Three Compute Express Link (CXL) Examples… Using Tacos and Limes
So let us get to tacos and limes, and why these use cases matter. This is going to be a very high-level look and is not perfect, but hopefully, this helps folks visualize some of the high-level concepts.
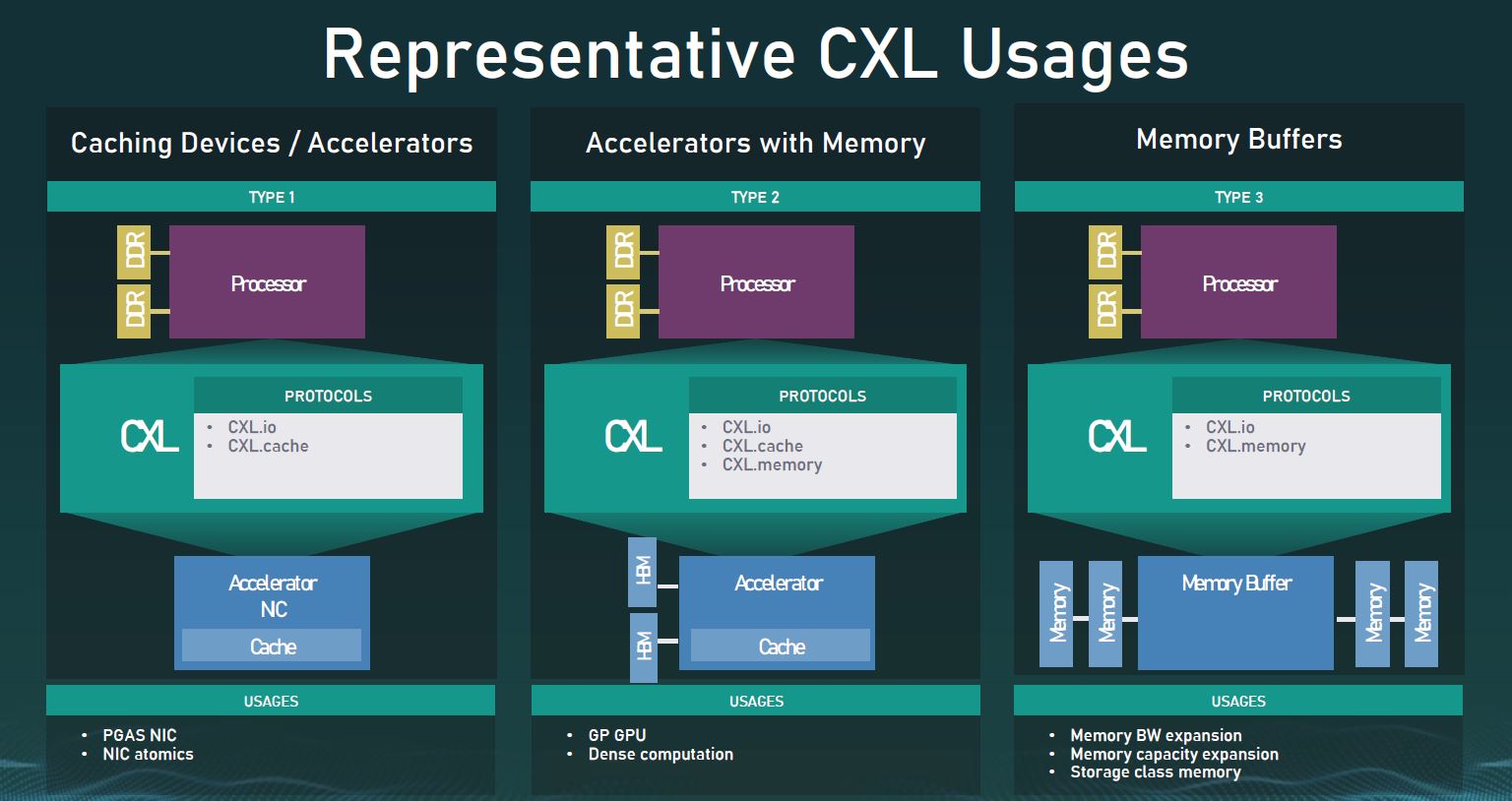
In our example, limes are going to represent memory. Main dishes are going to be represented by wonderful Rubio’s Blackened Mahi Mahi Tacos (also known as my dinner so it did not go to waste.) Accelerators are going to be represented by beverages.

