
Meta is home to one of the largest deployments of artificial intelligence in the world today. Every day, billions of people on Meta platforms access AI-powered experiences ranging from personalized recommendations to AI assistants. The company has been designing its own custom silicon to cost-effectively power these experiences at a massive scale, which we have seen in some of our articles about earlier generations of Meta’s hardware. Now, Meta is releasing a new hardware roadmap outlining the hardware it has designed for future generations of MTIA AI acceleration.
The Meta MTIA Family Expands
We first covered Meta’s custom AI accelerator family MTIA back in 2024. Since then, the company has accelerated development across four successive generations: MTIA 300, 400, 450, and 500. These new chips have either already been deployed or are scheduled for deployment in over the next few years, expanding workload coverage from ranking and recommendation inference to training, general generative AI workloads, and inference with targeted optimizations.
Overall, Meta has been focusing their hardware design efforts on chips for inference, rather than making chips for large-scale training. This is a design aspect the company believes gives them an edge, as they are using hardware that is highly optimized for their specific needs rather than using training hardware for inference. The MTIA platform is built natively on industry-standard software ecosystems, including PyTorch, vLLM, Triton, and follows Open Compute Project standards for hardware.
In designing their hardware, one challenge that Meta faces is that AI models are evolving faster than traditional chip development cycles. By the time hardware reaches production, often two-plus years after design begins, those workloads may have shifted substantially. Consequently, Meta has taken an iterative approach where each MTIA generation builds on the last using modular chiplets, incorporating the latest AI workload insights and deploying on a shorter cadence.

With such a rapid pace of development, Meta is designing all of their accelerators around common building blocks. This is most notable at the compute level, which starts with the processing elements. Each processing element contains two RISC-V vector cores, a Dot Product Engine for matrix multiplication, a Special Function Unit for activations and elementwise operations, a Reduction Engine for accumulation and inter-PE communication, and a DMA engine for data movement.
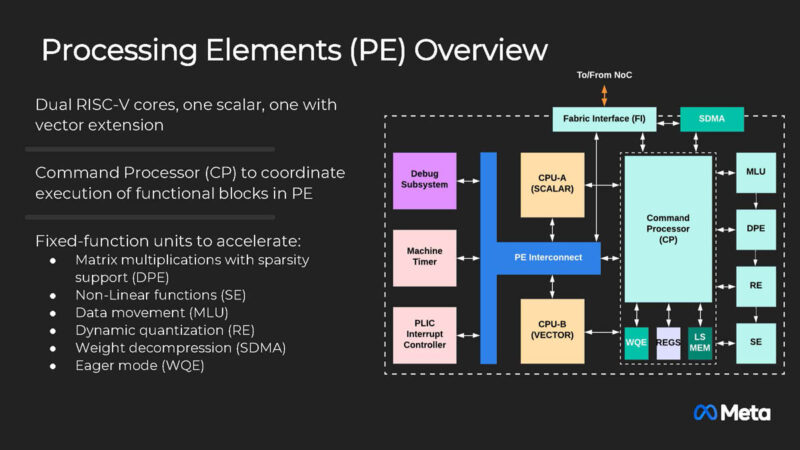
Getting into the specific accelerators that Meta is and will be using, already in the field is the MTIA 300. This accelerator was initially optimized for ranking and recommendation models, which were the dominant Meta workload before full-on generative AI took off. This chip established building blocks that became the foundation for subsequent chips optimized for generative AI models. It is currently in production for ranking and recommendation training.

As generative AI has surged, MTIA 300 will be succeeded by the MTIA 400 to better support generative AI models while maintaining capabilities for ranking and recommendation workloads. According to Meta,this is a massively more powerful chip overall, with over five times the compute performance and 50% more HBM memory bandwidth than the MTIA 300.

The accelerator also supports vastly larger scale-up domains – going from a 16 node limit on MTIA 300 to 72 nodes on MTIA 400 – helping the MTIA 400 deliver performance that is performance and cost-competitive with leading commercial products. Meta has finished testing MTIA 400 in its labs and is on the path to deploying it in data centers.

Looking beyond the MTIA 400 in further anticipation of the rise in generative AI inference demand, MTIA 400 will be followed by the MTIA 450, which will incorporate specific optimizations for inference. Since the bandwidth of high-bandwidth memory is the most important factor affecting generative AI inference performance, Meta doubled HBM bandwidth from MTIA 400 to 450, going from 9.2TB/sec per accelerator to 18.4TB/sec, giving it much more memory bandwidth than existing commercial products. Additionally, MTIA 450 will significantly improve support for and performance of low-precision data types, including some Meta custom data types. MTIA 450 is scheduled for mass deployment in early 2027.

The final accelerator on Meta’s new hardware roadmap is the MTIA 500, which continues their focus on generative AI inference. Compared to MTIA 450, MTIA 500 will increase HBM bandwidth by an additional 50 percent, bringing it to 27.6TB/sec, while HBM capacities will reach as high as 512GB per accelerator (if HBM development proceeds as expected). As well, MTIA will bring further “data-type innovations,” though Meta is not detailing what those are at this time.

More significantly from the chip-building side of matters, MTIA 500 will push Meta’s modular philosophy further by using a two-by-two configuration of smaller compute chiplets. Those chiplets will then be surrounded by several HBM stacks and network chiplets, along with an SoC chiplet that provides PCIe connectivity. MTIA 500 is scheduled for mass deployment in 2027.
Over the complete arc of Meta’s hardware roadmap, the path from MTIA 300 to MTIA 500 will see HBM bandwidth increase by four and a half times, and compute FLOPS increase by 25 times (accounting for lower precision data types). This kind of rapid advancement is exactly the reason that Meta has pursued its velocity strategy, allowing it to develop so many successive generations of more powerful and optimized chips in only a couple of years. And with Meta using a common rack/network infrastructure for the MTIA 400/450/500 parts, it will allow Meta to quickly swap out accelerators for newer chips as they become available.
Final Words
The evolution of the MTIA family demonstrates that there is more than one path forward in AI acceleration. While many companies focus on building the largest possible chip for training, Meta has found success with building inference chips while rapidly iterating on chip design. The use of RISC-V architecture and modular chiplet design shows innovation beyond traditional GPU approaches. With hundreds of thousands of MTIA chips already deployed in production, Meta is successfully using custom silicon to deliver both performance and cost efficiency at massive scale.



{kind=link}