
We are a bit behind this week due to CES, but Marvell made a big announcement. It is acquiring XConn Technologies, which makes a lot of sense on multiple levels. It gives Marvell access to a technology that plays in two markets, CXL memory expansion, as well as PCIe switching.
Marvell Announces XConn Technologies Acquisition in CXL and PCIe Push
As a quick refresher, we have been covering XConn since its XC50256 CXL 2.0 Switch Chip was shown at FMS2022. The original chip (which underwent some challenges and respin work) was a 256-lane PCIe switch, challenging Broadcom’s 144-lane switches. Broadcom/ Avago’s 2015 PLX acquisition eventually became the 800-pound gorilla in the PCIe switching space. As it turns out, building high-end and high-throughput PCIe switches is challenging. Since it was a PCIe Gen5 chip, it also has CXL 2.0 supporting variants, making it one of the first switches that was designed for CXL as well.

Many are looking at these PCIe/ CXL switches as both the topologies for AI accelerators/ NICs are growing, as well as using CXL memory has become a force in the industry.
CXL Type-3 memory devices, like the Marvell Structera line, you can add DDR memory directly into repurposed PCIe lanes that support CXL. We are not going deep into how that works, since we recently did an entire feature on that in Hyper-scalers Are Using CXL to Lower the Impact of DDR5 Supply Constraints.
Marvell has a number of hyper-scale clients that are looking at ways to solve the DRAM shortage by using CXL and CXL memory with compression to keep DRAM used for longer periods of time.
Final Words
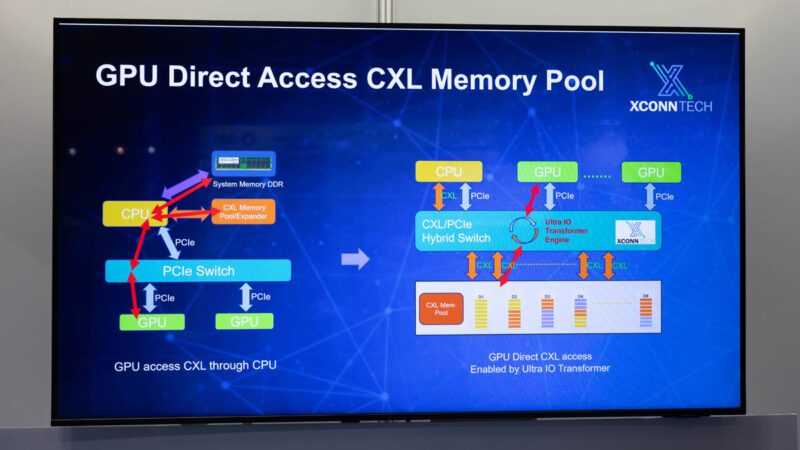
Looking forward, XConn has PCIe Gen6 and CXL 3.1 switches in development, CXL 3.1 as we have discussed before, is a major change in capability for shared memory pool devices. While we have shown some of these CXL memory controllers and devices in servers, the bigger impact is memory pooling. Think of this as shelves of memory, new or recycled DDR5, DDR4, or other types of memory, where switches connect multiple CXL memory controllers with one or more nodes. The holy grail of this is being able to have one copy of compressed data in a CXL memory shelf, but then sharing it in a coherent fashion among many compute nodes as that drastically reduces the memory footprint of the data. We are still a ways off from that but if you think of that as a goal, it is logical that PCIe/ CXL switches will be required. While we mostly are focusing on CXL here, we have been reviewing large PCIe GPU topologies using PCIe switces for years, and explained why the 256 lane switch is a big deal in 2024.
Of course, contratulations to Gerry and the XConn team are in order.



{kind=link}
Just a quick terminology clarification.
When you say — ” The holy grail of this is being able to have one copy of compressed data in a CXL memory shelf, but then sharing it in a coherent fashion among many compute nodes as that drastically reduces the memory footprint of the data.” — That is memory sharing.
Memory pooling is allowing non-coherent nodes to allocate from the same pool of memory but not coherently share that memory. Pooling is attractive/interesting since it theoretically will reduce the amount of stranded (unused) memory.
Astera has a good taxonomy on this — https://www.asteralabs.com/faqs/what-is-the-difference-between-memory-pooling-and-sharing/
Thanks Ronak. Great point. I hope all is well.