
Perhaps one of the more anticipated releases from Intel this year is Knights Landing (abbreviated KNL) which is the next generation of Xeon Phi Processor. While the first Xeon Phi was very interesting, essentially bringing to market an x86 many core offering to the marketplace for the first time to compete with GPUs, KNL is the game changer. Knights Landing is essentially a huge amount of modified Silvermont cores (think the cores inside the Atom C2000 series) that have been modified to compete with the GPU compute solutions from NVIDIA and AMD. Some of the big changes this go-around: the chips are bootable by themselves. Jokingly at an Intel facility a few months ago it was said that the new Knights Landing could actually function as normal web server, albeit with an insane number of cores. While Xeon Phi brought the concept of many core x86 to market, Knights Landing is going to bring much closer binary compatible computing to the add in co-processors.
It is that time of year again for Hot Chips (27) so Intel has a presentation on their new Knights Landing chips. It goes into a lot of detail on-slide so we are going to simply present the majority of slides and add a bit of commentary as warranted.

Key items here: binary compatible with current Xeons, much like the Atom C2000 is. Memory and fabric integrated. Big performance gains and three product offerings. More on that last topic later.
So how many cores are we talking? 36 tiles * 2 cores per tile. Each core has two VPUs (vector processing units) which are really the magic behind making these supercomputing chips.
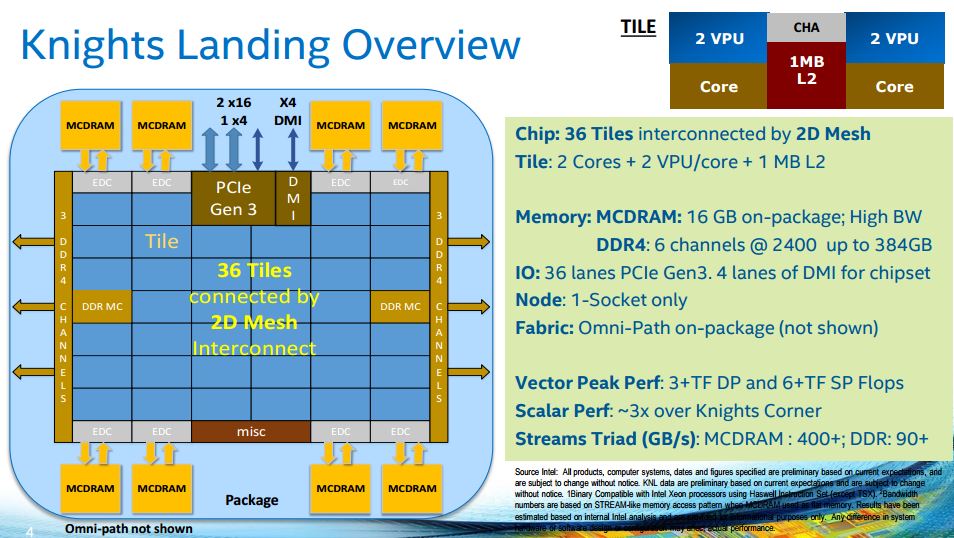
Other key insights – 2D mesh interconnect because the Tiles need to talk to each other. One can also see six channel DDR4 memory interface. That means that instead of having cards with access to tens of GB of memory, Knights Landing gives access of up to 384GB. DDR4 is slower than GDDR5 or other types of memory commonly used on GPUs, but KNL is set to be a Xeon replacement. There is 16GB of MCDRAM (Multi-Channel) DRAM which is Intel’s high bandwidth solution.

With 4 threads per core, 2 cores per Tile and 36 Tiles per KNL chip, we are talking a LOT of threads here.

