
An absolutely killer feature of ZFS is the ability to add compression with little hassle. As we turn into 2018, there is an obvious new year’s resolution: use ZFS compression. Combined with sparse volumes (ZFS thin provisioning) this is a must-do option to get more performance and better disk space utilization. Many workloads work really well with ZFS compression. Overall, this is something we see far too many users overlook when it can be an enormous benefit.
How to find if you have ZFS compression enabled
For many ZFS environments, lz4 compression is the go-to solution. It is fast and gives a decent amount of benefit. Look at it as the minimal tradeoff to get substantial gains. While there are some ZFS environments that default to lz4 compression, most will not have compression enabled by default. We looked back on questions we received in 2017, and a common one was how to find if you have ZFS compression enabled.
There are many ways you can do this, but the easiest is with “zfs get compression.” Here is an example of using that command:

Along with “zfs get compression” another useful command is “zfs get compressratio” which shows the compression ratio. Note it is “compress” not “compression” ratio here. These are two attributes that you will see on zpools/ zvols. You can also see that we have the zvol’s (p3600R1/vm-203-disk-1) compression inherited from the zpool (p3600R1.) We suggest setting compression at the zpool ratio for general purpose storage and then alter explicitly from there.
ZFS has a lot of attribute information that you can use “zfs get all” to lookup. Here is an example:
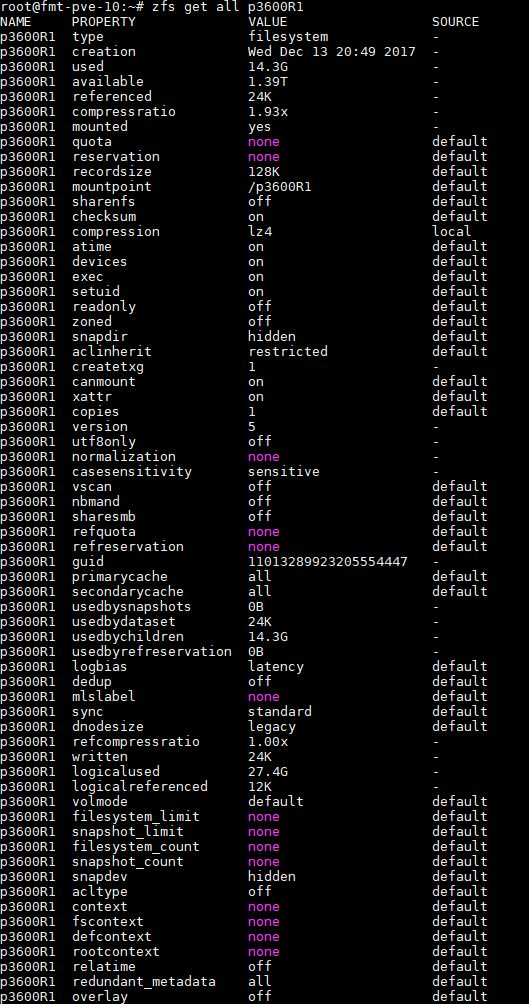
If you have zfs compression showing as “on”, and want to see if you are using lz4 already, then you can do a zpool get all and look for/ grep feature@lz4_compress which should be active if you are using lz4 as the default:
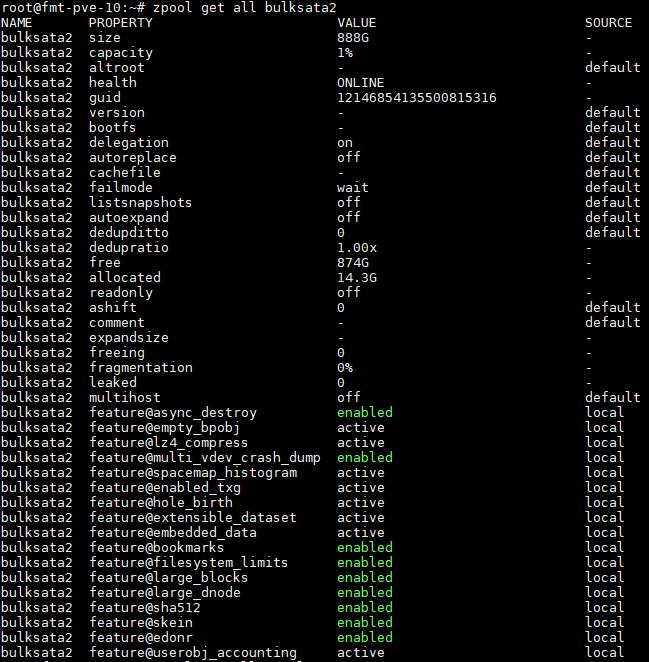
Either way, our resolution is to turn on zfs compression if at all possible.
