
Recently we were in the process of decommissioning a few Hyper-V nodes we previously used to host STH VMs. When we were running this setup we were experiencing some significant intermittent latency on the CentOS VMs and the root cause was not readily apparent from MariaDB, nginx or the rest of the web stack. We ended up changing our replication network from a dedicated 1GbE NIC to a Mellanox ConnectX-3 VPI NIC in 40GbE mode. That change had a noted impact on the site’s performance significantly reducing service degradation during those periods.
Test setup
Each node was setup identically:
- CPU: Dual Intel Xeon E5-2670
(V1)
- RAM: 128GB DDR3 RDIMM (8x 16GB)
- SSDs: Intel 710 (OS) and Pliant / SanDisk LB406m
- HDs: Western Digital Red 4TB
- 1GbE Networking: Intel i350 based
- Other Networking: Mellanox ConnectX-3 VPI onboard (FDR IB/ 40GbE)
- OS: Microsoft Hyper-V Server 2012 R2
- Guest VMs: Ubuntu 13.10 64-bit – approximately 20 web hosting related VMs and related database VMs.


Overall the hypervisors were rarely over 30-50% CPU load due to extensive caching.

The impact of changing networks
Since our setup had each Hyper-V node replicating to the alternate node on a 10 min basis, there was significant replication traffic. We were using a 1GbE link as our replication and link to backup storage, leaving the other 1GbE link for non-storage tasks (e.g. serving web pages.)
We first changed the Mellanox ConnectX-3 VPI cards to Ethernet mode. From our guide on how to change Mellanox VPI cards to Ethernet mode in Windows this is extremely easy to do:
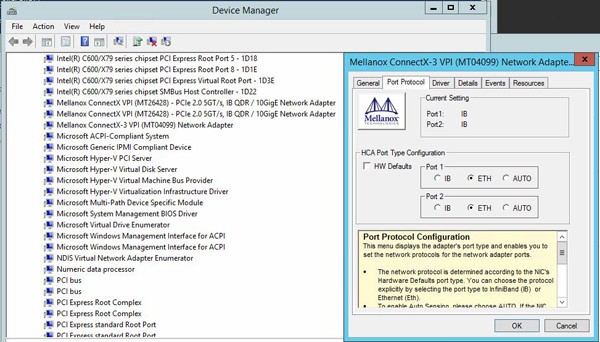
The next step was adding a DAC between the two nodes and setting relevant network information.
After some time, our average performance improved, significantly and we saw significantly less maximum latency. We took the time stamps of the main STH WordPress site’s response times against the start point of replication jobs. We then aligned the timings by a few seconds to try overlaying the two jobs in a scatter plot showing the by second average and maximum response times during the replication on that particular VM. To get a similar size replication, we used a checkpoint of the VM to let replication run once on 1GbE pre-switchover and one on 40GbE post switch over. This is not as scientific as reproducing in a lab environment, however, it is real production data. Here is what the data looked like when we did the analytics on the log files:
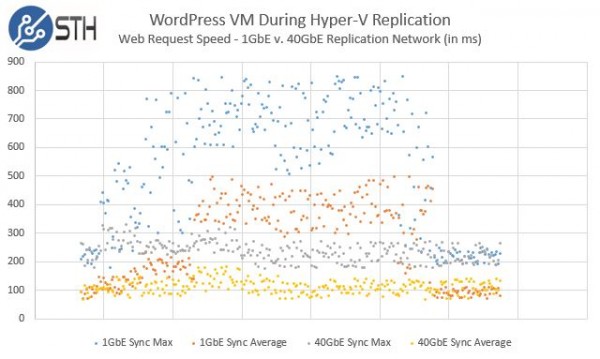
The time series plots were in seconds, and we did try to align the start of the latency spikes purposefully to make the data easy to interpret. The major impact here is clear. The maximum response times of our requests were much lower and there was a shorter period of disruption during the replication. The period of service degradation did not decrease by 97%+ as one might think adding a 40% faster pipe might do so there is certainly an impact of other components here, but it did move the periods of degradation down significantly.
Since then we have upgraded our back-end networks in our primary hosting datacenters to 10GbE and our new Sunnyvale test lab to 10GbE and 40GbE. We also changed to Linux with faster local storage, processors, memory and several other upgrades to the application layer. This was done in early 2014 and much (everything) has changed.



{kind=link}
Screw the M$ST HV I/O grinder. Cool little graph though esp since how much low end hosting goes over 1gb ethernet