Deep diving on the cores for a moment, Intel has multiple layers of cache which are important for keeping everything fed.
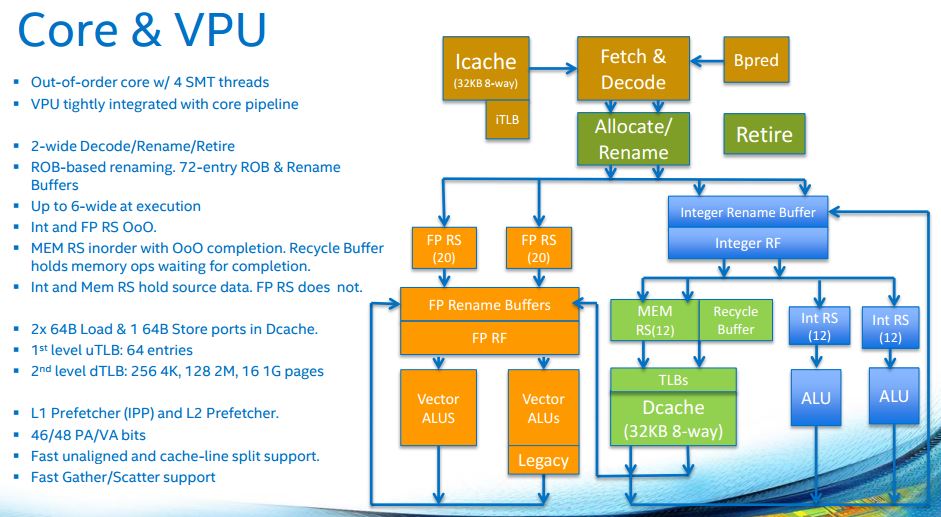
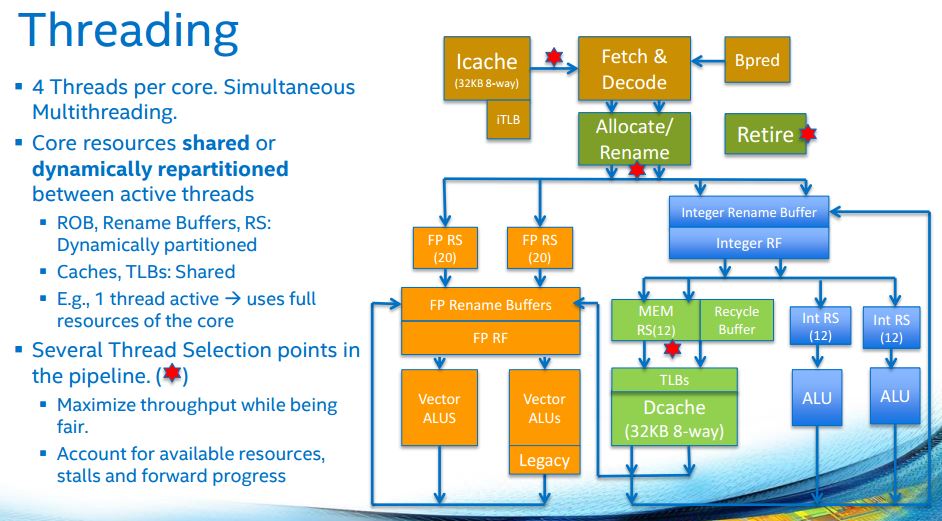
With multiple threads per core, the execution engine keeping threads live is complex.
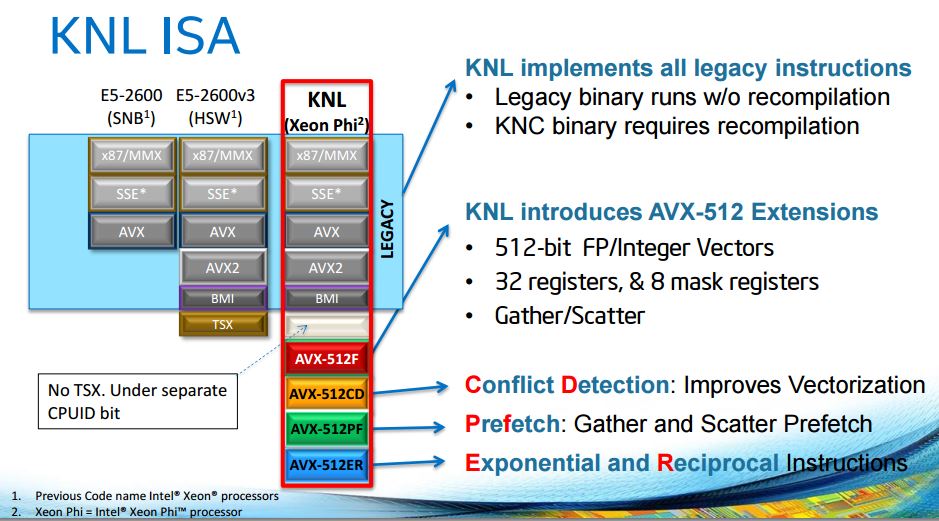
Here is the really interesting part: KNL has backwards compatibility with Xeon ISA. In theory if you wanted to take your Pentium MMX code, 15 year old SSE code and new AVX2 code and run it directly on Knights Landing it should work. Intel also adds more advanced AVX features to the mix to help in the primary application: supercomputing. We do not expect KNL to replace the average Xeon E5 series anytime soon for traditional server tasks, but it could!
MCDRAM has a number of on boot selectable modes. 16GB is only so much memory to go around. The critical point is that system RAM is directly connected via a 6 channel DDR4 memory. Would it not be awesome to see 6-channel memory in future Xeon E5 processors (hint?) The big bonus of this setup is that KNL gets more memory bandwidth and can avoid the PCIe bus. Essentially Intel is bypassing the Xeon E5 in today’s systems in many use cases. This is dedicated x86 + vector compute on one package.

