
The third and final machine learning presentation before the afternoon break comes from Huawei. Unlike many of the other ML vendors who are here to pitch products, Huawei’s presentation is more focused on fundamental technology. In this case, how to use efficiently use meshes to interconnect the chips within large AI systems.
Eyeing so-called SuperNodes – singular supercomputing clusters with upwards of a million chips – Huawei is showing off its United Bus mesh (UB-mesh) technology. The challenge at hand is how to scale up networking to offer low-latency connections between all the chips in a SuperNode without spending more on network gear than the accelerator chips themselves, and how to do all of this while preserving the reliability of the interconnect.
Atypically for Hot Chips, this is a virtual talk. Dr. Liao is delivering it from China.

This is more of an architecture/CS-focused talk than an engineering talk. Huawei wants a mesh that can scale up to perhaps a million processors. As a result, a SuperNode can be as large as an entire data center.
The large scale of the system means that it’s not just about connecting GPUs, but memory pools, SSDs, NICs, and switches are all part of the node.

Unifying Common Bus and Network Protocols
Huawei is advocating for a unified bus, with a single protocol instead of the alphabet soup of technology-specific protocols. A common protocol means that any port can connect to any port, and without protocol conversion. This keeps latency down by eliminating situations that would otherwise add latency.
A unified protocol would also allow for a simplified schema.
Even with these goals, UB can still be run over Ethernet.
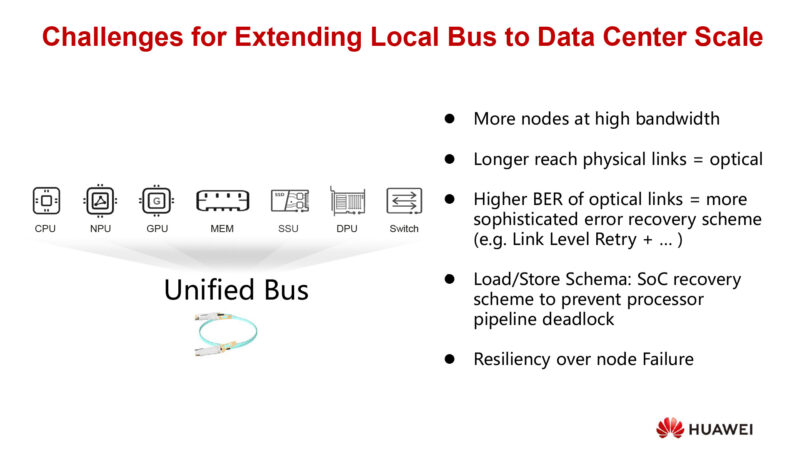
But reaching those goals means overcoming several challenges. Of particular concern is that the physical links are longer – the network spans a whole data center – which means having to go optical. And optical networking has 2-3 orders of magnitude higher error rates. Which means better error recovery tech is needed to be layered on top.
And the very large scale means that the whole node needs to be resilient against node failures. At this scale it’s not if an individual server fails, it’s when.

