NextSilicon Maverick-2
Shipping in 2025 is the Maverick-2 accelerator that the company says is already shipping to dozens of customers and is deployed at Sandia National Labs. That may seem trivial, but getting a US National Lab to adopt the chip helps the company with co-design, but also gets folks using the chip. Unlike big hyper-scale AI deployments, usually these labs are willing to use new architectures to get better performance per dollar.

The Maverick-2 comes in a single die and a dual die configuration. The TSMC 5nm 400W single die is designed for PCIe cards while the dual die 750W part is designed for OAM. That may seem trivial, but for a company like NextSilicon fitting into the OAM UBB ecosystem makes adoption much easier by speeding up system design and integration. The single die part gets 32 RISC-V control cores, 96GB of HBM3E memory, and a single 100GbE interconnect. The liquid-cooled OAM dual die gets 64 RISC-V control cores, 192GB of HBM3E memory and two 100GbE interfaces.
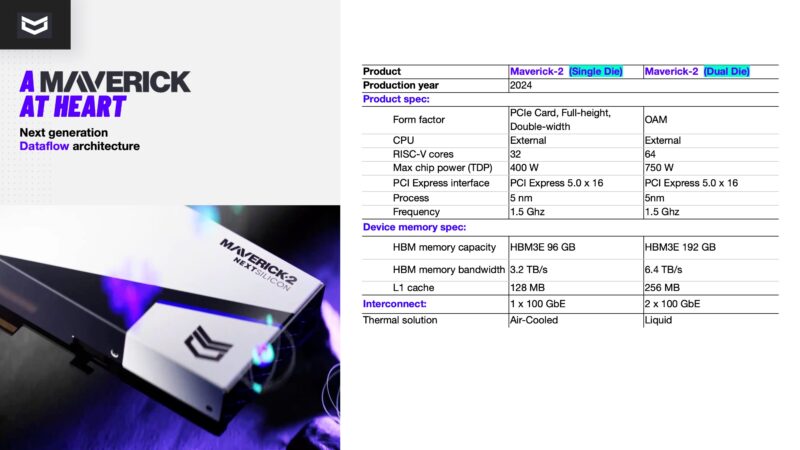
Those TDP figures are maximums and it is expected that in many workloads it will be less. NextSilicon says it can get 600GFLOPS in 750W on HPCG workloads which would be 4.8TFLOPS in 6kW for a single 8x accelerator UBB. Not really in here is that NextSilicon is focused on HPC, whereas NVIDIA is chasing the bigger AI markets. One cannot blame NVIDIA since there is a clear path to grow AI build-outs to an enormous market whereas HPC tends to be tougher. AMD is supporting HPC, but it too has pressure to focus on chips where the TAM is measured in $100B/ year chunks.

NextSilicon says that Maverick-2 is more efficient than CPUs or GPUs. Something you do not often see in HPC focused accelerator presentations is PageRank performance.
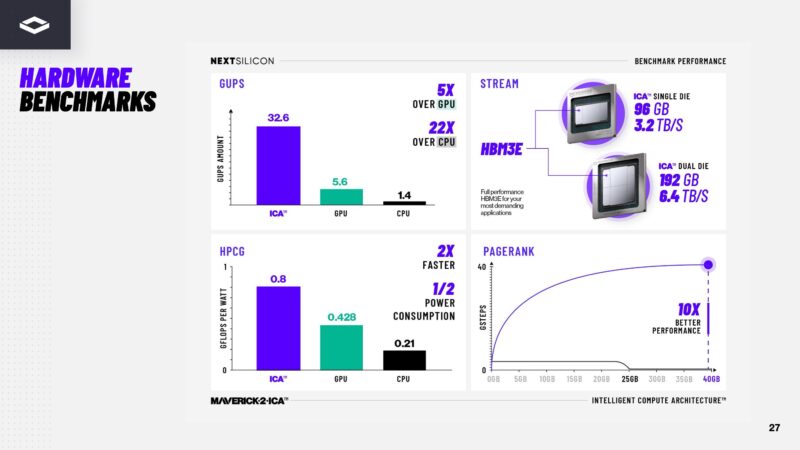
Our sense is that we will see more performance metrics at Supercomputing 2025 in a few weeks. In the meantime, NextSilicon also has Arbel, a RISC-V test chip for a host processor.
NextSilicon Arbel RISC-V Test Chip
Are you concerned with entrusting your compute to other large purveyors of instruction sets? If so, NextSilicon is exploring a RISC-V host processor.

While we have covered a number of RISC-V procesosrs before, the company says it has something that has core performance up to Zen 5 or Intel Lion Cove in terms of performance. That is pretty impressive as a project from a startup compared to teams at AMD and Intel who focus on this every day.

