
This week at FMS 2022, CXL 3.0 was announced. This new standard brings a number of very cool advancements to CXL. It also comes as OpenCAPI lost steam and had its IP brought into CXL. It is a bit awkward as I am writing this sitting next to someone at FMS with an OpenCAPI shirt. Still, this new CXL 3.0 version brings the next level of disaggregation capabilities and higher speeds for the ecosystem.
Compute Express Link CXL 3.0 is the Crazy Exciting Building Block for Disaggregation
The CXL Consortium showed the new features of CXL 3.0. We should quickly note that a device can support some CXL 3.0 features even if it is a CXL 2.0 device. We could see devices start to support some CXL 3.0 features before CXL 3.0 systems are fully out.
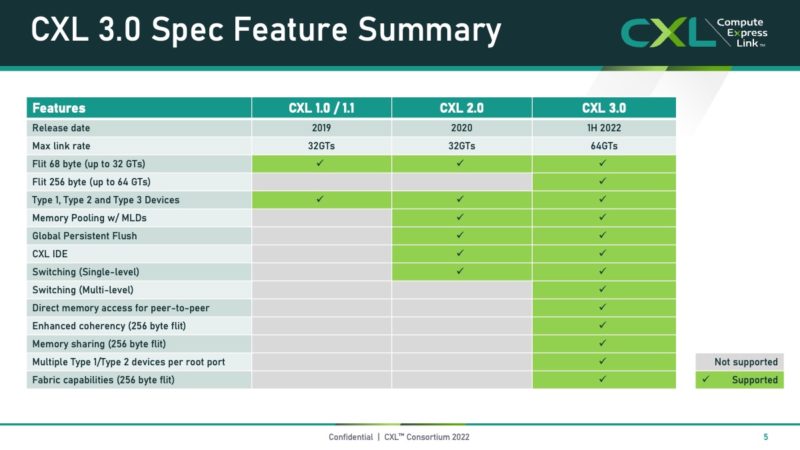
One of the biggest features of CXL 3.0 is the new CXL switch and fanout capability. CXL 2.0 introduced switching allowing multiple devices and hosts to be on a single level of CXL switches. CXL 3.0 allows one to have multiple layers of switches on the CXL topology. This allows for more devices but also allows for having a CXL switch in each EDSFF shelf plus a top-of-rack CXL switch that also connects hosts.
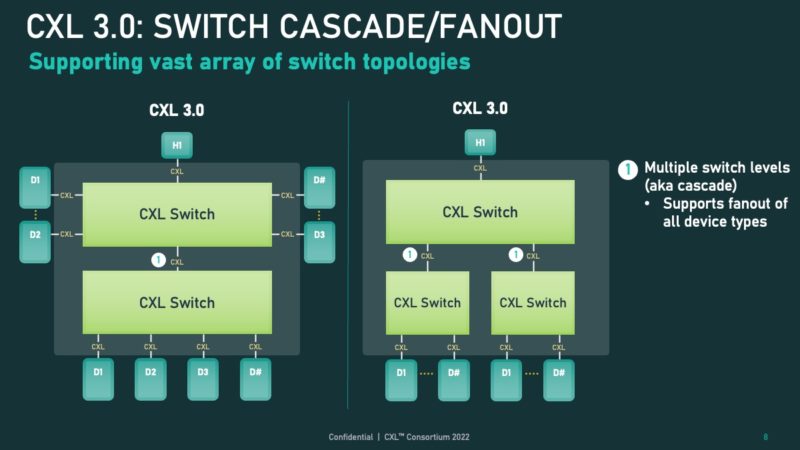
CXL also adds P2P device to device communications. P2P allows for devices to communicate directly without needing to communicate through a host. We already see this today when we do NVIDIA GPU server reviews, for example. P2P capable technologies are more efficient and thus perform better.