How do you achieve a physical network with 100x more bandwidth, but without 100x the cost?
Huawei believes it requires a new topology. Arguably a hybrid topology that mixes the strengths of multiple styles at different levels.
One possibility Huawei is looking at three technologies, with CLOS at the highest level, n-dimensional mesh below that – suitable for a single rack up to tens of nodes – and then an n-dimensional spare mesh at a lower cost option.
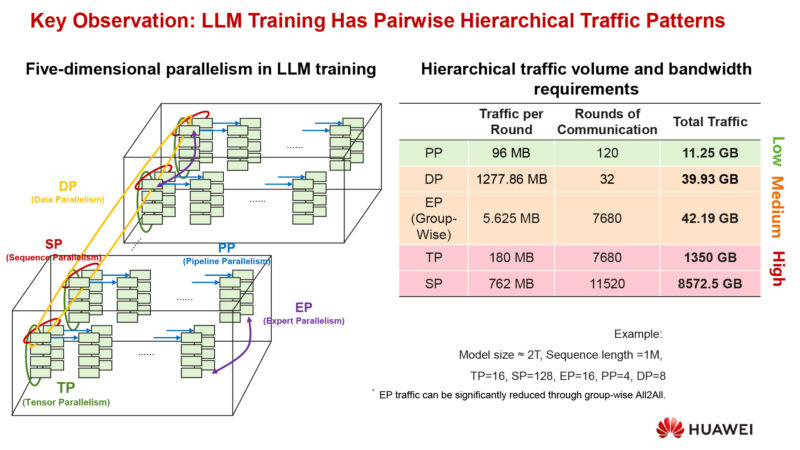
LLM training reaches five dimensional parallelism.
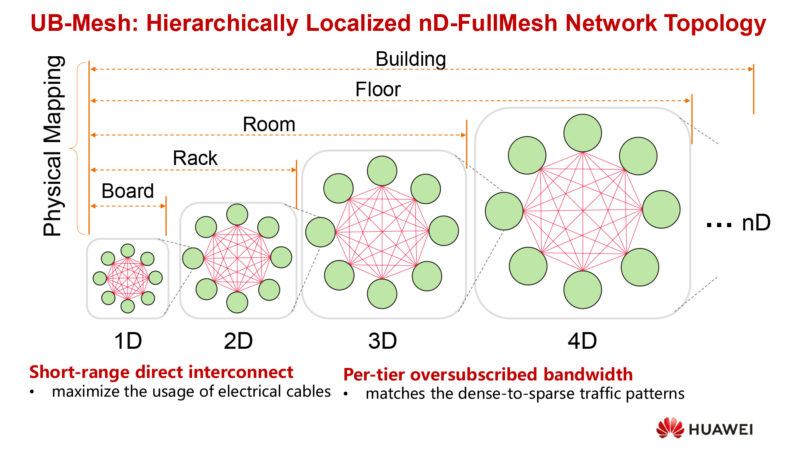
Here’s a conceptual diagram of a UB-mesh topology. Realized as multiple dimensions. Each dimension has full connectivity from any node to any node. And then higher dimensions connect the lower dimensions.
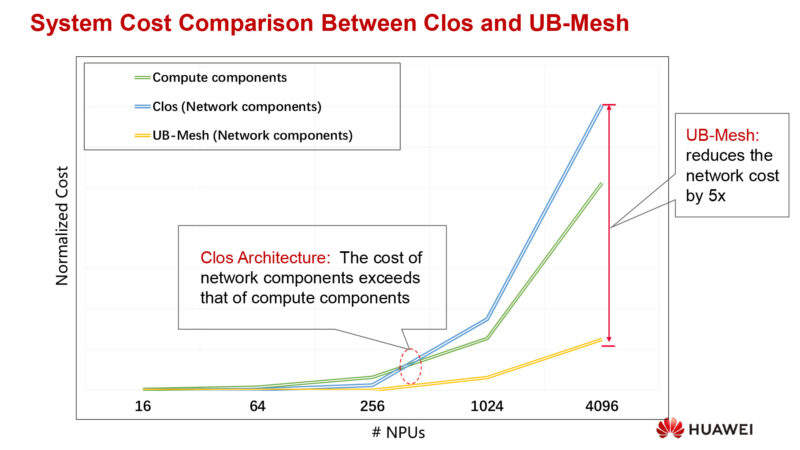
All of this needs to be balanced with costs. You don’t want the networking gear to cost more than the compute gear that does the actual work.
As the network scale increases, a traditional network would see a super-linear increase in costs. But UB-mesh is sub-linear, only adding modest costs when the number of compute nodes increases significantly.
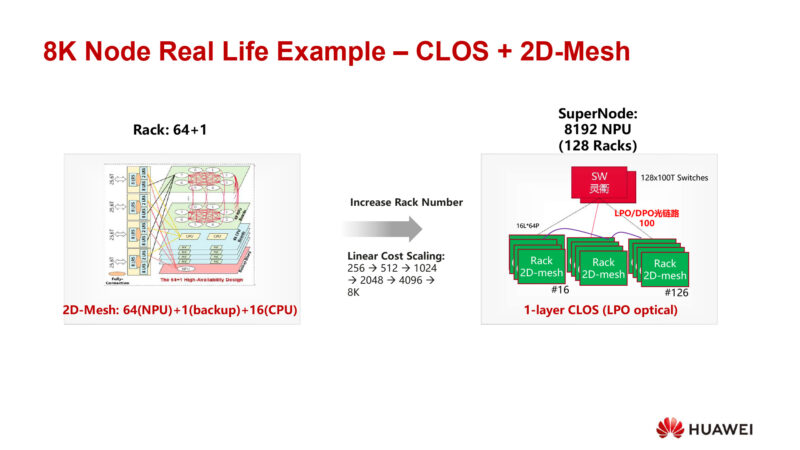
And here is a real-life example. A 64 node systems with a CLOS + 2D mesh setup.
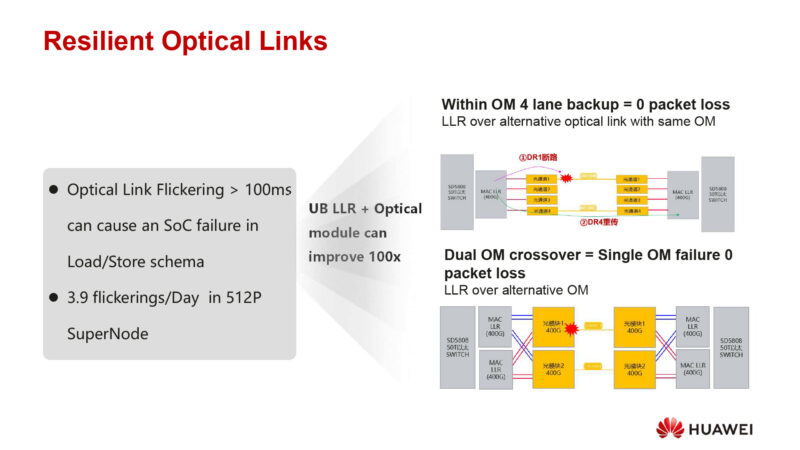
