
Kicking off this afternoon’s graphics track at Hot Chips 2025 is AMD. The company launched its RDNA 4 architecture and associated Radeon RX 9000 series video cards earlier this year, releasing two GPUs thus far.
As AMD is now well into this generation of Radeon GPUs, the company doesn’t necessarily have any grand revelations to make at this year’s Hot Chips conference. But they are still at the show to update the attendees on the RDNA 4 architecture, dropping a couple more details about it that weren’t covered during the initial launch.
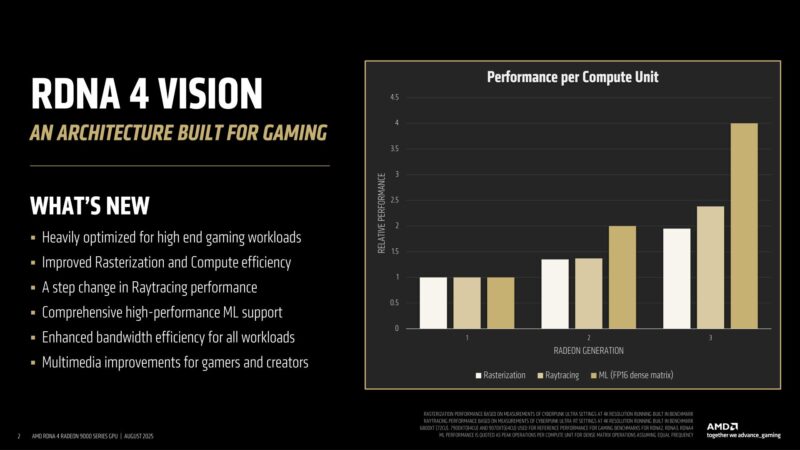
Quickly recapping AMD’s design goals with RDNA 4. This was a graphics (gaming) focused architecture, with major updates to both raytracing and machine learning (AI) hardware. AMD took a forward-looking view to architecture, aiming to address the graphics workloads of the future.
Other notable improvements: Compression, media & display engines.

Recapping AMD’s logical design, with a single GPU being made of (up to) multiple shader engines. The L2 cache was enlarged this generation to better prep the architecture for RT workloads. This also marks the 3rd generation of AMD’s Infinity Cache. All of which works to help keep the core fed.
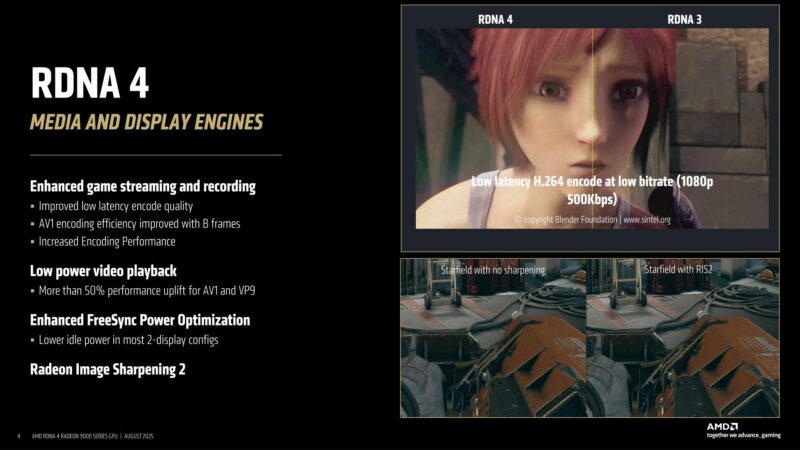
One of the major improvements in RDNA 4 is the media & display engines. AMD has two such media engines in the Navi 48 GPU. The media block received some major encoder updates, such as adding B-frames for AV1 encoding, and overall lower latency.
Meanwhile the display block adds some features such as integrating Radeon image sharpening 2 into the block itself, rather than processing it as a shader effect.