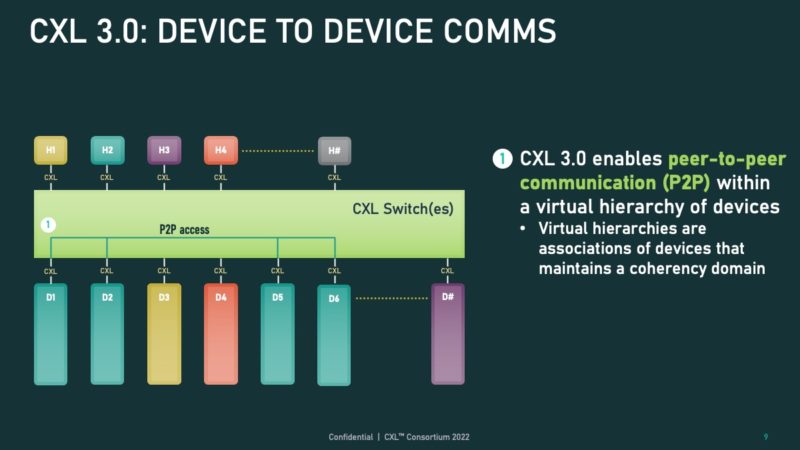
CXL 3.0 adds support for coherent memory sharing. This is a big deal as it allows systems to share memory not just in CXL 2.0 terms where a memory device can be partitioned off to multiple hosts/ accelerators. Instead, CXL allows memory to be shared by all of the hosts that are in the coherency domain. This leads to more efficient use of memory. For example, imagine a scenario where many hosts or accelerators are accessing the same data set. Sharing that memory coherently is a much more challenging problem but also drives efficiency.
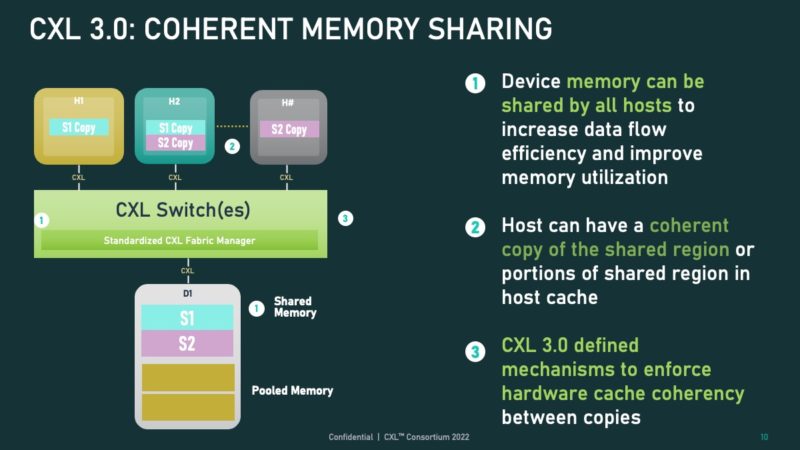
With CXL 3.0 one can also use pooling and sharing.
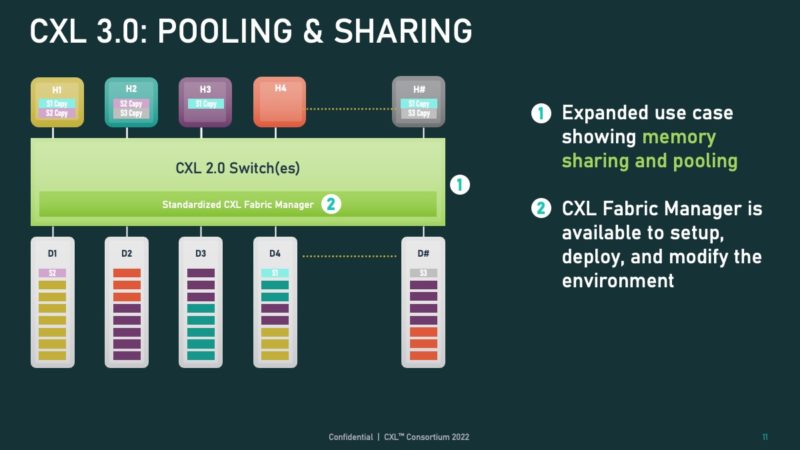
CXL 3.0 allows devices of different types and numbers to attach to a given root port on a host.

This is an extremely important slide. PCIe can be used with switches, but it is designed to use a tree architecture. CXL 3.0 allows the topology to be a fabric rather than a tree. With CXL 3.0, the fundamental topologies and use of the interconnect are what sets it apart from PCIe topologies we have seen thus far. There are several startups trying to put PCIe over a fabric to achieve the same thing, so this is what removes that need for an extra external step.
