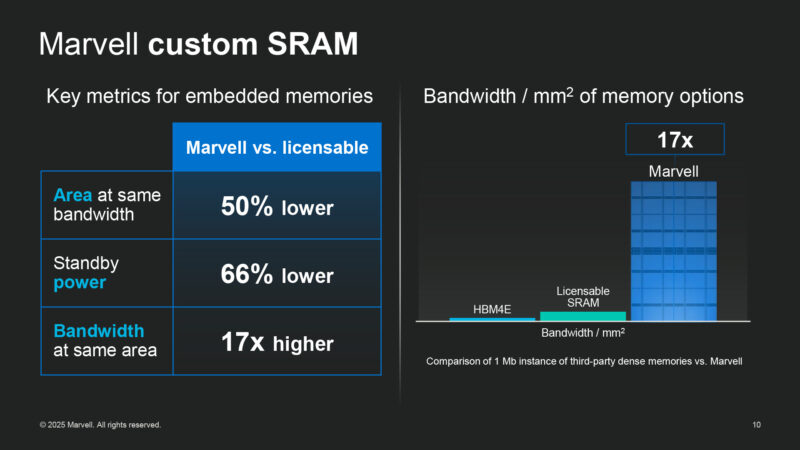
Marvell claims that their custom dense SRAM is 17 times the bandwidth density of off-the-shelf IP for the same process geometry. Marvell will walk the HC audience through how they’ve accomplished this.
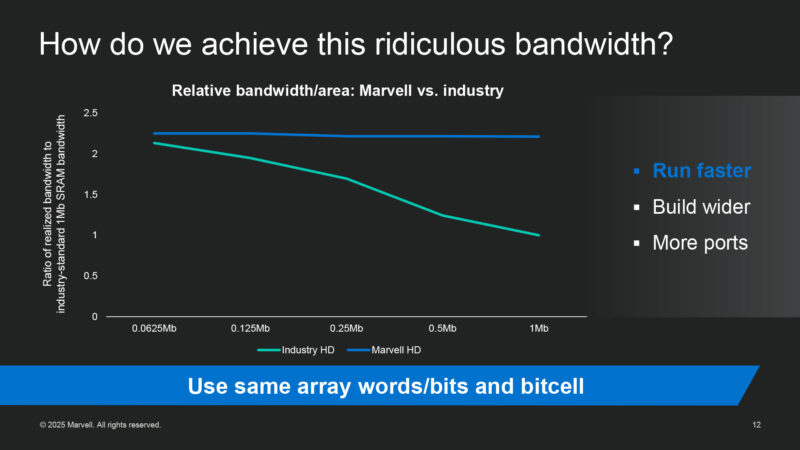
So how do they do it? In 3 ways. Starting with just flat-out running faster than other HD cells in the industry. And, uniquely to Marvell, they are able to hold their high target frequencies even with large 1Mbit SRAM arrays.
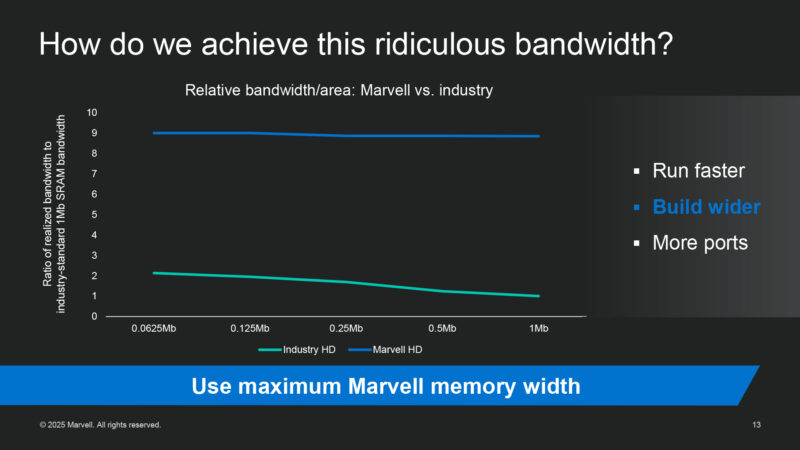
Marvell also builds their SRAM cells wider, with larger macros achieving an even higher multiple.
