
ZFS has become increasingly popular in recent years. ZFS on Linux (ZoL) has pushed the envelope and exposed many newcomers to the ZFS fold. iXsystems has adopted the newer codebase, now called OpenZFS, into its codebase for TrueNAS CORE. The purpose of this article is to help those of you who have heard about ZFS but have not yet had the opportunity to research it.
Our hope is that we leave you with a better understanding of how and why it works the way it does. Knowledge is key to the decision-making process, and we feel that ZFS is something worth considering for most organizations.
What is ZFS?
ZFS is a filesystem, but unlike most other file systems it is also the logical volume manager or LVM. What that means is ZFS directly controls not only how the bits and blocks of your files are stored on your hard drives, but it also controls how your hard drives are logically arranged for the purposes of RAID and redundancy. ZFS is also classified as a copy-on-write or COW filesystem. This means that ZFS can do some cool things like snapshots that a normal filesystem like NTFS could not. A snapshot can be thought of like it sounds, a photograph of how something was at a point in time. How a COW filesystem works, however, has some important implications that we need to discuss.

Hard Drives work such that the pieces of your data are stored in Logical Block Addresses, or LBAs. ZFS is aware of what LBAs a specific file is stored in. Let us say we need to write a file that is big enough to fit into 3 blocks. We are going to store that file in LBA 1000, 1001, and 1002. This is considered a sequential write, as all of these blocks are stored directly next to each other. For spinning hard drives, this is ideal, as the write head does not have to move off of the track it is on.

Now, let us say we make a change to the file and the part that was stored at LBA 1001 needs to be modified. When we write that change, ZFS does not over-write the part of the file that was stored in 1001. Instead, it will write that block to LBA 2001. LBA 1001 will be kept as-is until the snapshot keeping it there expires. This allows us to have both the current version of the file, and the previous one, while only storing the difference. However, the next time we go to read the file back, the read head of our spinning hard drive needs to read LBA 1000, go to the track where LBA 2001 is stored, read that, and then go back to the track where LBA 1002 is stored. This phenomenon is called fragmentation.
A Primer on ZFS Pool Design
To make ZFS pools easier to understand, we are going to focus on using small storage containers as you may have around the house or shop. Before we continue, it is worth defining some terms. A VDEV, or virtual device, is a logical grouping of one or more storage devices. A pool is then a logically defined group built from 1 or more VDEVs. ZFS is very customizable, and therefore, there are many different types of configurations for VDEVs. You can think of the construction of a ZFS pool by visualizing the following graphic:

Starting from the smallest container size, we have our drives. We can see that in this visualization we have two drives in each larger container. These two larger containers are our VDEVs. The single largest container, then, is our pool. In this configuration, we would have each pair of drives in a mirror. This means that one drive can fail in either (or both!) VDEV and the pool would continue to function in a degraded state.

However, if 2 drives in a single VDEV, all of the data in our entire pool is lost. There is no redundancy of the pool itself, all redundancy in ZFS is in the VDEV layer. If one VDEV fails, there is not enough information to rebuild the missing data.

Next, we need to define what RAID-Z is and what the various levels of RAID-Z are. RAID-Z is a way of putting multiple drives together into a VDEV and storing parity, or fault tolerance. In ZFS, there is no dedicated “parity drive” like in Unraid, but it instead stores parity across all of the drives in the VDEV. The amount of parity that is spread across the drives determines the level of RAID-Z. It is in this way more similar to traditional hardware RAID.
What can make RAID-Z a better approach than a mirrored configuration is that it does not matter what drive fails in a RAID-Z. Each drive is an equal partner, whereas, in a mirrored configuration, each mirrored VDEV is a separate entity. This benefit of RAID-Z comes at the cost of performance, however, and a mirrored pool will almost always be faster than RAID Z.
RAID-Z is similar to a traditional RAID 5. In RAID-Z you have one drive worth of parity. In other words, if you lose one drive, your pool will continue to function. For RAID-Z you need a minimum of 3 drives per VDEV. You can have 3, 7, or even 12 drives in a RAID-Z VDEV. The more drives which you add, however, the longer it will take to resilver, or rebuild.
This increased time increases the risk of your data, as a second drive failure during this process would destroy your pool. ZFS will resilver while the data is still in use, it is a live recovery. The implication of this is that our disks are working harder than usual during this process, and this can increase the chances of a second drive failure. Your data is still accessible and in production, while it is reading all of the parity data from the existing members of your VDEV and then writing it to the new disk.

