Intel Xeon Max 9480 Performance
Presenting the performance of the Intel Xeon Max 9480 gave us absolute fits because we tried boiling the ocean at some point. The reason for that is what we saw in our previous section. There are six different configurations, and using the HBM Flat Mode options often requires playing with data placement to deal with different memory pools.
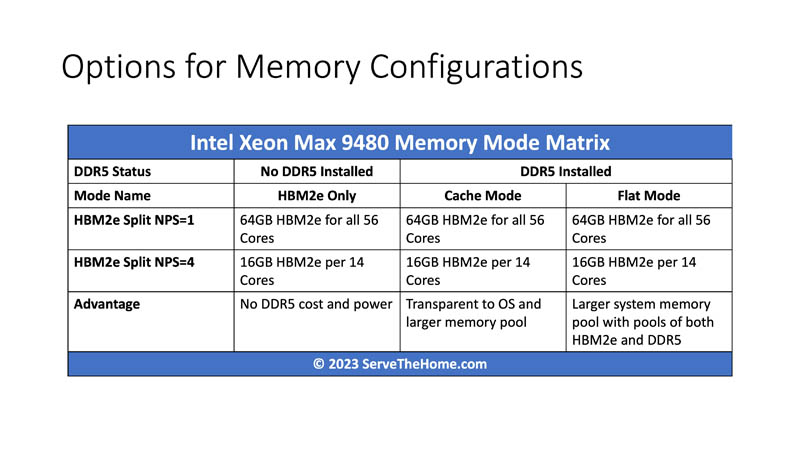
Six options may not sound bad, but realistically, this is a HPC-focused part. In the HPC realm, many codes do not benefit, and can potentially run slower with SMT or Intel Hyper-Threading. All of the six cases in the matrix above have another dimension of Hyper-Threading ON and OFF bringing our total to at least 12.
Here are Intel’s official numbers for the Xeon Max on a number of popular workloads. Intel’s performance team does a lot of this tuning to get these numbers, and so we are going to say look to this if you want a more official performance expectation on a given workload.
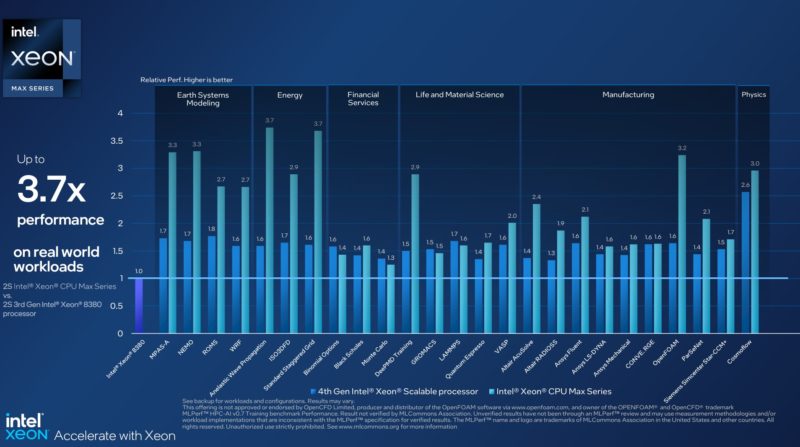
Instead, we just wanted to show something cool and beyond just running STREAM and at least provide some thoughts.