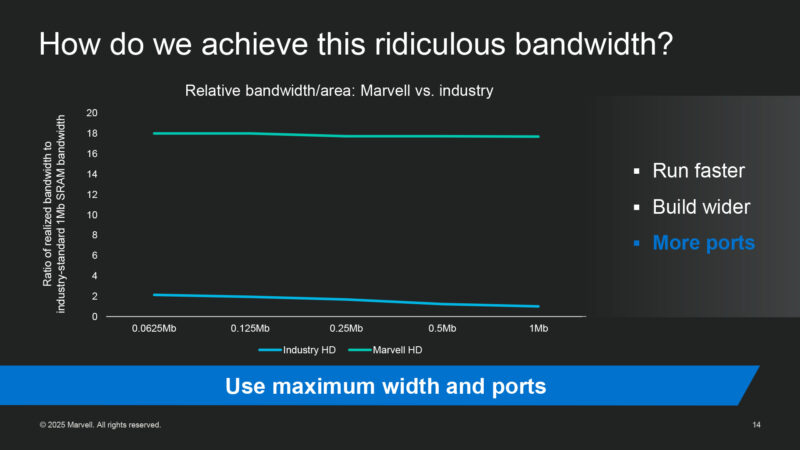
And finally, they add more ports within the same area in order to add even more bandwidth. Bringing them to the 17x total.
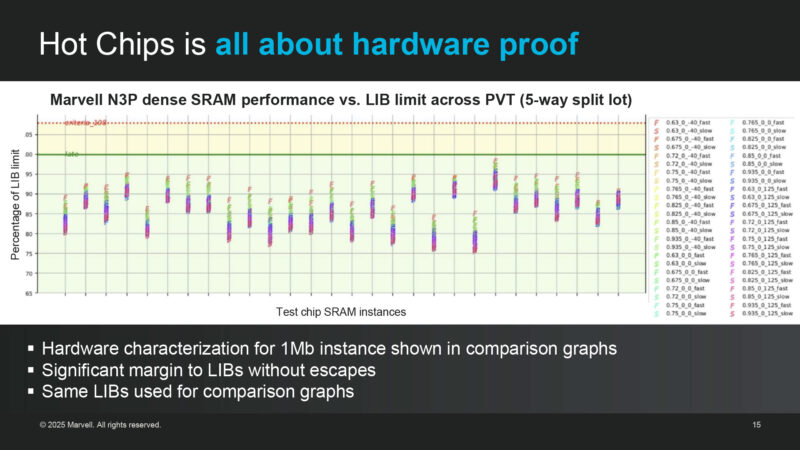
And the proof is in the hardware. The above is Marvell’s N3P dense SRAM comparison graphs. Mavell’s macros are overachieving, according to the company.
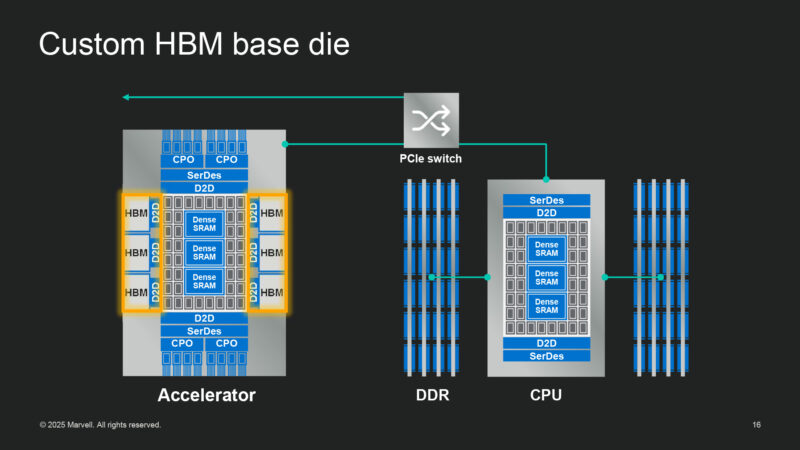
Moving on to custom HBM. Marvell has been working on this for years, and has relationships with all 3 of the major HBM providers.
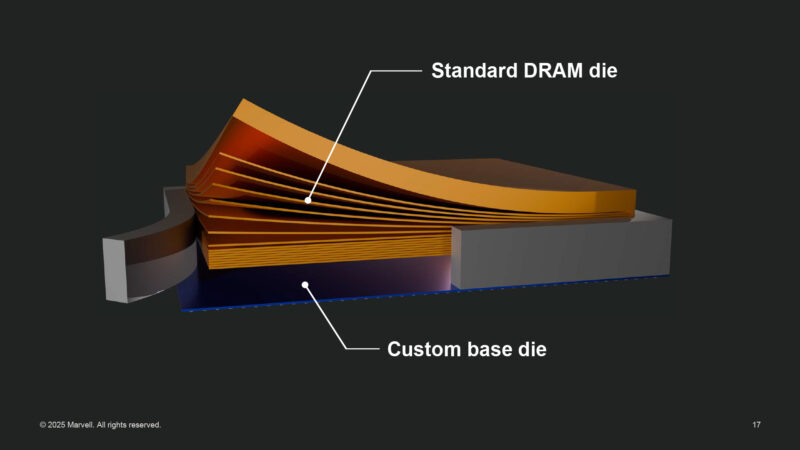
What does a custom HBM look like? A stack of DRAM dies layered over a custom base die. Marvell takes standard DRAM dies with their custom base die optimized for accelerators it’s paired with.