A RAID-Z2 VDEV is more akin to a RAID 6. In this configuration, 2 drives worth of parity is stored across all of your devices. You can lose up to two drives per VDEV and your pool will still function. Adding more parity drives increases calculations required which means you need more processing performance to operate the array.

Finally, a RAID-Z3 VDEV provides three drives worth of parity, so you can lose up to three drives per VDEV and your pool will still function. The more drives of parity you add, however, the slower your performance ends up being. You need a minimum of four but should use at least five drives to build a RAID-Z3 VDEV.
The Need for Speed
There are two ways in which we measure speed or fastness, IOPS, and Throughput. In RAIDZ, more drives will give you more throughput, or the actual read and write speed you see when transferring files. However, if you have ever tried to run multiple file copies in Windows simultaneously, you may have noticed the more you do, the slower it gets. It does not always get slower at a constant rate, the more you try to do disks will get exponentially slower. This is because your disk can only do so many Input/Output Operations per Second, or IOPS.
RAIDZ will scale in throughput with the more disks you add, but it does not scale with IOPS. What that generally means is, RAIDZ is not traditionally the best choice for I/O intensive workloads, as the amount of IOPS is roughly limited to the slowest member of our VDEV if we exclude all of the caching ZFS has. Virtualization, as we are discussing here, is highly dependent on I/O.
Earlier, we discussed that ZFS is a COW filesystem, and because of that it suffers from data fragmentation. There are direct performance implications that stem from that fact. The more “full” your pool is, the slower it will ultimately get. Write speeds in ZFS are directly tied to the amount of adjacent free blocks there are to write to. As your pool fills up, and as data fragments, there are fewer and fewer blocks that are directly adjacent to one another. A single large file may span blocks scattered all over the surface of your hard drive. Even though you would expect that file to be a sequential write, it no longer can be if your drive is full.
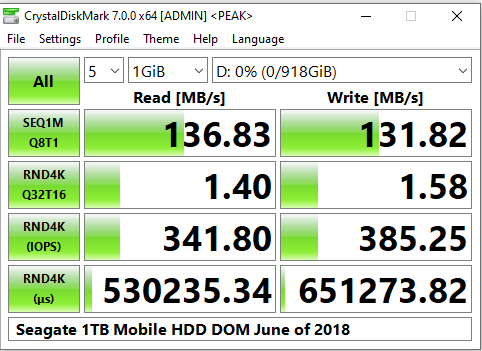
In the above graphic, we can see a Seagate 1TB mobile drive that I tested in CrystalDiskMark. It can do about 130 MB/s of sequential read and writes. We can also see that when we start doing random 4k I/O, the speed falls about 100x. This is meant to illustrate the performance impact of data fragmentation. Additionally, we can see that the latency for these lookups can take about half of a second, and we are limited to about 350 IOPS. In order to be fast, virtualization workloads on traditional hard drives need to have many disks in order to compensate for this slowness. It would not be uncommon to see a pool constructed of 10 or more VDEVs of mirrored drives.
Additionally, there is some wisdom we can borrow from the ZFS community. As your pool fills up, and sequential writes become increasingly difficult to accomplish due to fragmentation, it will slow down in a non-linear way. As a general rule of thumb, at about 50% capacity your pool will be noticeably slower than it was when it was 10% capacity. At about 80%-96% capacity, your pool starts to become very slow, and ZFS will actually change its write algorithm to ensure data integrity, further slowing you down.
This is where SSDs come in. They radically change the game because they work very differently at the physical layer. They do not have read and write heads that are flying around a spinning disk back and forth trying to find your data. With the physical limitations of disk-based drives out of the way, SSDs can read and write non-sequential data much faster. They do not suffer the penalties of these rules nearly as severely, fragmentation does not hurt their performance to the same degree.