How To Set ZFS Compression
We are going to suggest simply setting ZFS compression at the zpool level. That allows subsequent datasets to inherit compression making it easy to maintain. To set the compression to lz4, we can use “zfs set compression=lz4”. Here is an example:
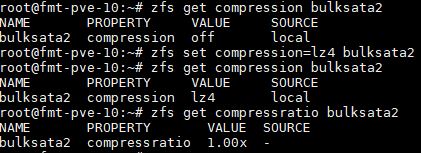
In the first zfs get compression command we see that compression is off by default. We use zfs set compression=lz4 on our zpool (bulksata2) to turn compression on. We then verify that the compression is now set to lz4.
You will notice that the compression ratio is 1.00x which is essentially nothing. That is simply because we have not copied any data to the new volume.
You can also use different algorithms such as gzip (e.g. gzip-7 that we are using in our next example.) If you have a pool that is for incremental backups on a dedicated backup server, going the gzip route can make a lot of sense to save space if you do not want to turn on deduplication.
ZFS Compression Impact
We took a 40GB Ubuntu 16.04.3 LTS VM volume (about 32GB of 40GB in-use) used for image caching and cloned a snapshot to “bulk storage”. For us, that means the source was on two Intel Optane 900p 280GB NVMe drives and the destination was two Samsung PM963 960GB SSDs. These SSDs were configured as ZFS mirrors. Given the size of the VM, we wanted to create a bottleneck at the destination while ensuring the source was many times faster than the destination.
First off, we wanted to see compression ratios. We know that compression=off gives us 1.00x compression since it is not compressed. Here is what we saw with the lz4 compressed pool:
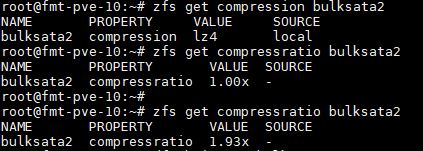
We got a 1.93x compression ratio with lz4 compression. That is good for near transparent performance. We took the exact same volume and used gzip-7 just to show the compression ratio difference:
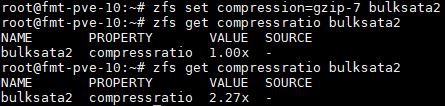
As you can see, we got a 2.27x compression ratio which is significantly better. We used gzip-7 since it is biased towards higher compression ratios versus lower levels offered by gzip that are faster.
There was a cost, however.
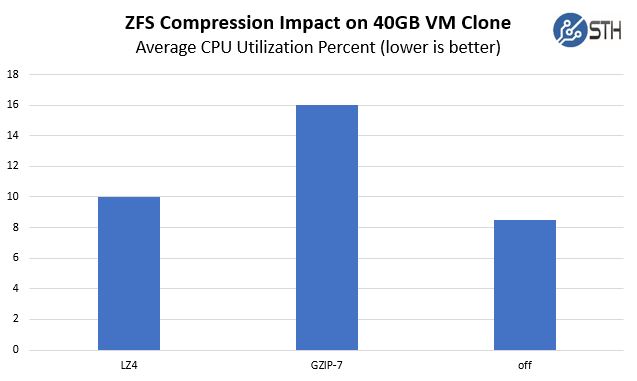
With lz4 compression, the entire snapshot clone operation (NVMe to SATA) took about 10% of the dual Intel Xeon E5-2698 V4 system’s CPU which was already running at 52% utilization. Using gzip-7 we saw utilization spike over 16% during the operation. As an additional data point, this copy with compression=off pushed utilization up 8-9%. Here are the incremental average CPU utilization of these three operations:
In terms of the actual clone performance, the timings were close but there was a noticeable difference between these three options:
Not only did lz4 use less CPU, but it did so over a shorter period of time.