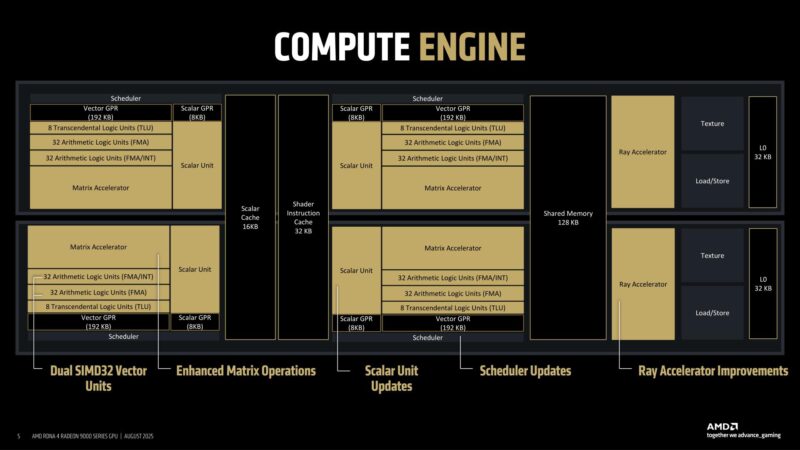
As for number crunching, things start in the compute engine. Of note, the scalar units have added floating point support. Not to mention significant ML (matrix) improvements (more on this later).
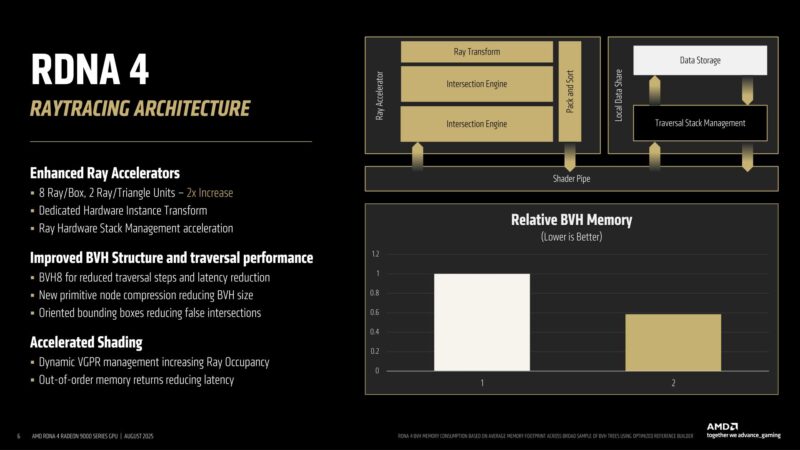
On the RT front, RDNA 4 doubles its ray intersection improvement. A dedicated hardware instance transformer has also been added, moving that task from a shader program.
The BVH structure was widened as well, moving from 4-wide to 8-wide. This goes hand-in-hand with the doubled intersection engines. And on the flip side, node compression to reduce the BVH size.
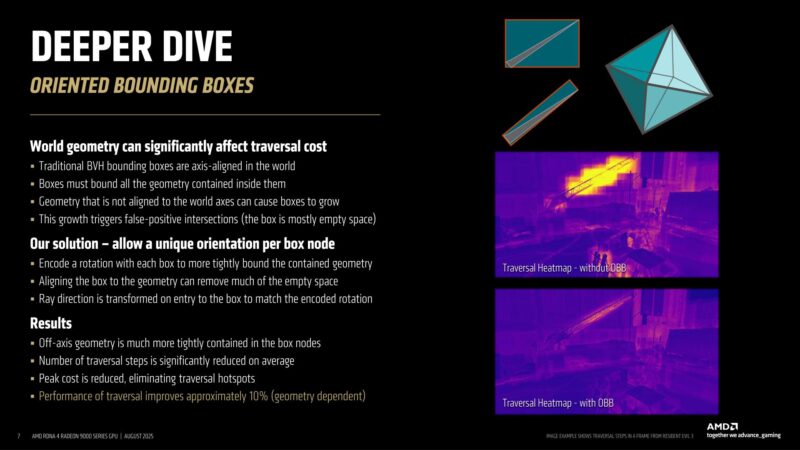
One new RT hardware feature is oriented bounding boxes: a solution to dealing with geometry that doesn’t align to the world axes, causing false-positive intersections.
In short: rotate bounding boxes to better match the world geometry.