A Samsung 970 EVO Plus SSD
Hard drives have increased in capacity by leaps-and-bounds over the past couple of decades. We have seen hard drives grow from a single gigabyte in capacity and just last year Western Digital announced that 18 and 20 terabyte drives are coming in 2020. What has not changed, is their ability to do I/O. Hard drives of old and new alike are still bound by physical limitations. Even those new monsters will only really be able to do about 400 or so random IOPS, only about four times what they once did all those years ago. The Samsung 970 EVO plus pictured above, however, can do over 14,000.
If we receive enough feedback, in another piece we can talk about further tuning performance in ZFS.
Blocks and Sectors
Finally, we need to briefly explore a few additional topics about our underlying storage configuration. In a Windows computer, if you plug in a new hard drive or flash drive you need to format it and assign it a drive letter before you can use it. Similarly, when you finish creating your Pool in ZFS, you need to create a dataset in order to actually start using it. When you format your flash drive, Windows asks you to specify an Allocation Unit Size.
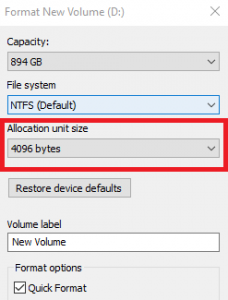
In ZFS the term for this is called the Record Size. This value represents the maximum size of a block. A block assembles the pieces of your data into logical groupings. In TrueNAS Core, you can define the record size on the pool level. Its child datasets will inherit the record size you set in the Pool, or you can also specify a different record size when you create it. Additionally, you can modify the record size at any point. However, doing so will only affect new data as it is written to your pool and not any existing data.
TrueNAS Core creates datasets with 128k record sizes by default. This is meant to be a well-rounded decision. Depending on your workflow, you may wish to increase or decrease this value. If you were running a database server, as an example, it would make more sense to set the value to a smaller number. A 4k record size in that example would allow each transaction in the database to be written directly to disk, rather than waiting to fill the entire 128k record in the default configuration. As a general rule of thumb, Smaller record sizes offer lower latency, whereas larger ones offer higher overall throughput.
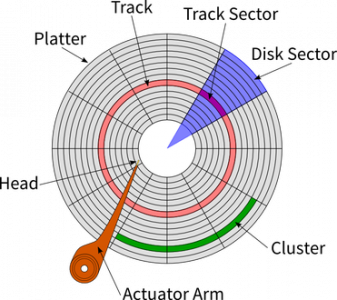
A 128k recordsize spans 32 sectors on a 4k native hard drive. A sector is the lowest-level piece of the storage puzzle. It is the closest thing to the physical embodiment of your data inside of the storage medium that we are going to go over.
ZFS needs to be aware of this information in order to make intelligent decisions on how to read and write data to the disks. You can tell it what the sector size is by providing the ashift value. TrueNAS Core does a pretty good job of doing this for you automatically. Most modern disks have a 4k sector size. For these drives, ZFS needs to have an ashift value of 12. For older 512b drives, you would use an ashift value of 9.
For some SSDs, the story muddies. While they report to the OS that they are 4k drives, in reality, they function internally as 8k drives. These devices would require you to manually assign the ashift value, and you should use 13. If you are unsure, it is better to be too high than to be too low. Too small of an ashift value will cripple performance.
What is an ARC?
The ZFS Adaptive Replacement Cache, or ARC, is an algorithm that caches your files in system memory. This type of cache is a read cache and has no direct impact on write performance. In a traditional file system, an LRU or Least Recently Used cache is used. The way a cache works is if you open a file on your computer it will then put that file in the cache. If you then close and reopen it, the file will load from the cache rather than your hard drive.
An LRU cache will evict the least recently used items from the cache first. Let us say the file we are talking about is an Excel spreadsheet. Assume you have opened that file and got it in your cache. This Excel file is something you access frequently throughout your workday. You make your changes, then close it to go work on a PowerPoint and write some emails, the LRU cache will potentially run out of space and evict the Excel file from the cache. So when you open it again later in your day, rather than reading it from the cache, it has to load it from disk. Caches are usually much larger than Office documents, but we are using this as a conceptual example.