We also were logging iowait while we were doing these operations. Since we were using a system with a ~52% base CPU load, which is more akin to a running virtualization server, we wanted to see what the impact was on iowait since that is usually a parameter we want to be minimized.
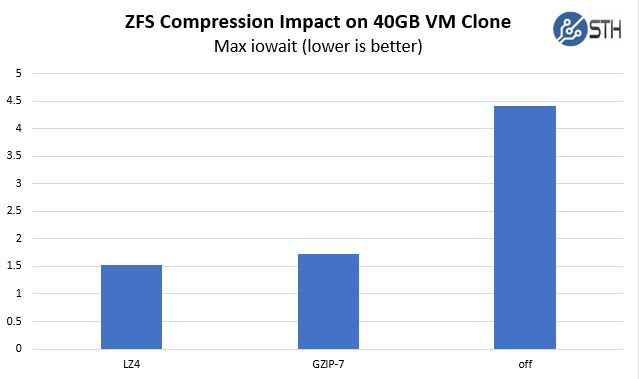
If you remember, we are doing this transfer from mirrored Intel Optane SSDs to mirrored Samsung SATA3 SSDs much as you would do if you were cloning development VMs to lower-cost storage. We were debugging the impact of that cloning operation at the system level which is why we were watching the iowait number. Through the ten runs we did, each time we had fairly consistent max iowait on a system which was near 0% on the system otherwise.
To some compression=off may seem like the obvious choice for the highest performance, it is not. While we would prefer to use gzip for better compression, lz4 provides “good enough” compression ratios at relatively lower performance impacts making it our current recommendation.
Final Words
If you are starting the year and looking for a project, ensure that your ZFS storage is using lz4 compression. The fact that lz4 is a good compromise between compression ratio and performance is well-known at this point. Using lz4 can provide both a performance and space-saving benefit during some operations which makes it a great choice.
Even though lz4 ZFS compression is a well-known solution, over the 2017 holiday season we logged into no less than half a dozen servers from other folks who were not using it on their zpools. Set compression=lz4 at the zpool level and allow data sets to inherit the compression. You will be happy for this new year’s resolution that takes a few seconds and has tangible benefits.
Test Configuration Notes
Here is a quick overview of the test configuration for the above. We are becoming ZFS on Linux fans so we are using ZFS 0.7.2 on Debian.
- System: Supermicro 2U Ultra
- CPUs: 2x Intel Xeon E5-2698 V4
- RAM: 256GB (8x 32GB) DDR4-2400 RDIMMS
- OS SSDs: ZFS Mirror Intel DC S3610 480GB
- Source SSD: ZFS Mirror Intel Optane 900p 280GB
- Destination SSDs: ZFS Mirror Samsung PM963 960GB
- Proxmox VE 5.1
- Based on Debian Stretch 9.2
- Kernel 4.13.3
- QEMU 2.9.1
- ZFS 0.7.2



{kind=link}
May be a dumb question, but what about performance for media servers with a lot of .mkv or .mp4 files? I always figured compression wouldn’t help much with just those files.
+Aaron it is not too bad if you’re using lz4. gzip with those isn’t good.
@aaron. I’ve got ~15TB of mkv files of >1GB (average 40-60GB). I’m running freenas and my dataset, with lz4 compression, says 1.00x, so extremely minimal.