The heatmaps above show how the reoriented bounding boxes, cutting down on false positives significantly.
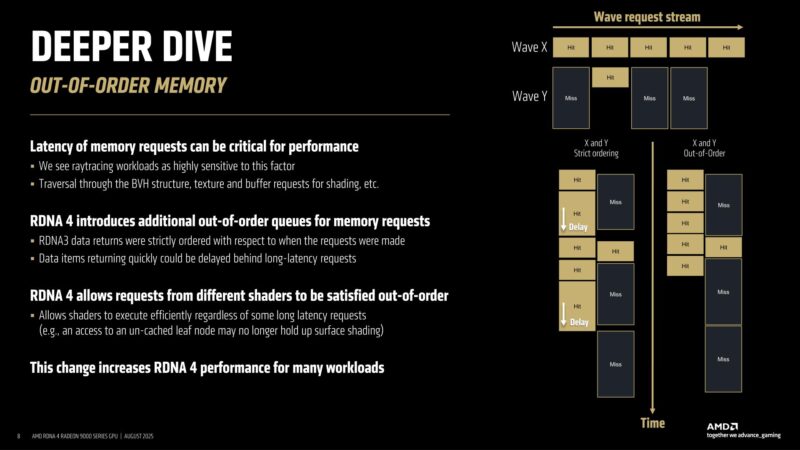
Out-of-order memory accesses are also a major performance component of raytracing, since RT is incredibly divergent.
Some requests – so long as they independent – can move ahead of other requests, breaking strict ordering. Like other forms of latency hiding, this helps to keep efficiency higher by getting execution-ready work queued up and executed without waiting on other, delayed work.

RT performance in a nutshell: doubling BVH throughput has added most of RDNA 4’s RT performance improvements. But OoO memory, hardware instance transform, and oriented bounding boxes all further add to that, allowing for ~2x RT performance versus RDNA 3.
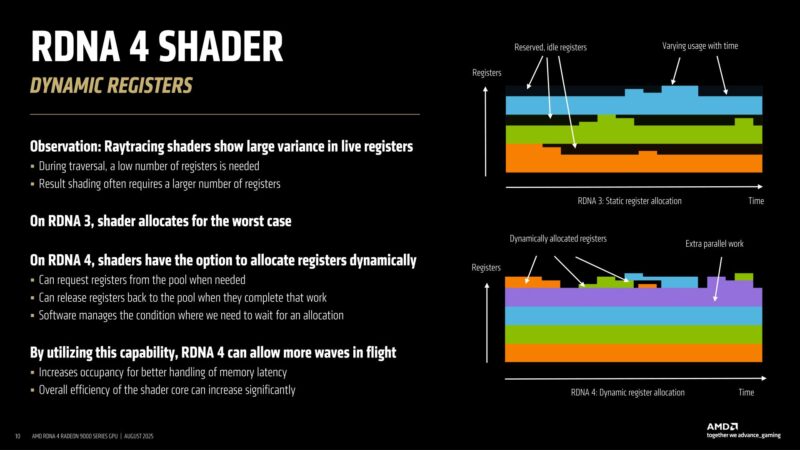
RDNA 4 also makes some updates to the shader engine with dynamic register allocations.
RT tends to eat up a lot of registers, but not during all stages of RT execution. Traversal uses relatively few registers, for example.
RDNA 3 would allocate registers based on the worst case scenario. RDNA 4, on the other hand, can allocate registers dynamically, allowing only the needed registers to be used, and then released once they’re no longer needed.
In practice, this has allowed AMD to increase the number of waves in flight versus RDNA 3, by squeezing in another wave to the freed-up registers.