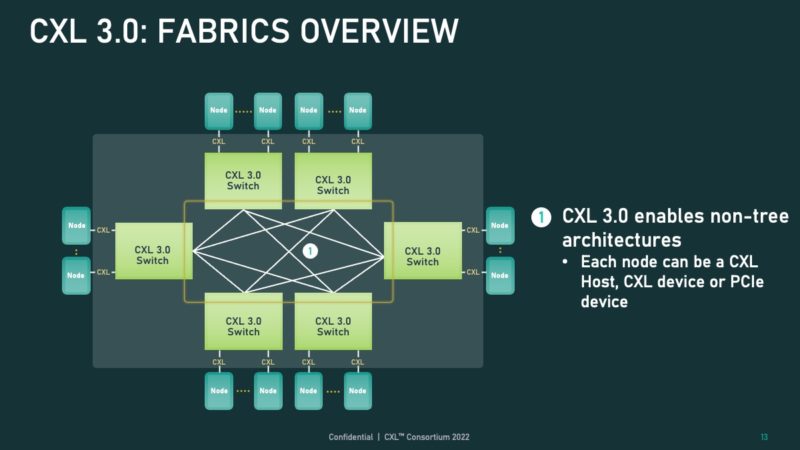
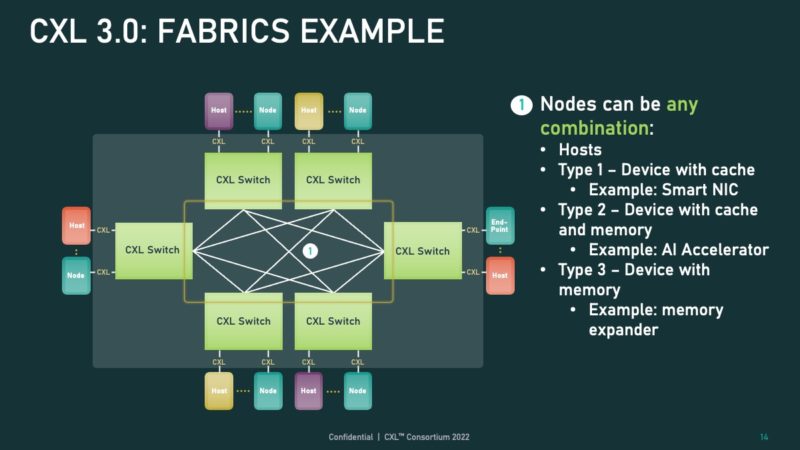
With CXL 3.0’s flexibility, that means the fabric can become a varied bunch of endpoints on the fabric.
The Global Fabric Attached Memory or GFAM may look innocuous on this slide, but it is a huge deal conceptually. The GFAM, in this case, is being used by CPUs, GPUs, NICs, and more. When we did our AMD Milan-X review, the “secret sauce” of the Milan-X CPU is that the large cache can remove enormous amounts of calls to main memory. That concept becomes very powerful when we then think about using servers without local memory, or very little, but then a GFAM with a memory shared across many hosts, albeit at a higher latency. The large local caches help hide that latency, while CXL 3.0 also allows a dataset to reside in a GFAM but then be worked on by many CPUs and accelerators.
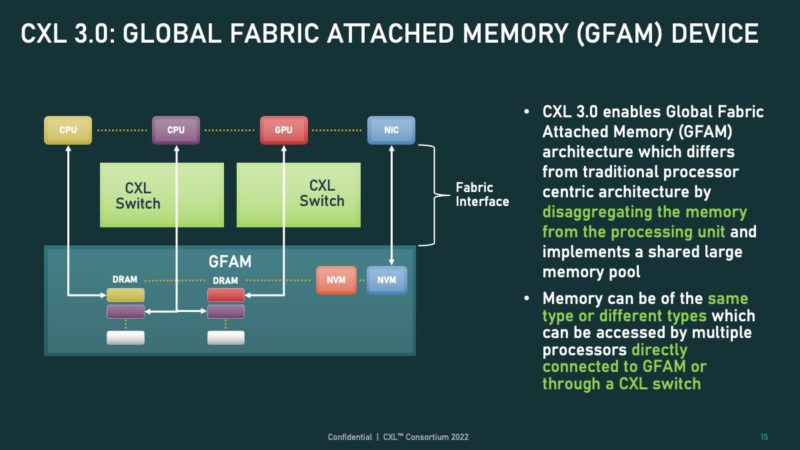
In addition, the GFAM can be of different memory types such as DRAM or even flash. Imagine future storage accelerators moving data from the coherent memory directly to flash and back without using the host CPU.