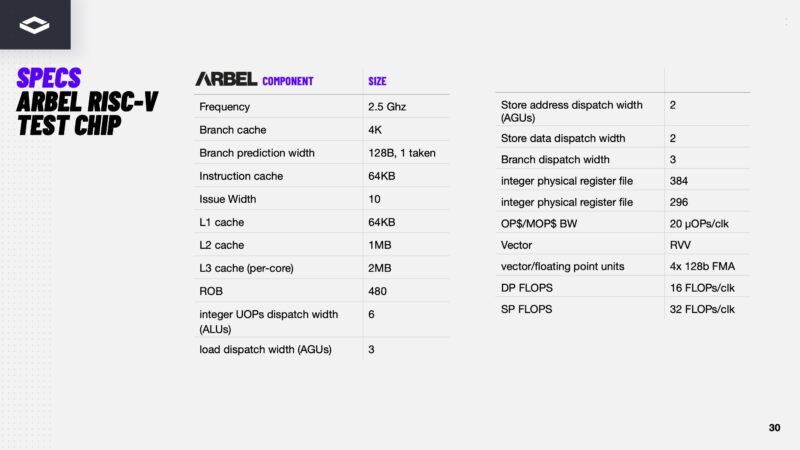
The key specs show that it is only running at 2.5GHz, which is good for power, but not the frequency of modern AMD and Intel CPUs. Here are the other specs of the chips that we will let you read through.
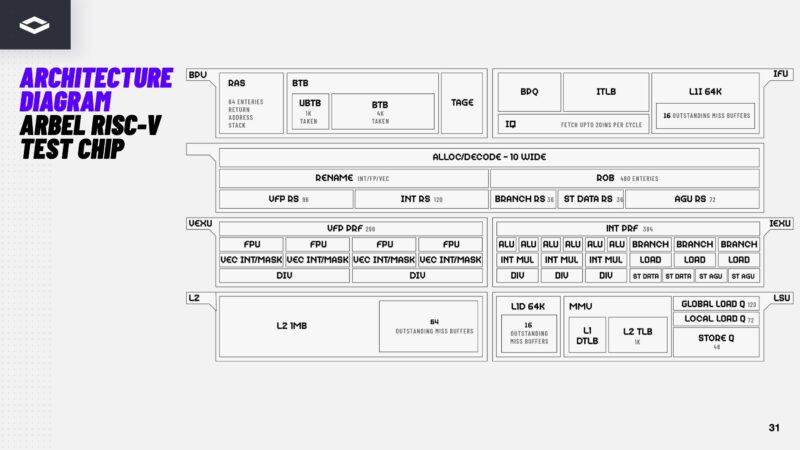
Here is the architecture diagram for the chip. Just to be clear, this is a CPU, not a dataflow processor.
RISC-V is gaining momentum, so we are starting to see more interest every year. Although folks commonly associate NVIDIA with Arm CPUs, the company is using RISC-V inside its architecture, as are many other companies. At some point, there is likely to be a market for larger RISC-V host CPUs.
Final Words
The NextSilicon Maverick-2 is not the only dataflow architecture chip on the market. On the other hand, its focus on the HPC market might give it a leg up. Other companies are trying to go head-to-head with NVIDIA and AMD in the AI market. For now, NextSilicon is focused on the HPC market that is growing, but not at the enormous rates needed to increase share prices for large GPU providers. That, along with its deployments versus a paper launch, give Maverick-2 a leg up on other competitors.
Editor’s Note: A quick thank you to John for stepping in on this one. I came down with a rough flu yesterday. I just wanted to quickly note here that as I travel around and talk to folks, NextSilicon is a company that has been gaining mindshare. We get pitched by accelerator startups every week, but this is a second generation product. I do not think that in 2026 Maverick-2 is going to outsell NVIDIA Blackwell and Rubin in the AI market. On the other hand, there seems to be a lot of buzz around Maverick-2.



{kind=link}
This reads like yet another “revolutionary” startup PR push for IPO cash-out.
The performance claims are simply insane, and worth nothing without independent verification. They also claim the ability to run unmodified C++, Python and *CUDA* code.
It’s highly unlikely that Arbel at 2.5GHz matches Zen 5 that clocks well over 5GHz in general performance. Maybe some specific micro-benchmark, but without knowing more about what they base their claims on it’s just noise.
Kyle, you seem very pessimistic. Custom software defined silicon is an awesome technology that will be great to watch advance. Like stated in the article these chips are beyond just “slideware” and have been in validation since 2022 with actual deployments now existing. While yes a lot of benchmark slides read like advertising slides (because a lot of time that is what they are) it is weird to read this great article and skip all of the great details over the function of these accelerators. STH is not calling on us to personally go out and fund this company they are instead disseminating information that would normally be harder to access, and understand without the helpful commentary.
@Rainey
I’m pessimistic because I’ve seen this MO time and time again. Since they supposedly have a US national laboratory evaluating the chip I’ll wait for a proper peer-reviewed paper that will vindicate their PR. Until then it’s just unsubstantiated claims.
We’ve seen the software-driven hardware performance claims before – Intel Itanium relied on magical compilers that never came for the massive theoretical performance increases. This seems to even claim that unmodified C++, Python, Fortran and CUDA can run on it. Each of those took decades to get right. CUDA compatibility is a red flag since both Intel and AMD abandoned their own compatibility efforts with ZLUDA due to legal issues.
There’s being optimistic and there’s being unrealistic. If these claims can be verified by trusted third parties then great, we have a solid contended to disrupt the market.
Dataflow can extract parallelism from algorithms without you having to code it. However, the patents are almost certainly worthless garbage because dataflow is nothing new. I worked at a startup trying to bring dataflow CPUs to the market over 20 years ago. They had full working CPUs implemented in an FPGA. I repeat: *EVERYTHING* I see in this has been done a *LONG* time ago so there will be prior art on it *ALL*.