The ARC differs from this in that it takes the recent eviction history into account. Each time a file is evicted from the ARC the occurrence is logged. The algorithm will give weight to these logs, and files which have been evicted before but in cache again with a lower priority for them to be evicted again.
The level 2 ARC, or L2ARC is an extension of the ZFS ARC. If a file is evicted from the ARC, it is moved to the L2ARC rather than just being removed. The L2ARC resides on a disk (or disks), rather than in system memory. Since RAM is expensive, this feature is a useful way to expand your caching capabilities. With the advent of NVMe and Optane, relatively high speed and large caching can be achieved. It comes with a cost, however. Since the ARC will need to know that these files are stored in the L2ARC, it has to store that information in RAM.
According to this Reddit post by an Oracle employee, the formula for calculating the ARC header mappings is:
(L2ARC size in bytes) / (ZFS recordsize in bytes) * 70 bytes = ARC header size in bytes
So let us make some sense of that for our purposes. We will use the TrueNAS default of 128Kb blocks and a 256GB NVME SSD as an L2ARC.
256,000,000,000 / 128,000 * 70 = 140,000,000 bytes
This would be a pretty common configuration choice for a lower-end VM storage box. If you only had 16GB or of RAM in your system, all of your ARC space would be wasted with L2ARC mappings and you would only have 2GB of the entire rest of your system. For a 256GB L2ARC you would want a minimum of 32GB of ram. 64GB would be recommended.
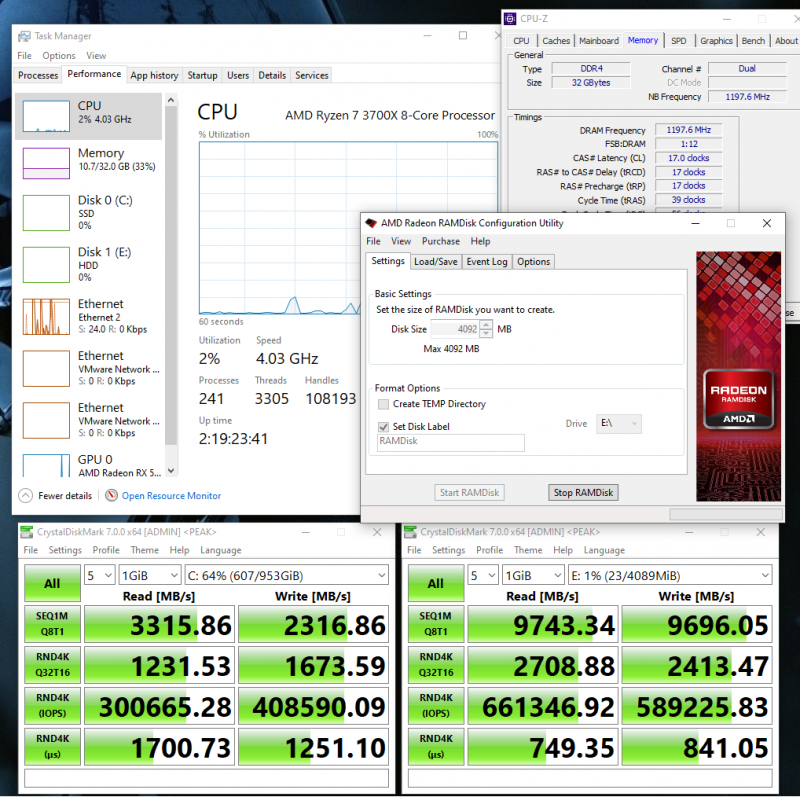
We want to keep data cached in both the ARC and the L2ARC, it is a tiered approach. The above comparison attempts to illustrate this fact. Even using a software RAMDisk driver, my PC’s relatively slow DDR4 2400 is about 3x faster than my 1TB Samsung PM981. The old wisdom was always to have no more than about 5x the L2ARC than your RAM.
The ultimate goal here is to prevent our pool from having to do as many reads as we can. While the ARC does not directly cache writes, it can speed up your write performance by freeing your drives from having to constantly read from disk.
What is the ZIL and what is a SLOG?
Before we can explain what the ZIL is or what a SLOG does, we must first explain what and how data is written to a ZFS pool. When a write to disk occurs, it must first pass through system memory where a transaction group or TXG is created. ZFS will then asynchronously commit this data to the pool, meaning there are no checks/ balances to ensure that the data got to the pool successfully. In the event of a crash or a power failure, corruption will have occurred and you will have lost the data being written.
ZFS can also write data blocks synchronously. You can force ZFS to do this by setting the “sync=always” flag in your pool. In addition to the above, a sync write commits the writes to the ZIL, or ZFS Intent Log, in parallel with system memory. If the normal TXG is written to your pool successfully, the data in the ZIL will be erased. If the system crashes or its power interrupted, the data will remain in the ZIL. Since system memory is volatile, and our ZIL is not, this can be considered an insurance policy for our write commits. The speed of your writes, however, is now tied to the speed of your ZIL.
By default, the ZIL lives in your pool, but in a logically separate place. It is only ever read from in one scenario. If there was a crash or a power failure. Every time your system is restarted it has to re-import your ZFS pool before proceeding. When the pool is reimported, ZFS will look to see if there was any remaining data written to the ZIL. If there was, that means there were writes that had not yet been committed to disk. It will then read that data and commit it as a new TXG to your pool.
What this all means is that with a sync write, your data is written to the disks in your pool twice. This is called a write amplification, and it will slow any write commits to your pool to a crawl. Sync writes have a high cost, cutting your write performance in half or more.