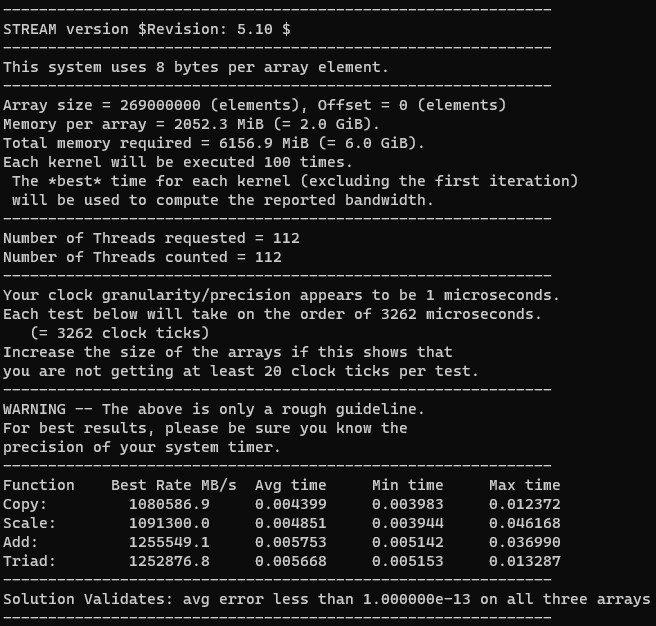
First, let us point out the obvious. If your workload runs almost entirely in cache, then the HBM2e memory onboard is not a benefit. HBM2e packages use power, so clock speeds on the Xeon MAX part are slightly lower than the Intel Xeon Platinum 8480+. Of note here, one may see the EPYC 9684X runs into a similar challenge with the extra L3 cache not mattering and therefore lower clock speeds hurt performance here.
Since we know folks are going to ask, here are the SPEC CPU2017 figures for the parts. Intel focused the Xeon Max on floating point performance, not on integer performance, and that shows. Still, something like the SPECrate2017_int_base score is not going to be impacted by HBM2e but it is impacted by slightly lower clock speeds.
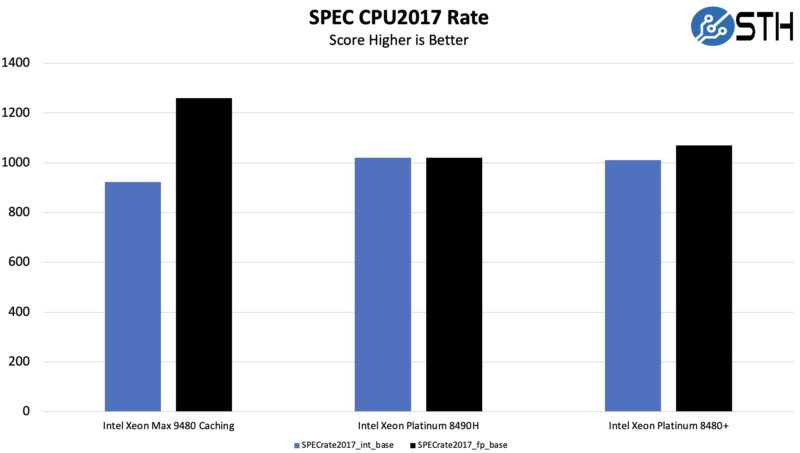
The other takeaway here is that this is a great example of where a widely used benchmark in server RFPs will not even utilize the big performance boost of HBM2e memory.
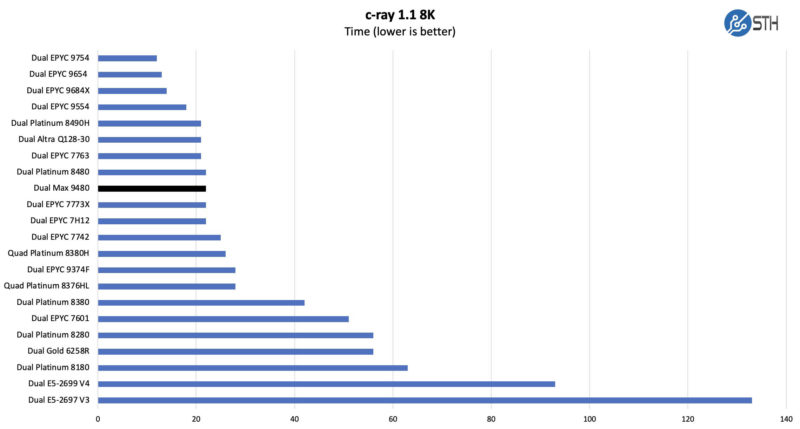
We left Hyper-Threading on, ran a few different workloads, and found some really interesting results. For several of them, we are just going to say we are directionally similar to what Intel saw, but Intel is doing more tuning so we would use Intel’s numbers.
