
Today, the industry association, SNIA, is releasing a Storage.AI project that looks to reframe the AI storage discussion. Storage is becoming a bigger topic in AI clusters since keeping GPUs fed and working can have a multiple-billion-dollar ROI.
Storage.AI Project by SNIA Looks to Re-frame AI Storage Discussion
The current state is that most AI cluster shared storage is connected through the front-end north-south network. There are then faster networks with higher bandwidth to the nodes going to the xPUs for both scale-up and scale-out segments. In NVIDIA parlance, this would be scale-up NVLink, and scale-out would be Ethernet or InfiniBand.
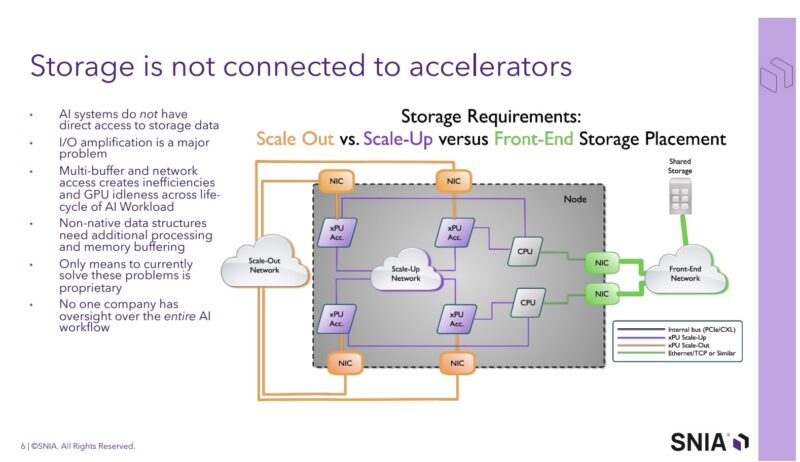
Part of the idea behind this is to put storage onto the scale out network so that it can take advantage of higher performance pathways to the GPUs. Today, pre-processing often happens on the locally attached CPUs, but there will likely be a point where that pre-processing happens elsewhere.
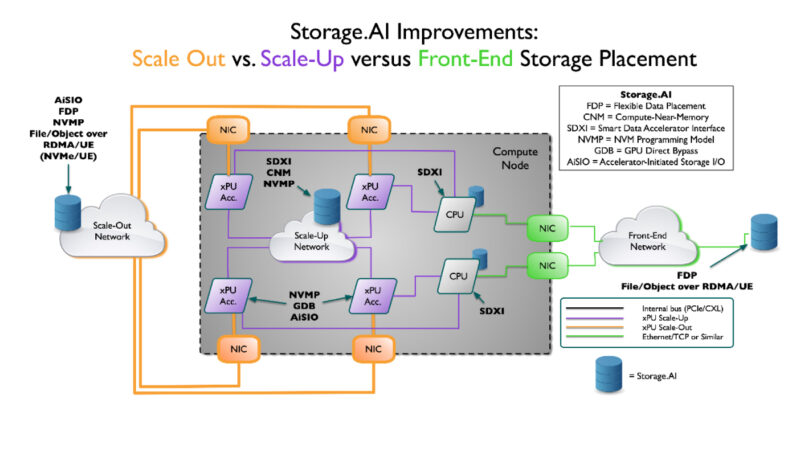
Here is a quick look at what SNIA says Storage.AI enables. Since it is a list format, we will let folks read through it:

One notable aspect our Chief Analyst Patrick Kennedy pointed out was that when he heard of this is that there will be a tension with network topologies. If more switch ports on the scale-out network are required for high-performance storage, then that will increase the tiers of switching required for large clusters. At some point, that trade-off may make sense, but it is something the industry is very sensitive to.
Final Words
So far, AMD, Cisco, DDN, Dell, IBM, Intel, KIOXIA, Microchip, Micron, NetApp, Pure Storage, Samsung, Seagate, Solidigm, and WEKA have signed on. Notably absent is NVIDIA, and perhaps Cerebras. NVIDIA is the big AI company. Cerebras has an interesting AI storage and movement requirement given its WSE design. Aside from hardware companies, we hope in future versions to see big AI customers sign on to help guide the project.



{kind=link}