This is where the SLOG comes in, a SLOG is a separate piece of hardware that acts as a dedicated place for the ZIL to live. Having separate hardware prevents the write amplification effect on your pool. It also allows you to put the ZIL on a much faster device. That is important because your writes will still be limited by the speed of your SLOG. These transactions are especially sensitive to disk latency, which is more important than throughput or IOPS for a SLOG device. It is for that reason that we recommend Intel Optane for use when sync writes are a requirement.
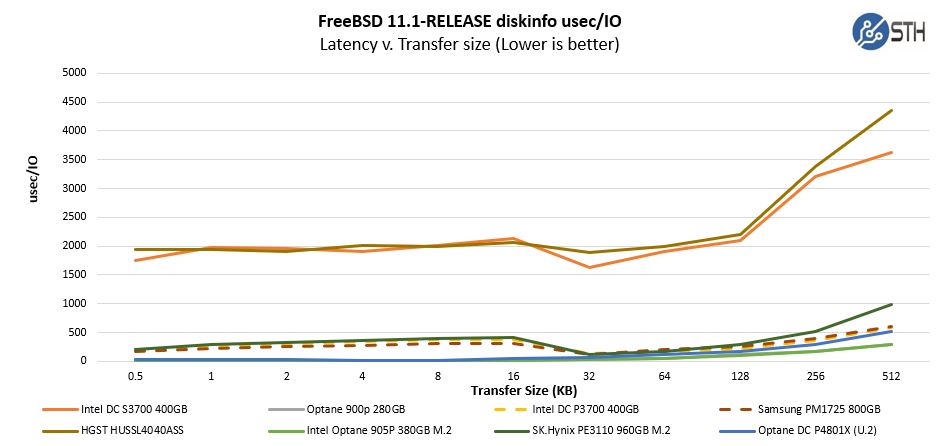
It is worth noting that the ZIL is not a ZFS write cache! Your pool’s write speed will always be faster with asynchronous writes, even if you are using a SLOG when using sync writes. If you feel your data is sensitive enough to require sync writes, buy a SLOG.
Final Words
We have spent some time in this article discussing the key concepts surrounding ZFS. We hope that we have helped provide to provide the necessary knowledge and references to get you started in the world of ZFS. When you go to build a lab, or when you go out to bid for a new storage solution, the Open Source is a tremendous resource that should be considered.
We have not covered everything in the piece. Special Allocation Classes are an OpenZFS feature, and they allow you to accelerate metadata on your spinning drives with flash storage. Additionally, you can use them to get a better-performing deduplication. This is still a new feature in OpenZFS we have not yet tested or vetted for their viability or value.
Additionally, ZFS does on-the-fly compression, has native encryption support, and a whole-host of new features are actively being developed. We hope to follow this introduction to ZFS piece up with more content in the future around ZFS as new things come about.
If you want to put this into action in a lab, check out our series starting with Building a Lab Part 1 Planning with TrueNAS and VMWare ESXi.