In our first example, perhaps we received one lime on our two Rubio’s blackened Mahi Mahi tacos.

This is not uncommon. Most who have experienced Rubio’s tacos have had one “under-limed” event. Indeed, even the advertisements posted on store windows illustrate that this may happen showing one lime with three tacos.

This shows the resource inefficiencies with provisioning memory (limes.) Our first example though discusses one possible action. Perhaps today is not a lime taco day, but it is a lime beverage day. Here, we can access the lime juice (memory) from the host processors (tacos) and use it for our beverage. That is the idea behind CXL.cache and the Type 1 device example.

In our second example, our processors (tacos) came from Rubios with only one lime for two tacos. This is an example of where the host processor attached memory was insufficient. We can utilize the lime juice from the dish of limes in the center (CXL memory expansion module.) This is an example of CXL.mem and the Type 3 device.

In theory, especially once we get to CXL 2.0 with switching and pooling, the memory we access does not have to be DDR5. We could (again theoretically) have CXL devices that use SCM like Intel Optane, GDDR6X, or other technologies. Cost and demand will naturally impact availability but that is why this is so important.

In this use case, we can have multiple types of memory, attach them to a single system, and then access entire memory devices, or use portions of devices for different purposes. CXL 2.0 has a hot plug functionality that will help make this happen. Since we are already seeing devices come out for this use case, eventually we expect this will be important. It also allows more system memory capacity than traditional DIMM form factors allow.
In our third example, let us get a bit more crazy and assume we wanted to use limes from our beverages (accelerators like GPUs) on the tacos (processors) and some of the lime juice from our tacos for our beverages. This is an example of a Type-2 device.

Again, where things start to get really fun is that let us say that instead of our standard DDR5 memory limes, we wanted 3D XPoint/ Intel Optane persistent memory or storage class memory (SCM.) We can package that SCM media (lemons) into something that looks like what we used for limes, and now have access to a Type-3 device with lemons instead of limes or both a mix of lemons and limes. Instead of a GPU and a CPU each needing their own SCM, in the CXL 2.0 world both can access the SCM or even a large pool of connected memory.
While this is not a perfect example by any means, hopefully, the photo above helps show where this is going. Just like in virtualization, the ability for a GPU to access host system or Type-3 connected device memory means that we can have more efficient use of resources and system design. We do not need a GPU/ AI accelerator with Optane memory that is separate from what we have for the host CPUs. That would be cost-prohibitive and inflexible. CXL adds this flexibility to systems. CXL helps control costs while also adding flexibility to architectures which is analogous to what virtualization did for the industry years ago.
Future Enablement Example Beyond Simple Provisioning
Provisioning is important, as is efficient resource utilization, but let us go one step further and imagine how this changes architecture. Although they are less common in large-scale deployments today, many enterprises still use hardware RAID controllers.