But how to make the optical links reliable enough for a SuperNode’s needs?
Need to increase the resiliency of the optical link itself. Starting with supporting link level retries over alternative optical links on the same module in order to ensure it doesn’t go back out the same problematic path.
A second scheme for most serious failures is to connect the MACs to multiple optical modules in a crossover fashion, such that a good optical module is still available if the other module fails.
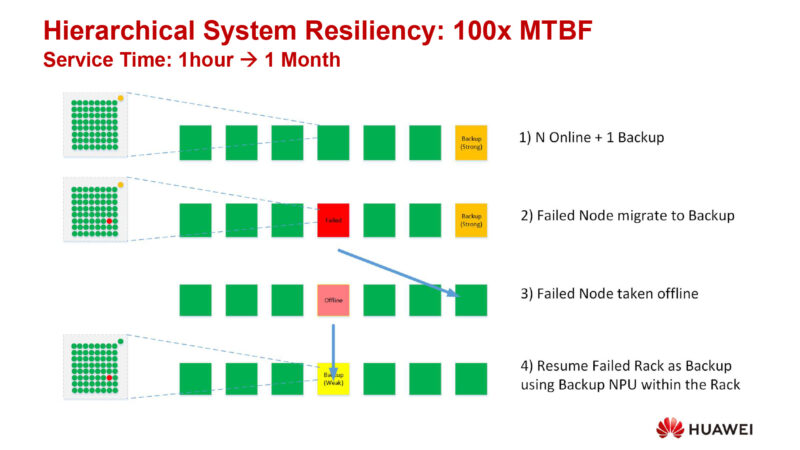
Huawei is targeting a 100x increase in the MBTF. One way to do that is to provide hot spare backup racks, to take over if a node fails. The failed rack is then fixed, and returned to the node as the new hot spare. And if an extra chip is in the rack itself, then the rack has some resiliency of its own; in this case, it can be returned as a weak hot spare.

In summary, by moving to a unified protocol and then deploying multiple improvements to the network topology and redundancy in hardware, UB-mesh would make it possible to build and deploy reliable data center scale SuperNodes. 1GWatt AI datacenters, anyone?



{kind=link}
“And optical networking has 2-3 orders of magnitude higher error rates.”
Hi, would you be able to provide a source or reference for this? I don’t doubt this at all, but would really like a reference I can give when I use this statement in the future.
Thanks.