It would be nice if you delve into the subjects a little deeper:
lz4 has an early abort mechanism that after having tried to compress x% or max-MB of a file will abort the operation and save the file uncompressed. This is why you can enable lz4 on a compressed media volume almost without performance hit.
Would love to see the same test running on a single epyc 7551p (with and without SMT) with the same hardware. We are planning on building a big freenas system (500 TB upto 1 PB usable space) and I don’t have to convince my manager anymore since I showed him the dropping intel stocks and rising AMD stocks.
EPYC 7551P is only € 2.250,- incl. vat where the E5-2698-v4 is € 3.875 2x = € 7.750.
For those € 5.500,- I can buy 3x crucial CT2K64G4LFQ4266 2×64 GB DDR4 2666 (3x€1.721=€5136) and some other gear.
Good info gentlemen, thanks! Seems that it’s worth enabling lz4 even for media shares just in case it encounters some files that can be compressed.
I am not sure if we are going to have a publishing spot for the results, but IIRC there was actually a difference with EPYC based on where the drives were located (e.g. which physical die they were mapped to.)
For this kind of “real world” snapshotting performance where there is a base load it is a bit harder to get consistent numbers from EPYC.
BEWARE! In some cases people turn on compression on the entire zpool, but when they create a new zfs filesystem, the filesystem is NOT compressed. Thus, I always turn on compression on the newly created filesystem for good measure.
Also, if you zfs send receive an filesystem from an uncompressed zpool, to a compressed zpool, then the sent filesystem will be uncompressed on the new zpool. So in that case, it is better to copy the data if you want compression.
Yeah in this day and age you’re almost always IO or memory bound rather than CPU bound, and even if it looks CPU bound it’s probably just that the CPU is having to wait around all day for memory latency and only looks busy, plus compression algorithms have improved so significantly in both software and hardware there’s almost never a good reason to be shuffling around uncompressed data. (Make sure to disable swapfile and enable ZRAM too if you’re stuck with one of these ridiculous 4 or 8 GB non-ECC DRAM type of machines that can’t be upgraded and have only flash memory or consumer-grade SSD for swap space)
That said, if all your files consist solely of long blocks of zeroes and pseudorandom data, such as already-compressed media files, archives, or encrypted files, you can still save yourself even that little bit of CPU time, and almost exactly the same amount of disk space with ZLE – run length encoding for zeroes which many other filesystems such as ext4, xfs, and apfs use by default these days.
The only typical reason I can think of off the top of my head that you would want to set compression=off is if you are doing heavy i/o on very sparse files, such as torrent downloads and virtual machine disk images, stored on magnetic spinning disks, because, in that case you pretty much need to preallocate the entire block of zeroes before filling them in or you’ll end up with a file fragmentation nightmare that absolutely wrecks your throughput in addition to your already-wrecked latency from using magnetic disks in the first place. Not nearly as much of an issue on SSDs though.
If your disks have data integrity issues, and you don’t care about losing said data, you just want to lose less of it, it would also help and at least ZFS would let you know when there was a failure unlike other filesystems which will happily give you back random corrupt data, but, in that case you probably should be more worried about replacing the disks before they fail entirely which is usually not too long after they start having such issues.
(It likely does try to account for the future filling in of ZLE encoded files by leaving some blank space but if the number of non-allocated zeroes exceeds the free space on the disk it will definitely happen because there’s nowhere else to put the data)
Actually i read you should always turn lz4 on for media files, unless you EXCLUSIVELY have relatively big files (> 100MB ?). Even if you have JPEG photos you’ll end up wasting space if you don’t, unless you reduce the recordsize from 128KB. While compressed datasets would compress unallocated chunks (so a 50KB file would use 64 KB), uncompressed datasets would not (so a 50Kb file would still use 128KB on disk).
Suppose you have a million JPEG files, averaging 10MB each, hence 10TB. If half the files waste on average 64KB, it’s 30 GiB wasted. It can become significant if the files a smaller. Am I wrong
Comments are closed.