Why go through all the trouble? HBM interfaces take up a lot of on-chip area. It eats into compute area. Instead, Marvell uses die-to-die IP everywhere they can. Which cuts down on the amount of on-chip area used. And, according to the company, they can use much less power in the process.
Marvell can always leverage some of the spare area on the custom HBM stacks for additional functionality.

And here Marvell further illustrates the difference between standard HBM PHYs and their custom designs. Moving much of the hardware off the compute chip and to the HBM base die.

As a result of those changes, Marvell sees a major reduction in the interface area, while interface power is reduced significantly.
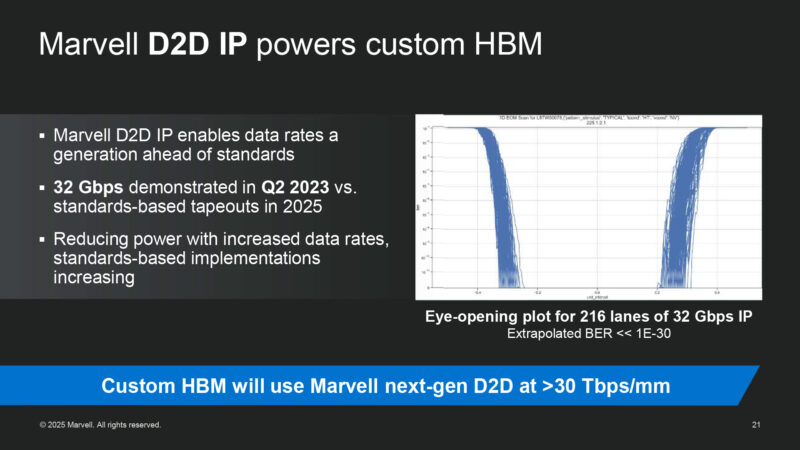
Marvell uses their own die-to-die IP. They had the first 32Gbps D2D IP a few years ago.
Eye plot on the right: Marvell can’t get it to fail in the lab. Their extrapolation is that the BER is less than 1E-30.
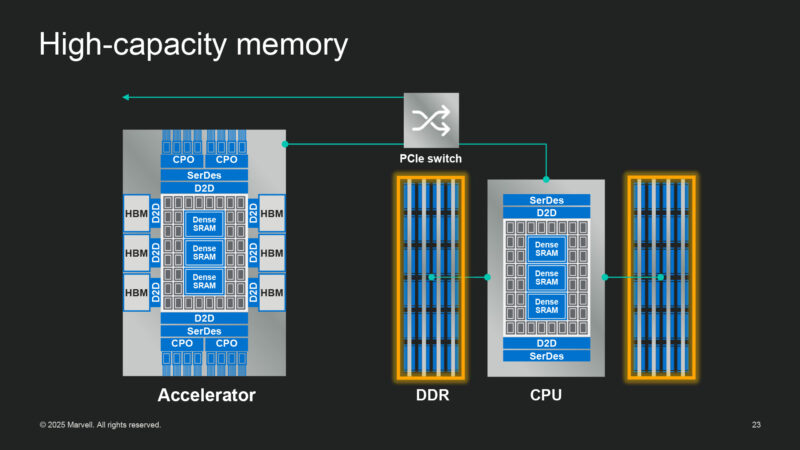
Moving on to high capacity memory. i.e. DDR memory. (HBM is fast; it isn’t very large). This makes it very important for AI systems and large models.

Marvell is building their own high capacity memory expansion devices. They even build processors into their memory expansion devices.
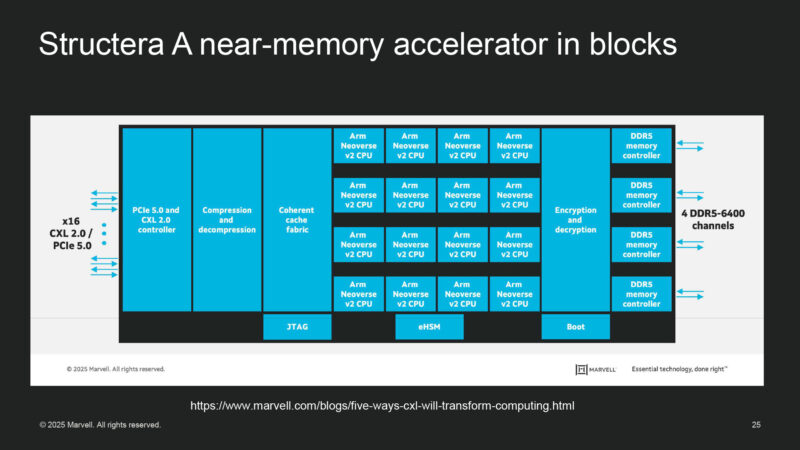
Here’s a block diagram of a Structera A near-memory accelerator. Everything you could want, ranging from encryption and compression to Arm Neoverse v2 CPU cores. There is an embedded hardware security macro to keep memory secure in the datacenter.