Getting data to all of these cores is not a simple task. Not only is there MCDRAM, DDR4 DRAM but there is also the PCIe bus and 35 other Tiles that can be targets or senders of data.
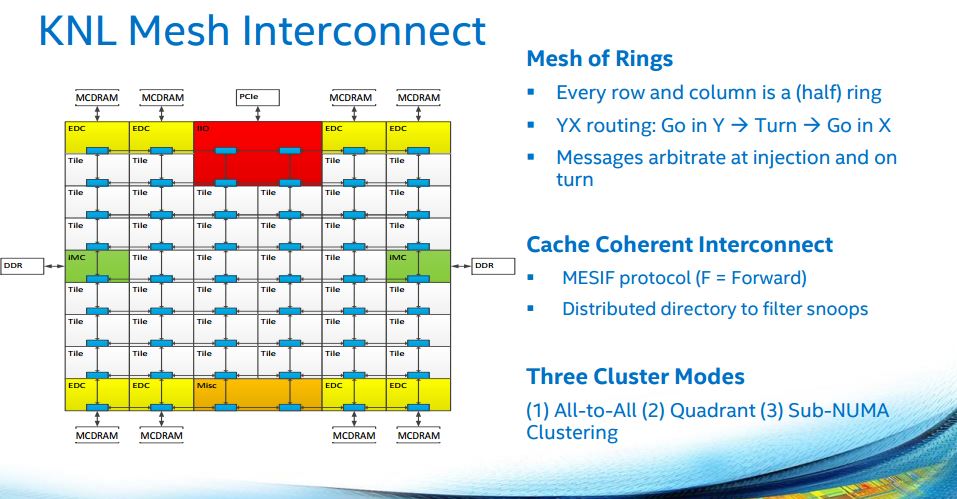
Of course, since this is a HPC product, we need modes to deal with this amount of resources. The lower performance/ easier to understand model is All-to-All.

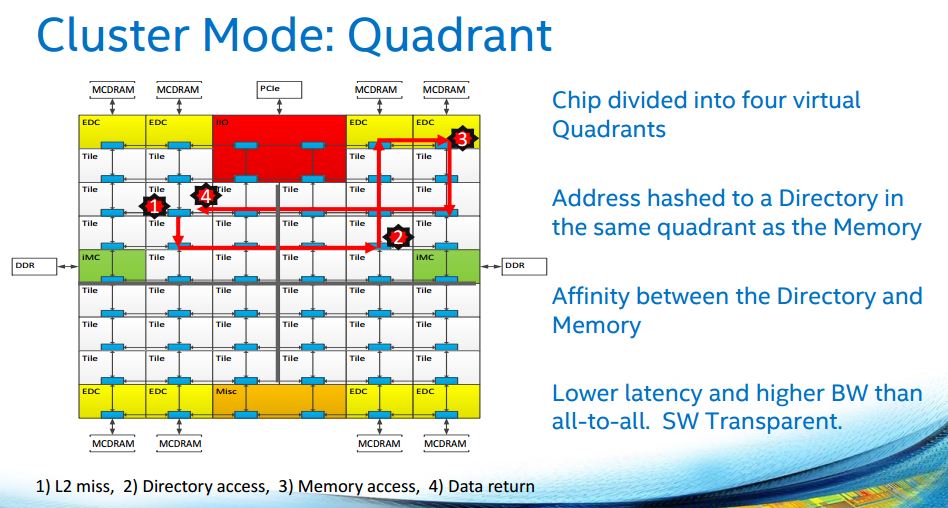
Quadrant keeps compute resources divided into four virtual quadrants.
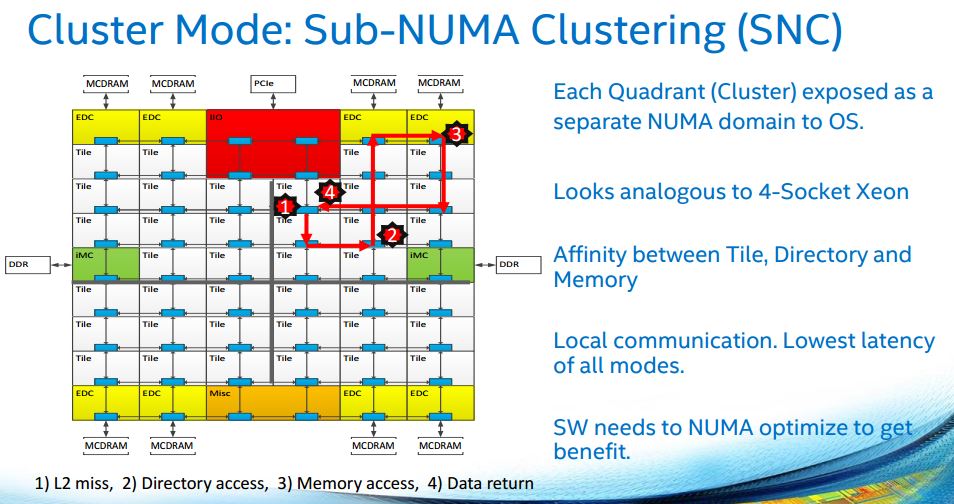
The final mode is Sub-NUMA Clustering. Lower latency but needs to be enabled in software meaning higher implementation complexity.
Omni-Path is the result of IP acquisitions Intel made in the interconnect space. More or less, this is Intel’s answer to Infiniband. We will have more on Omni-Path very soon. One Knights Landing variant will have on-package (not on-die) Omni-Path. The asterisks around PCIe mean that there is a seperate die using a very low power PCIe like signaling standard. Intel can use lower power PCIe because it is such a short distance and on a known short PCB run. This is the equivalent to if today NVIDIA had a GPU with on-board Mellanox 100Gb dual port Infiniband controller on the same package.