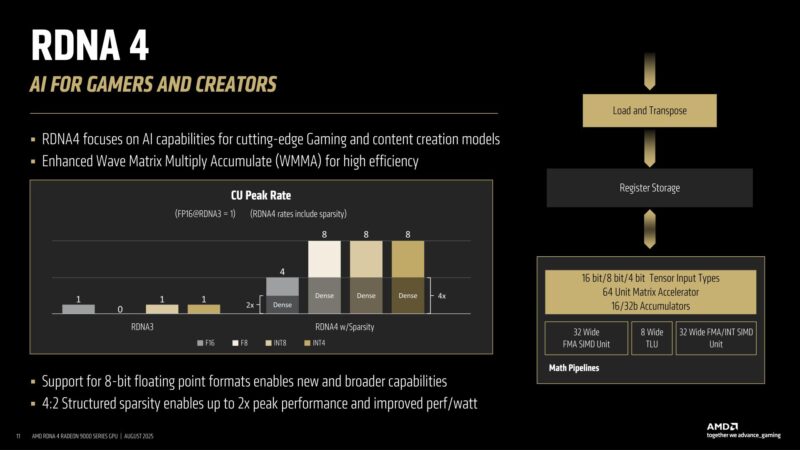
As for ML/AI workloads, RDNA 4 added FP8 capabilities, as well as structured sparsity.
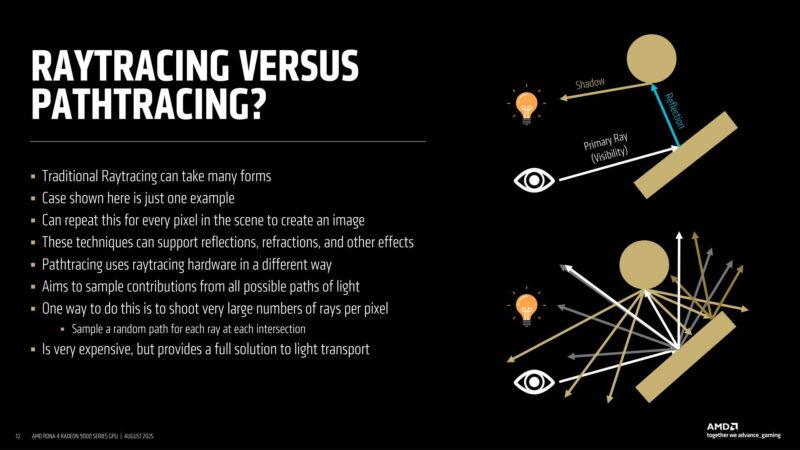

Path tracing produces better results, but it requires a massive number of rays. It’s too expensive to actually send out all the rays required. And this is where AI enters the picture, using a neural radiance cache, as well as neural supersampling and denoising to fill in the blanks that come from using too few rays.
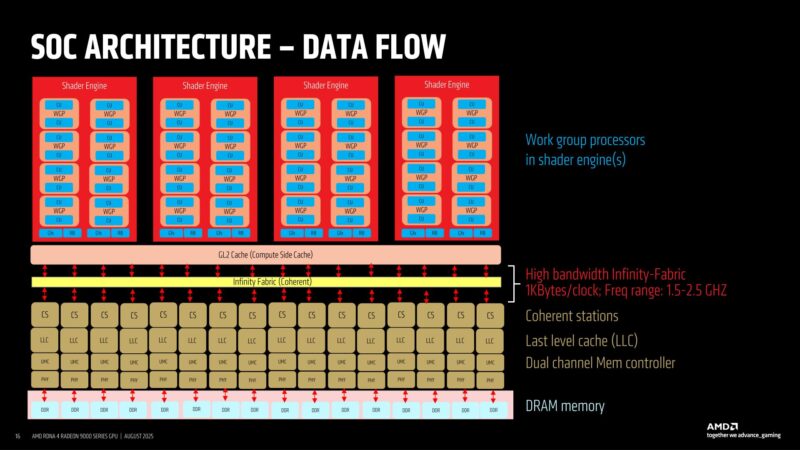
With a few minutes left to go, AMD is shifting gears from graphics to the GPUs’ SoC architecture. Specifically, illustrating how data flows between the shader engines and the various caches and memory controllers. There is up to 1KB/clock of bandwidth on the Infinity Fabric.
