
Broadcom has a new 51.2T switch chip, with a twist. Instead of going for the maximum throughput for general purpose networking, the new Broadcom Tomahawk Ultra is designed to excel at small packet sizes and low latency as a replacement for technologies like InfiniBand and NVLink with Scale Up Ethernet (SUE.)
Broadcom Tomahawk Ultra Launch for Scale-up Ethernet
Some of the challenges with Ethernet Broadcom listed on a slide. The idea is that Ethernet was built to handle everything from low-speed LAN to the Internet, so it is not the optimized HPC or AI back-end.

Broadcom Tomahawk Ultra is a new switch silicon that is designed specifically to scale up clusters of high-performance computing and AI nodes.

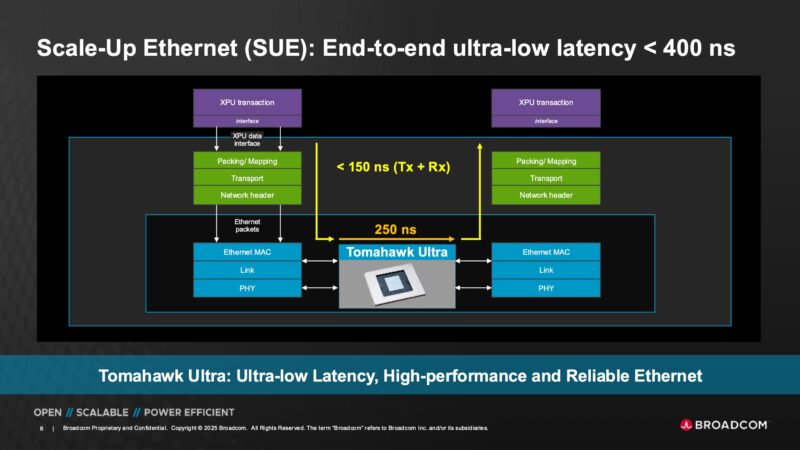
The latency is 250ns which is much lower than high throughput switches. The other important aspect is that the 51.2Tbps is at 64B packet sizes. Most traffic across Ethernet switches today involves larger packet sizes. So the design point of optimizing the throughput of a switch is at larger packet sizes for the general data center market. Tomahawk Ultra is instead designed to keep the latency down while saturating the 51.2T switch at 64B packet sizes.

Broadcom also told us they had to do some work to support different HPC topologies.
The idea behind this is to help Scale-Up Ethernet or SUE. XPU designers can optimize getting packets out of their XPUs and then have the Tomahawk Ultra pass messages very quickly to keep the overall latency very low.
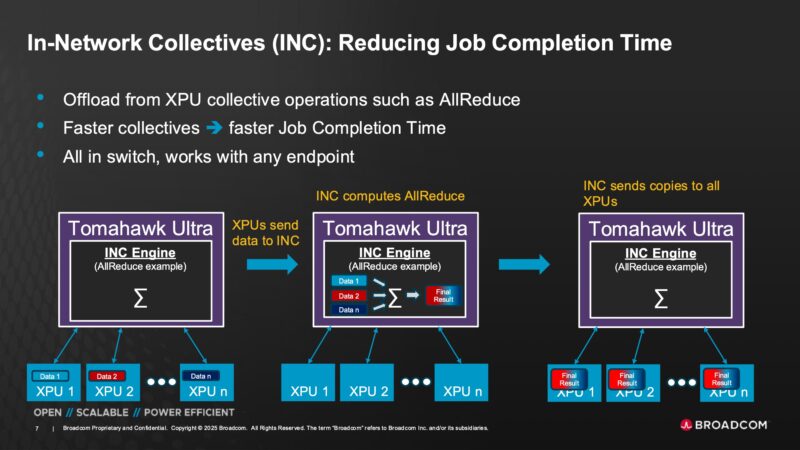
Broadcom is also adding in-network collectives (INC) which is something we have seen the Mellanox/ NVIDIA folks use in their switches to minimize the amount of traffic to the nodes and speed up job completion.
Part of what Broadcom is doing is optimizing the Ethernet header from 46B to 10B in order to decrease the overall header to payload ratio. Broadcom says this is still fully Ethernet compliant.

Another aspect is making the link layer lossless so that the higher layers of the stack do not need to do the error correction. Broadcom is using FEC to find errors and request retries at the link layer instead of handling it higher-up in the stack.