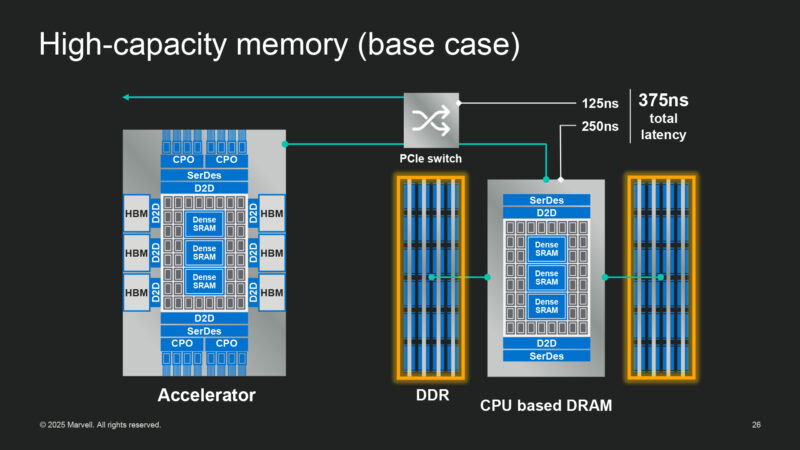
Marvell says their tech can significantly improve latency and bandwidth within a system.
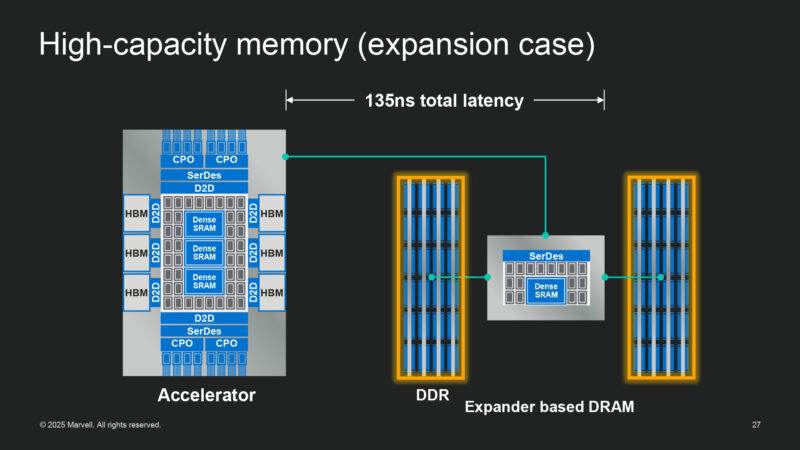
Using a memory expander device can cut down significantly on latency by avoiding going through the CPU and any PCIe switches.

In summary: dense SRAM, custom HBM, and optimized DDR memory work together to offer improved memory bandwidth and latencies at every level of the memory hierarchy.



{kind=link}
Doing compute on a custom base die of the HBM stack is a great idea. Marvell is saving I/O power because they are reducing the amount of data transferred between their base die and their main accelerator ASIC. Slide 21 shows 216 lanes of 32 Gbps, which is 864 GBytes/sec. Each stack of HBM4 provides about 2 TBytes/sec. Having a custom base die on the bottom of the HBM stack might avoid the need for a silicon interposer or silicon bridge to connect the HBM stack to the main accelerator ASIC, which would save cost.
Not mentioned in this article, but visible on the first slide, are 16 fibers attached to the accelerator package for co-packaged optics (CPO). This suggests Marvell is going after the AI training market and intends to connect a large number of accelerators together with fiber optics. Having field replaceable laser modules, like Broadcom’s TH6-Davisson ethernet switch, is the best and only practical approach I’ve seen for CPO.
To be successful, Marvell will need to create software for AI training. That is a bigger and more difficult job than creating this very impressive hardware. Intel hasn’t been able to crack that nut despite trying for the last 9+ years. Marvell could also use this chip for the much bigger AI inference market by replacing the HBM with High Bandwidth Flash (HBF).
Circuit designers are sometimes considered like assembly language programmers. Instead of using an SRAM compiler, Marvell shows that good circuit designers can still be a real difference maker, just like assembly language programmers.