Those generally operate with a few key components and functions:
- There is a SoC that controls data movement, parity calculations, caching, and storage/ retrieval.
- Onboard DRAM acts as a write cache and often a small read-cache.
- A battery/ capacitor FRU that allows write caches to happen in the onboard DRAM and flush safely even if power is lost.
- Flash storage for the onboard DRAM to flush to in the event of a power loss.
- Storage controllers to manage disks.
- SSDs either for primary storage or managed as cache devices attached to the RAID controller.
- Often those SSDs have their own power-loss protected write caches on each device.
Now imagine the future. DRAM-less NAND SSDs and hard drives are managed at a higher level. This can remove a few GB of NAND per SSD. Instead of the power-loss protection on the NAND SSDs and on the RAID controller, along with the flash to write that power-loss flush event data, we can use a CXL-based SCM such as Optane Persistent Memory and write directly to that device as the write cache for the system. A co-processor such as a DPU can then manage flushing that write cache from SCM to local or network storage. Cache instead of being a few GB on the RAID card could potentially be 1TB of host memory (although this is basically not needed since we have CXL) or CXL DDR5 and accessed directly by the host processor instead of going through the RAID controller.
This type of model makes it practical to start thinking about how to replace traditional storage arrays with higher-performance local resources in servers and using scale-out storage as a back-end. This will be absolutely transformational to the industry and is just one example that we have heard several companies working on. Normally the examples are of memory expanders and GPUs/ AI accelerators just for larger and more diverse pools of memory, so I wanted to give something that is a bit different to illustrate why CXL can be transformational. Other more straightforward examples usually use shelves of memory, compute, and accelerators that are composable based on what is needed for a given instance type.
Final Words
The key to CXL is simply that the rigid constraints of server architecture will start to go away as CXL is adopted. This is extremely important as servers continue to scale up since this requires more efficient resource utilization. In a few years, we will look back on today’s servers and view them as a legacy operating model much as we did dedicated servers for many applications after virtualization (and later containers.) For years, this concept has been discussed, but we are effectively less than a year from it being implemented in products beyond foundational elements such as Astera Labs Aries CXL Retimers.
Hopefully, this guide helped you learn a bit about what CXL is and what it is generally trying to accomplish. There is much more to CXL in terms of technical depth, but we wanted to ensure our readers have a base level of understanding. Tacos and Limes were not perfect, but we have been looking at the same diagrams for years and there are folks who still are not aware of CXL’s impact. We are talking about this in terms of early CXL in the PCIe Gen5 era, but there is a roadmap to PCIe Gen6 and beyond. We have already discussed a bit about how this model scales to a fabric such as Gen-Z to enable larger-scale deployments using a somewhat analogous solution.
We will, of course, have more on CXL in the future, but we wanted to provide this basic level-set around what CXL is.