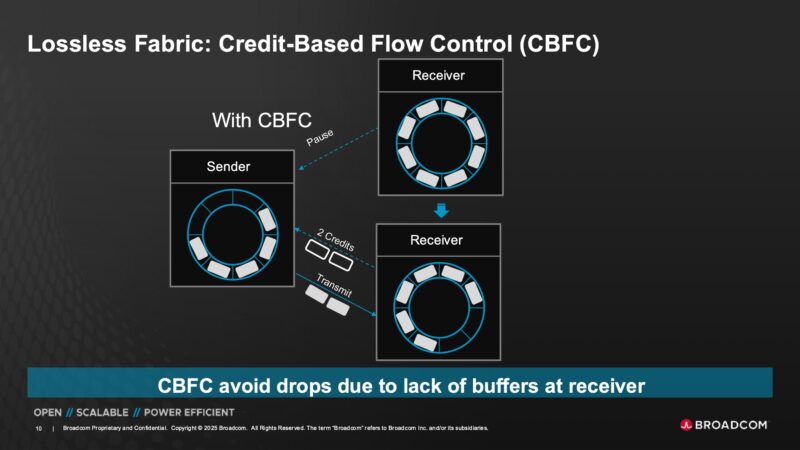
Another feature is the Credit-Based Flow Control or CBFC. Credits are sent to the sender from the receiver when the receiver has open buffer space. That way, the sender does not send packets to a receiver that does not have any room in its buffer to store the incoming packets.
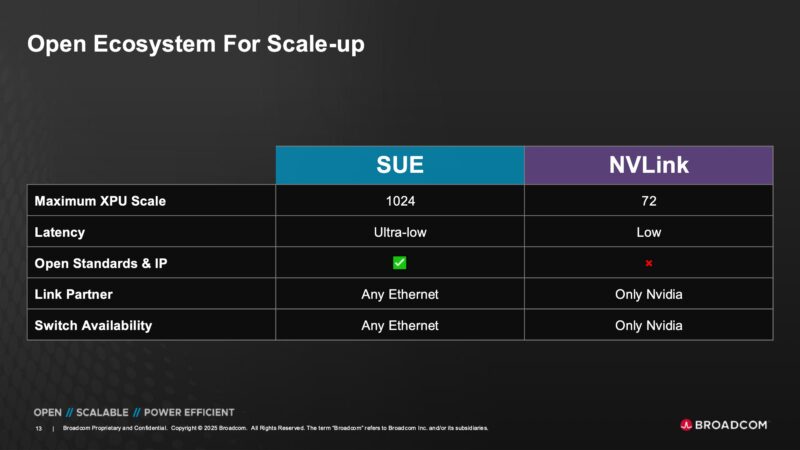
Broadcom is showing this as an alternative to NVIDIA NVLink with a larger scaling domain and being built on Ethernet.
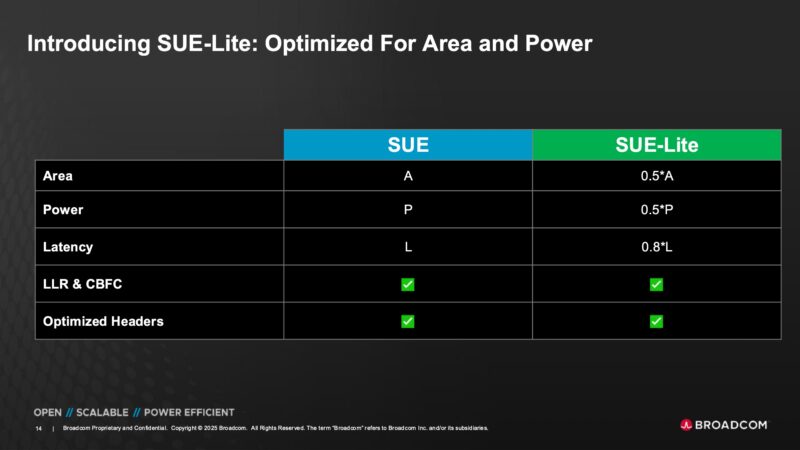
There is also another version of SUE called SUE-Lite that allows for further optimization.
The Broadcom Tomahawk Ultra is pin compatible with Tomahawk 5 and is shipping today alongside Tomahawk 6.

Tomahawk 6 is the 102.4T high-throughput switch. Tomahawk Ultra is designed more for these scale-up HPC and AI use cases.
Final Words
In this, Broadcom is not just going after NVIDIA NVLink and Quantum InfiniBand. It is also going after UALink as an example. One of Broadcom’s big points is that this is shipping today, while NVLink is proprietary and UALink switches are still some time off.

Hopefully we can find one of these switches in the not-too-distant future to show off.



{kind=link}
In response to the VMWare fiasco, some companies have been considering removing/reconsidering Broadcom networking gear on their purchasing lists.
How are in-network-collectives supposed to work without specific NIC support?
Sounds like it will be a short lived technology once ultra ethernet is there.
I’m kind of hating the “51.8 Tb switch” nomenclature, and wish we had standardized on lanes x speed instead. This is a 512-lane, 100G switch chip, while it looks like the Tomahawk 6 is available as either 1024x100G or 512x200G parts (BCM78910 vs BCM78914).
I’m also curious how big of a deal link-level retries are. That just feels weird from a network perspective. I’m assuming that it’s a bigger deal with RDMA, and reduces complexity in the RMDA stack while reducing long-tail latency? I’m having a hard time seeing how this really works in practice, though. LLR would kill TCP’s only real lever for estimating bandwidth, which means that you’ll either have to push LLR back all the way into host stacks, right?
Some articles about this chip describe it as UEC compatible, and not complete “SUE”; but ‘SUE-lite’.
Other articles compare the three, though that’s no less confusing.
“Broadcom Tomahawk Ultra Switch Targets AI Scale-Up with Lossless Ethernet”
“The New AI Networks | Ultra Ethernet UEC | UALink vs Broadcom Scale Up Ethernet SUE”
Wonder how TH6 compares with TH ultra in switch latency
@scott Ultra Ethernet is not designed for TCP, it has its own transport-layer protocol called UET (Ultra Ethernet Transport).
are there any actual switches shipping that are using the tomahawk ultra chip?