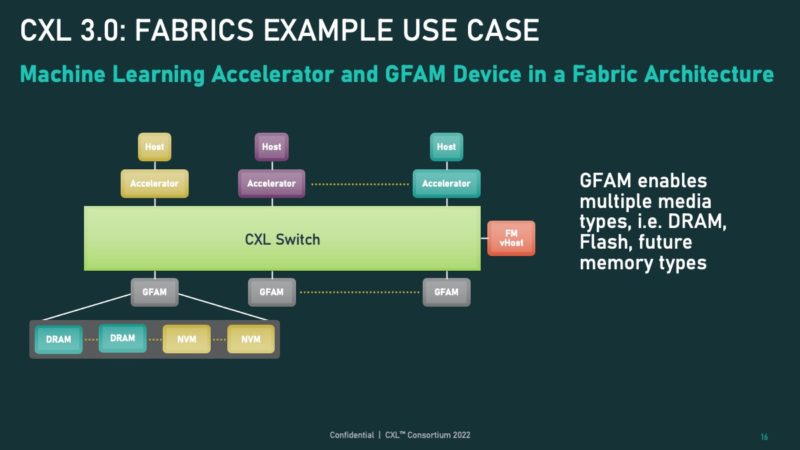
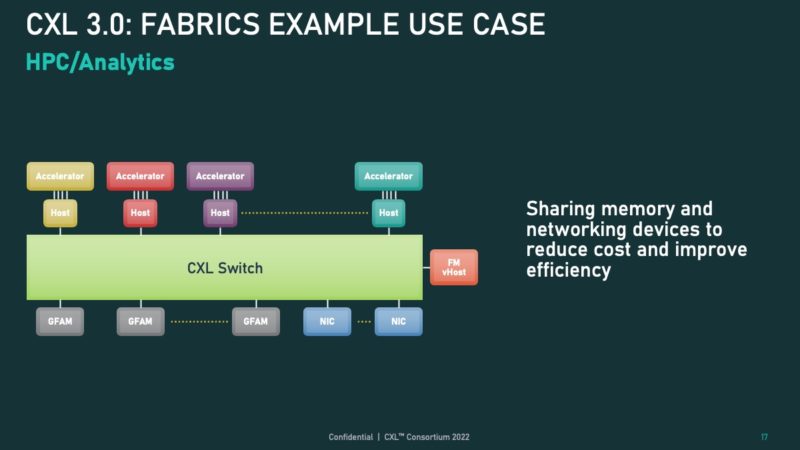
While at first these two examples may look very similar, there is an important difference that is not being highlighted. In the above, the accelerators are doing the communication directly on the CXL switch and CXL fabric. In the below example, the hosts are doing the communication on the CXL fabric.
The last example that the CXL folks sent us is perhaps the most profound. CXL 3.0 with the CXL fabric/ multi-level switching, shared memory, and more allows for the disaggregation of systems to a new degree. This is the generation that will start to allow real disaggregation or enabling the vision of being able to add shelves of compute, memory, and longer reach networking.
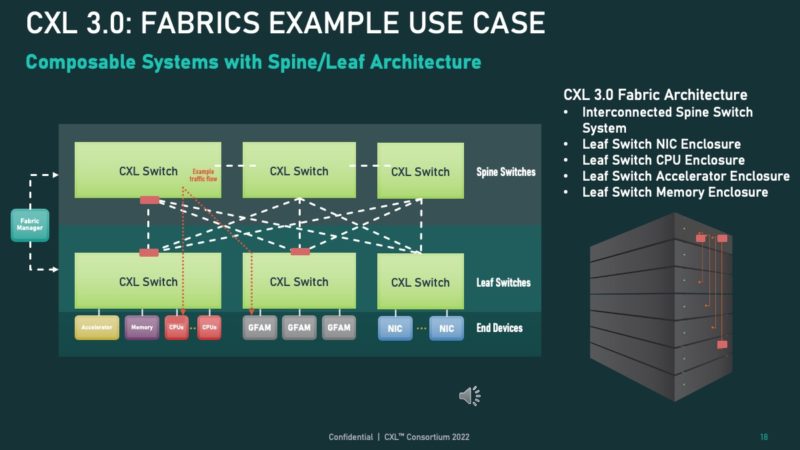
Local memory will still not go away entirely. CXL is lower bandwidth and higher latency with this approach than we typically see from local memory. What it instead allows is larger systems and more efficient/ flexible system design.
Final Words
We have come a long way since the days of the CXL Taco Primer and we will have an update on that one coming soon.
CXL 3.0 has many of the hyper-scalers very excited for potential cost savings and flexibility when it comes to creating future data center architectures. For smaller systems, this will likely have less of an impact. Still, from an industry perspective, CXL 3.0 arriving on PCIe Gen6 systems in the not-too-distant future is going to be a huge deal.


{kind=link}
There were a number of cxl 3.0 presentations on the Memverge yt channel recently. I recall one stating that pcie 6.0 not being required for cxl 3.0. Sorry, I don’t recall which of the presentations stated that, but there were several very interesting ones.
Comments are closed.