{kind=link}
Unless you have a 25.6 TB cache drive, you have two extra zeros in your L2ARC calculation ?
256,000,000,000÷128,000×70=140,000,000 bytes = 0.14 GB
I’m a bit upset you used a picture of an SMR Red “NAS” drive on an article about ZFS which they are unsafe to use with.
A picture of a WD40EFAX prominently placed in an article introducing ZFS.
Checks calender…
Yup, it’s April Fools’ day, folks.
Hi
Nice primer for people.
I also noticed the issue in calculations in the L2ARC section.
The other correction I’d like to suggest is one around the 80% full change of algorithm. It’s been 96% for some time now and isn’t immutable if free space returns to a sane percentage.
“The metaslab allocator will allocate blocks on a first-fit basis when a metaslab has more than or equal to 4 percent free space and a best-fit basis when a metaslab has less than 4 percent free space. The former is much faster than the latter, but it is not possible to tell when this behavior occurs from the pool’s free space. However, the command zdb -mmm $POOLNAME will provide this information.”
Thanks was a good read
The calculation mistake scared me too! And another vote for replacing the picture of the EFAX drive with one that people should actually use.
Guys on the picture, it was supposed to have a link in the caption to the CMR/ SMR piece but for some reason this article, when we split it, lost that caption link. I swapped the photo to a 10TB WD Red Pro drive and the link looks like it is there now.
This was originally part of Building a Lab Part 3 but then it was split out.
Excellent article! I have been using a ZFS filesystem (on a SmartOS server) as my NAS for about 6 years now. It has been perfectly reliable through many power failures and a disk failure. And I have had to pull files from snapshots on many occassions to address user errors.
You mention the performance degradation as the disk fills and files get fragmented. Is there a defragment command to address that?
You don’t touch on one thing I have heard is a significant problem for ZFS pools: You can’t easily add disks to an existing ZPOOL to expand capacity. To me that’s a significant drawback to using a ZFS RAIDZ pool as a NFS. But maybe my knowledge is outdated.
@Lee,
you can relatively easily add disks to an existing pool. Create a new vdev with the new disks, and add this vdev to the existing pool. Perhaps you got confused about vdev vs. pool, as it is not possible to add disks to an existing vdev. (The only way to expand the capacity of an existing vdev itself is to swap all the drives in a vdev with drives of larger capacity; which, while possible, is most probably not the best way to expand the capacity of your pools.)
This was great! Definitely interested in a follow-up on zfs tuning.
I would love to see the followup article on performance tuning ZFS if you are willing to make it as detailed as this one was. Great primer article. Thanks.
Thanks, Patrick, that is an informative article.
What are some Con’s of ZFS, does it do trim, defragmentation? I look forward to your tuning article. Another informative great article.
Thanks;
Many 10s of years ago I had a ICL 1900 in the back garden (don’t ask)
running George 3 (another COW filesystem with versioning). We had
several ICL EDS 60 disks, each disk had 11 platters with 20 “sides” of
usable rust. These disks were, by modern standards: very small, slow
and somewhat unreliable.
In those days moving the heads was something to be done as
infrequently as possible, so we did not talk so much
about “sectors” but instead in “cylinders” – all the heads in one
track position multiplied by the no of sectors.
Please tell me that this concept still applies when one talks about a
“track”, and that I am just an old fool that needs to get back to
writing the program I was avoiding by reading your excellent article.
Thank you.
NTFS do have snapshots since Windows 2003.
https://en.wikipedia.org/wiki/NTFS#Volume_Shadow_Copy
https://en.wikipedia.org/wiki/Shadow_Copy
Dork. I learnt to programme on a 1900 with George 3. The PL was Fortran.
Dirk. I learned to programme on a 1900 with George 3. The PL was Fortran.
Nice informative article on ZFS and TrueNAS! Really helpful information to help better understand gay anal sex in the bed.
ZFS is not really a COW, but a ROW. It does not Copy on Write, it redirects on write. This is less IOs since a COW must read the original data and write it somewhere else, ZFS redirects the write and leaves the original as is. And that is why it does not slow down with lots of snapshots. LVM is a COW and the more snapshots the more IOs needed and the slower it gets.
To the end user, a ROW and COW look similar and hence we see ZFS called a COW all the time.
Comments are closed.