Of course, Omni-Path has some interesting advantages but the integration is awesome when one remembers KNL can have its own DDR4 and run independent of a host Xeon E5 PCIe bus. Essentially we have three flavors: PCIe card based KNL for legacy deployments/ upgrades. A KNL with Omni-Path if you buy into the Omni-Path ecosystem and future. This is a standalone node in a system essentially. Finally the KNL standalone (self boot) option with PCIe. Although Intel probably does not want to advertise it as such, this is the option if you want to add Mellanox Infiniband adapters or (maybe) some sort of Ethernet adapter as part of your fabric.

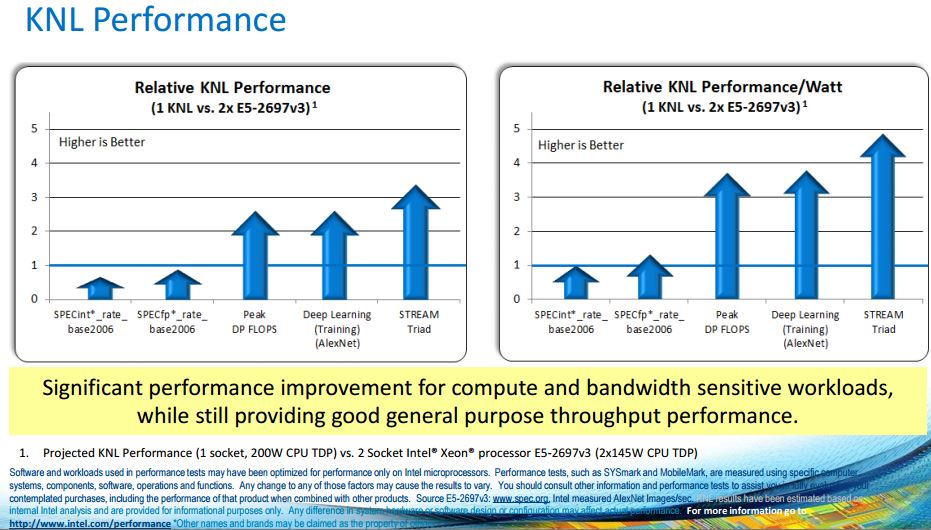
Last but not least performance. Intel is very careful how they show figures but essentially 200w TDP KNL Xeon Phi is going to be faster in most highly parallel/ floating point operations than dual Xeon E5 processors with a combined TDP of 290w. Better performance per watt is frankly expected, otherwise we would not see the near ubiquity of GPU/ MIC compute in HPC these days.
Conclusion
First question – will we be trying to run Linux-Bench on this? Of course! In fact, if Intel’s binary compatible claims are true, it should just work. If you have ever tried porting x86 code to CUDA or ARM, code portability from a Xeon E5 system to a Xeon Phi is a big deal. If code indeed runs and then the task is then optimizing, that means your effective utilization of the system from day 1 is much higher. On the other hand, GPU compute took off over the past few years. As a result, Intel needs a really solid product now to stop losses to GPU vendors. Knights Landing will be a step in the correct direction. Time will tell how well KNL hits the mark. The integration with Omni-Path is interesting as is our first glimpse of a 6 channel DDR4 memory interface we will likely see in the not-to-distant Xeon E5 family.



{kind=link}