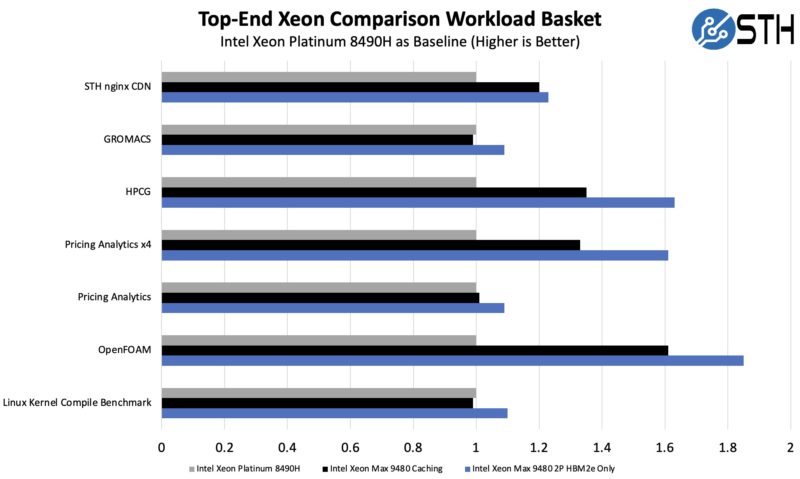
Running HBM2e only or adding DDR5 to run the chips in a caching mode made the chips certainly have an impact. There was more to this than one might think. Something that we have not heard many others talk about, but we found fairly quickly, was the impact of problem size. A great example is our pricing analytics workload that seeks to build a discounted deal pricing, according to regional revenue recognition rules, for a given deal based on any BOM that a data center OEM may use. We found that running the application on the chips really did not provide a huge difference. Then, we changed the test and ran four copies, one for each compute tile, and the results were much better.
As a quick aside, this is not uncommon these days. In our primary server CPU reviews, we had to split our Linux Kernel Compile benchmark into running multiple copies on a CPU in order to keep cores utilized.
We even ran our KVM virtualization testing on these parts and saw something similar. Despite having lower clock speeds, and being an integer performance-dominated test, Xeon Max actually did well when it hit a sweet spot of HBM2e usage in caching mode.
Of course, the elephant in the room is AMD EPYC. There are many workloads where having chips like the AMD EPYC 9684X with huge caches and 96 cores is very good. There are others where having HBM2e helps keep cores fed.
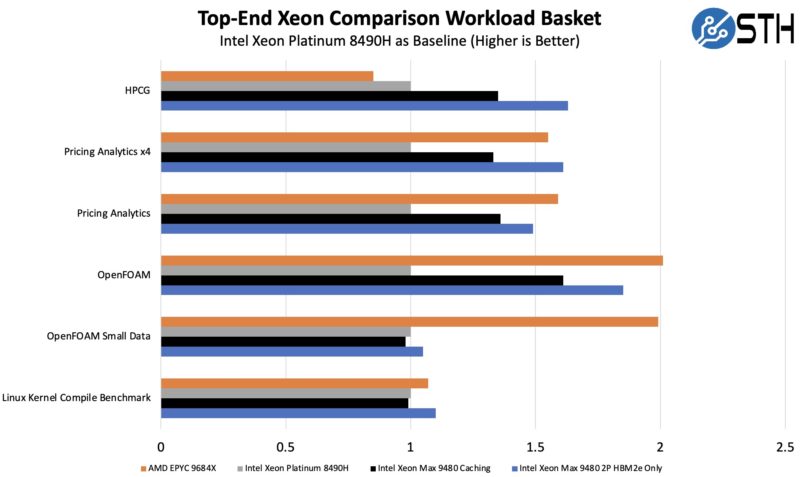
Perhaps the best way to think about this, especially if we had the same core counts, is that the working data set size and perhaps more importantly, the size of the hot portion of a data set is an enormous determining factor here. The chart above has a different OpenFOAM test case that is less sensitive to HBM and more sensitive to Genoa-X cache due to the problem size just to show how sensitive this stuff is. In most cases, for that workload, HBM helps a lot, but we wanted to show some of the sensitivity. Note, we swapped this chart to show both cases to make this a bit more clear. It shows the problem set sensitivity better anyway.