{kind=link}
Business expensing tacos is the best.
Also, I’ll be curious what adoption of CXL looks like at the SMB level. Where as virtualization was a pretty easy sell, I’m not sure the consolidation/ flexibility will make sense without a fork-lift upgrade to an environment. I suppose it also depends on what hypervisor support looks like, too.
How do you see the adoption of CXL being shaped by latency concerns?
I can definitely see a lot of scenarios where having a nice standardized interface for assorted peripherals to either borrow main memory so they don’t have to ship with enough onboard for their worst-case scenarios; as well as the cases where being able to scavenge unused RAM from peripherals that have it, or other systems, when it would otherwise be idle is certainly useful (I assume that CXL also makes doing very large unified memory space clusters a relatively standardized configuration rather than something one of the small number of specialty supercomputer shops with custom fabrics can hook you up with); but I’m also thinking of all the situations where RAM gets placed on peripherals because the alternative is much worse performance(eg. GPUs currently have various ad-hoc arrangements for stealing main memory; but the ones that are actually any good have GDDR or HBM really close to the GPU on a very fast bus because that turns out to be a fairly major bottleneck otherwise; Intel’s attempts to tack a serial bus onto DIMMs to make trace routing less of a nightmare foundered on cost, power consumption; and latency issues; first-gen Epyc got a slightly frosty reception because of its NUMA peculiarities; the slightly crazy Cerebras guys found that putting multiple gigs of RAM on-die to be a good use of space; and back in common-and-affordable land Package-on-Package with RAM stacked on CPU seems to be very popular).
Given that, at contemporary speeds, latency quickly becomes a physics problem rather than just a memory controller deficiency(convenient rule of thumb is that at 1GHz, under ideal speed of light conditions, your signal can only travel 300mm per clock; if your medium is less than ideal, your implementation introduces delays, or your clock speeds are higher you can get substantially less distance per clock than that); it will simply be the case that CXL-accessed RAM has the potential to be anywhere between ‘not much worse than having to access RAM on the other CPU socket’ to ‘massive latency by DRAM standards’.
Is the expectation that, even with a cool relatively agnostic fabric to play with people will keep most of the RAM close to most of the compute; with some “it’s better than leaving it idle…” scavenging of idle RAM from more distant locations; or is there a sufficiently large class of applications where latency is either not a huge deal; or a small enough deal that spending way less on RAM makes it worthwhile to endure performance penalties?
Where is the tequila though?
> “Most of the early 2022 devices we will see will utilize CXL 1.1.”.
I think we can go directly to 2.0:
https://www.synopsys.com/designware-ip/interface-ip/cxl.html https://www.plda.com/products/xpresslink-controller-ip-cxl-2011
Hanging back at 1.0/1.1 is going to defeat early adoption, knowing that 2.0 is ready and PCIe 6.0 is dropping RSN.
Rob but Sapphire and Genoa are 1.1 aren’t they?
What about latency?
@QuinnN77 the best non-rumor information that I could find about Sapphire is that the CPU being tested is an engineering sample, with 4 cores running at 1.3 GHz and supports CXL 1.1. Less rumor is that Sapphire Rapids will support 1.1 in its final form, source: https://en.wikipedia.org/wiki/Sapphire_Rapids (amongst others, not for the weak of heart: https://www.techspot.com/news/89515-violent-delidding-reveals-intel-sapphire-rapids-cpus-could.html).
There’s no non-rumor info about Genoa and its supported CXL level.
CXL 2.0 adds switching capabilities, encryption, and support for persistent memory; so there’s a reason for both AMD and Intel to prefer it over CXL 1.1.
—
@Ekke, as for latency it’s above 100 ns with persistent memory, otherwise around 10 ms (plus). There are CXL 2.0 chipsets available for sampling to motherboard manufacturers, so it’s not as though everything isn’t ready and available.
Sources:
https://www.nextplatform.com/2021/02/03/pci-express-5-0-the-unintended-but-formidable-datacenter-interconnect/
https://www.anandtech.com/show/16227/compute-express-link-cxl-2-0-switching-pmem-security
https://www.microchip.com/pressreleasepage/microchip-leadership-data-center-connectivity-lowest-latency-pcie-5.0-cxl-2.0-retimers
I still think Optane/3DXP/QuantX has multiple uses and don’t want to see it die or become proprietary tech.
I can envisage Optane being used in a OMI like Serialized (Main Memory + Optane) DIMM on one PCB with DMA allowed between Optane + Main Memory, imagine how much faster and lower latency data transfer could be between the OS and RAM is the OS existed on Optane along with all the basic applications needed and transferred directly to the local RAM modules on the same DIMM.
The distance that needs to be traveled after getting the “Go Signal” from the CPU is much shorter than a M.2 drive located on the MoBo to RAM.
That could help improve performance signifcantly.
Same with RAID Controllers / HBA adapters.
Instead of using traditional low end ram, Optane can literally replace the DRAM cache or coexist with a small amount of DRAM cache on the controller cards and allow ALOT more Low Latency cache to whatever HDD or SSD is attached to the end of the controller.
Optane could also exist as a form of Low Latency “Game Drive” where the installation of the Game can be on a M.2 drive attached to the GPU directly and you BiFuricate the GPU to be 12x/4x with the GPU getting 12x while the Storage gets 4x.
Then you can have ultra low latency for DMA directly from the “Game Drive” to VRAM.
Good sharing..! if you are looking for gaming accessories then you should contact Flyingshiba online platform. Find everything about gaming accessories like cronusmax, cronuszen, strike pack Xbox and ps4 and much more here
Comments are closed.