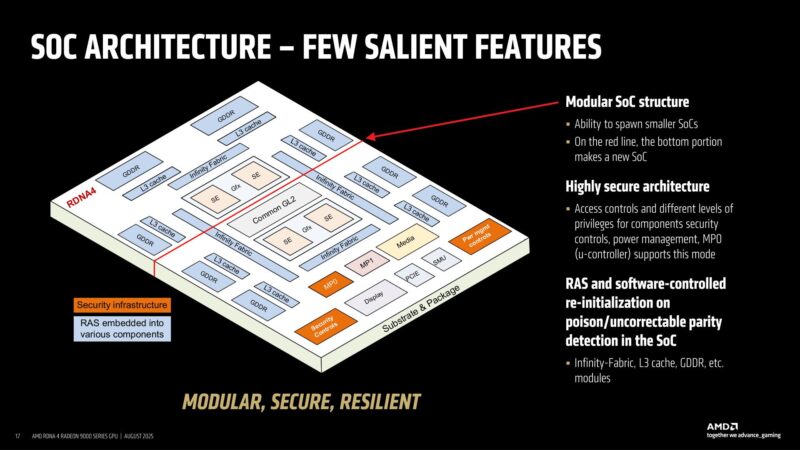
RDNA 4 is structurally modular. AMD designed Navi 48 in such a way that it can essentially be cut in half to make a smaller GPU, reducing the amount of work required to develop GPU variations.
This is also where RAS features come into play to improve reliability.
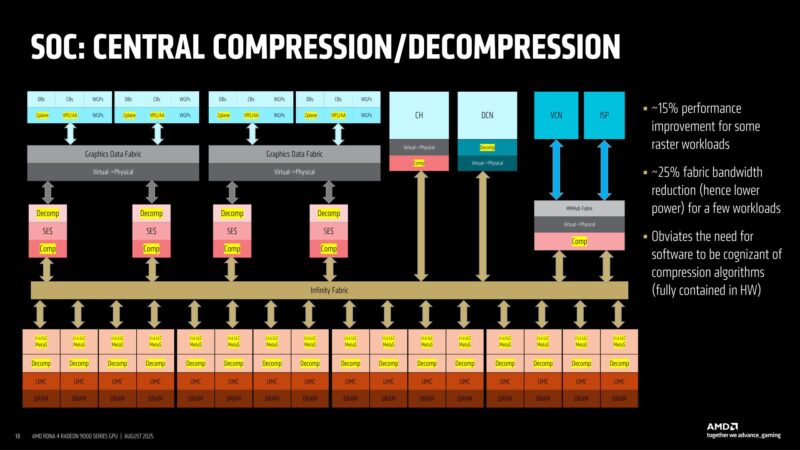
As mentioned previously, RDNA 4 has new memory compression/decompression features. This is entirely transparent to software; it is all handled in hardware. AMD has seen a ~25% reduction in fabric bandwidth usage.
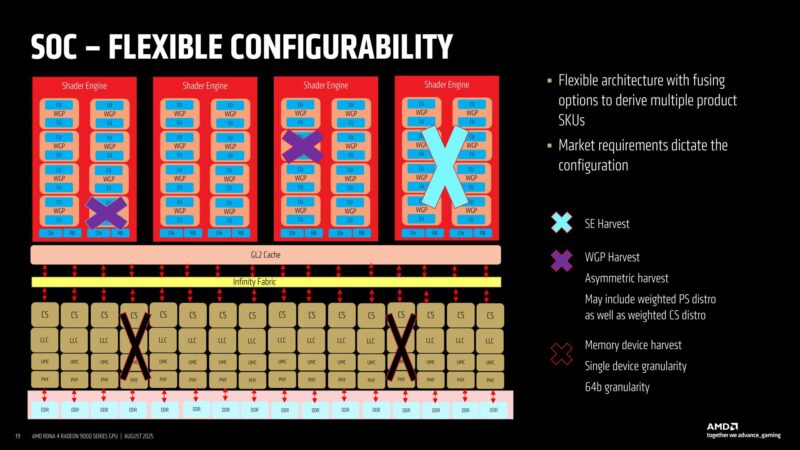
And all of this is flexible even within a single GPU, allowing for various blocks to be fused off for making new video card SKUs and for salvaging imperfect dies.

Wrapping things up, RDNA 4 is built for the next generation of gaming thanks to its raytracing and AI/ML capabilities.



{kind=link}