The other side goes back to our original discussion in this section. There are effectively twelve primary configurations HT ON/OFF, HBM2e only/ Cache Mode/ Flat Mode, NPS=1 or NPS=4. For AMD, one can turn SMT ON/OFF and split the CPU into quadrants as well so the number of permutations for AMD is exciting as well.
The bottom line is that adding HBM2e to a CPU is not always going to make it the fastest, but sometimes it can add an enormous amount of performance. Our ending recommendation here is simple: If you are in the market, go try Xeon MAX. That is not just for HPC customers either. There are likely a number of non-HPC customers that can benefit from HBM2e onboard that likely have no idea these chips even exist, even though they are drop-in replacements to many existing Xeon sockets. A great example of this is Numenta recently discussed doing AI inference on Xeon MAX faster than GPUs using its software and Intel AMX. Servers are becoming like cars or mattresses where it pays to try before you buy.
Next, let us talk about power consumption.



){kind=link}
Terabyte per second STREAM is spectacular – this is comparable speed from a single server to running STREAM across an entire Altix 3700 with 512 Itanium processors in 2004, and rather faster than the NEC SX-7 which was the last cry of vector supercomputers.
Thanks for the power state info – I was wondering about 14 core/16GB HBM/dual memory consumer version. Oh well!
Despite what Intel stated by power states, I’d have at least tried booting the Xeon Max chip on a workstation board. Worth a try and it would open up a slew of workstation/desktop style benchmarks. While entirely inappropriate a chip of this caliber, I’m curious how a HBM2e only chip would run Starfield as it has some interesting scaling affected by memory bandwidth and latency. Be different to have that HBM2e comparison for the subject.
The open foam results don’t match between the two plots. Where one says hbm2e only is 1.85 times faster and the other says it’s only 1.05 times faster.
Can these be plugged into a normal workstation motherboard socket? as in a few years when these come on the market that mortels can buy off of ebay we wantto play with them in normal motherboards with normal cooling air cooling solutions
I had no idea that they’re able to run virtualization. I remember that I’d seen them at launch but I was under the impression that they’re only for HPC and that they’d done no virtualization and acceleration because of it. We’re not a big IT outfit, only buying around 1000/servers/year but we’re going to check this out. Even at our scale it could be useful
@Todd, Shhhhh! Quiet! Lest Intel hear you and fuse off the functionaility as they used to do…
Is that a real Proxmox VE pic? I didn’t think these could run virtual machines. Why didn’t Intel just call these an option if so. That 32c 64gb part sounds chill
It’s possible virtualization is not an advertised feature because there are too many information-leaking side channels.
At any rate, as demonstrated by the Fujitsu A64FX a couple years ago, placing HBM on the CPU package makes GPUs unnecessary and is easier to program. After the technology has been monetised at the high end, I expect on-package HBM will be cheaper than GPU acceleration as well.
Thank god there’s a good review of this tech that normal people can understand. This is the right level STH. I’m finally understanding this tech after years of hearing about it.
That STREAM benchmark result is impressive.
My 4GHz 16 core desktop computer copies value of double arrays at 58GB/sec, according to my STREAM build with MSVC, and I consider it as pretty decent, because it copies 15 bytes per 1 CPU clock cycle.
intel compiler should optimize STREAM for loop of double array copy with very efficient SIMD instructions
Comments are closed.